
Agê Barros on UnsplashPhoto by Agê Barros on Unsplash
Introduction
I am a Bangkit Academy 2023 Cloud Computing cohort. Near end of our journey as Bangkit Academy cohort, we are bound to finish a capstone project. Students across Cloud Computing, Mobile Development, and Machine Learning work together to build a software that expected could give positive impact on society. Our team consists of Saddam Sinatrya Jalu Mukti, Alfatih Aditya Susanto, Arizki Putra Rahman, Dimas Ichsanul Arifin, and Ramdhan Firdaus Amelia altogether to build scalable and cost effective application. In this article, we will discuss about the background of the capstone project, initial architecture, last minute issue, last minute architecture, and how the final architecture performs.
Background
We are planned to make a coffee leaf disease detection. Our initial idea was gather the dataset (of course), looking backward about the past research and what has been achieved on current product that aims to solve the problem, then we propose our initial software architecture that will become our development guideline during development phase. On machine learning side, we will use pre-trained model to detect the leaf, while mobile development side will utilize jetpack compose to build the mobile application.
Initial Architecture
Our proposed/initial architecture as follows:
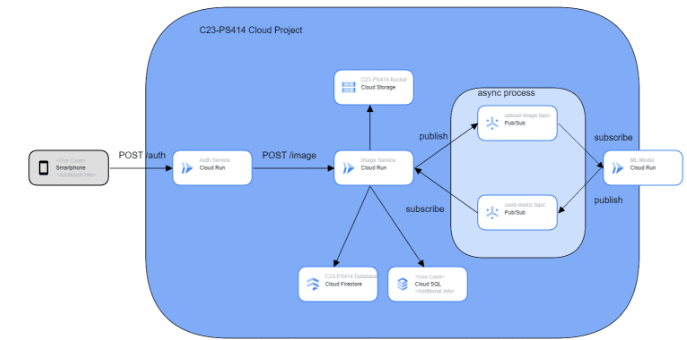
We planned to create 2 REST APIs that both of them deployed on Cloud Run, there are authentication service and image service. The authentication service is a mandatory requirement for this capstone project. The authentication service is responsible for authentication purposes such as register and login. The image service is an API that responsible for image data, such as uploading, fetching, and update the detection data from machine learning model to database.
We conduct a small research about how long the image classification task done with single data. It takes about 5 seconds to do the job. Since we do not want users to wait that long, we decided to use Cloud Pub/Sub in order to integrate image service with our machine learning. Cloud Pub/Sub enables the image service to communicate asynchronously with machine learning model, so image service does not need to wait for machine learning to finish the job. Both image service and machine learning model act as publisher and subscriber with their respective topics.
Last Minute Issue
Our planned architecture did not run well. Since our machine learning compatriots does not want to touch the deployment too much, we are facing issue when deploy machine learning model to Cloud Run. At that time, we still want to deploy the model to Cloud Run by integrating with Cloud Build by connecting to our machine learning repository, but we are having issue with Cloud Build quota. Why not integrate with Artifact Registry or Container Registry? since we are using TensorFlow it cause the image size humongous!. In short, our machine learning compatriots decided to deploy it to App Engine.
After the ML model has been deployed on App Engine, it is time to integrate image service with ML model. My initial approach is to test it with traditional HTTP request and it was successful attempt. Next, I want to integrate by utilize Cloud Pub/Sub with push subscription type.
There are 3 types of subscriptions in Cloud Pub/Sub, push, pull, and BigQuery subscripstion. We will cover push and pull scenario in this topic. In push scenario, the publisher should know the HTTP endpoint of the subscriber and the endpoint should only receive POST request. Meanwhile in pull scenario, the subscriber does not make request, instead the subscriber pull stream of messages actively from the topic.
The decision of using the push subscription is to minimize the ML compatriots effort from implementing the pull subscription type (since implementing ML model is time consuming tho). However, when I hit the endpoint, the logging from ML model/App Engine shows like this.
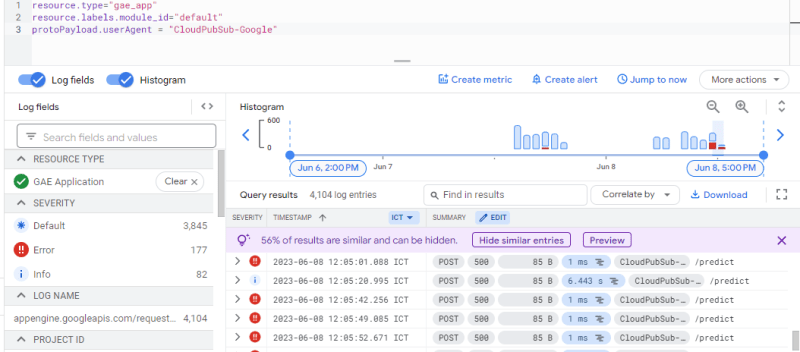
It return 500 HTTP status code. At this time, I was clueless why the ML model refuse the request. Turns out, when deliver message using push subscription, the Cloud Pub/Sub will store the message with given format:
{
"message": {
"attributes": {
"key": "value"
},
"data": "SGVsbG8gQ2xvdWQgUHViL1N1YiEgSGVyZSBpcyBteSBtZXNzYWdlIQ==",
"messageId": "2070443601311540",
"message_id": "2070443601311540",
"publishTime": "2021-02-26T19:13:55.749Z",
"publish_time": "2021-02-26T19:13:55.749Z"
},
"subscription": "projects/myproject/subscriptions/mysubscription"
}
The payload or data you want to send to your subscriber lies within data. The value of your payload has been decoded to base64 by Cloud Pub/Sub client. At this point, the ML model forced to change their data layer to match the current payload.
In short, everything goes well when invoking Cloud Pub/Sub from image service to ML model, but when image service has been deployed on Cloud Run the ML model refuse the message by returning 400 HTTP code.
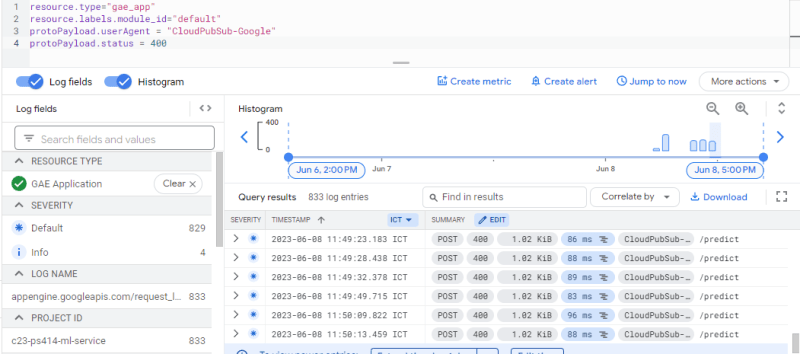
At this time, I am completely clueless what step should I take without changing our proposed/initial architecture.
Last Minute Architecture
After one or couple days of thinking and the deadline has near to its end, we should change our architecture in order to integrate our services and keep track on our goal to serve the prediction task asynchronously. Here is our last minute architecture.

Previously, we deploy our ML model to App Engine and use Cloud Pub/Sub with push subscription to integrate with image service. However, this approach does not work well.
On our last minute architecture, we move our ML model to Cloud Function. The trigger is whenever there are successful write dat attempt to Firestore, the ML model will retrieve the data to perform the prediction task. With this approach, everything goes well and our user does not need to wait for up to 5 seconds on their screen! :)
Architecture Performance
There are 2 performance that we could provide on this architecture: cost and latency. For cost, we expect the application to serve certain tasks that can be found here. Here is the result for the latency from image service and time execution from ML model.
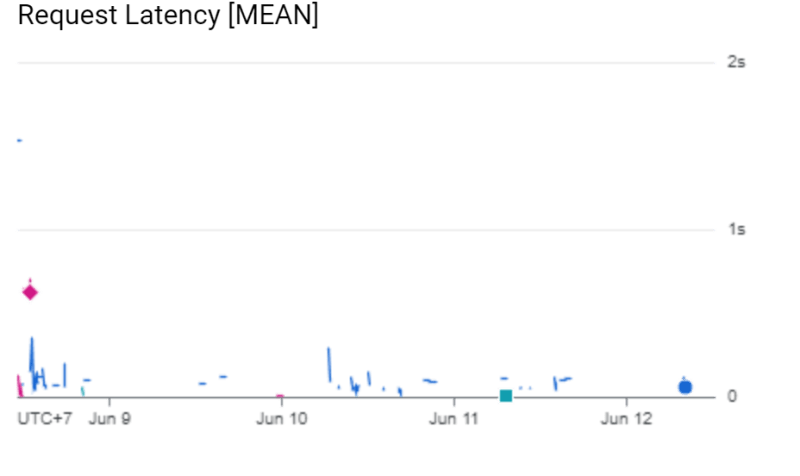
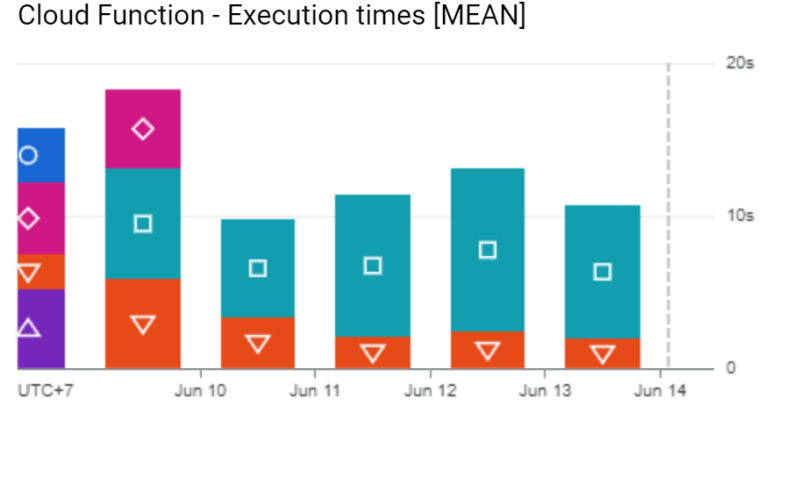
With our last minute architecture, the image service able to serve the requests under 1 seconds. Meanwhile on the ML model (coded with square with blue-green-ish background), there are few certain spikes when serving the request. This due the model should load the .H5 file/model file from Cloud Storage. The load process might executed once. After certain time window without incoming request, the ML model will be shutdown and whenever there is incoming request, the ML model will repeat the step.





Top comments (0)