
Most, if not all modern operating systems support multiprocessing and at the same time processes can be run in multiple threads hence the word multithreading.
This will give you a significant increase in performance and scalability but it comes with a price. The overall complexity of the code increases and it becomes difficult to debug.

In this article, we will take a look at POSIX Threads and learn how they work under the hood on Linux.
What are threads?
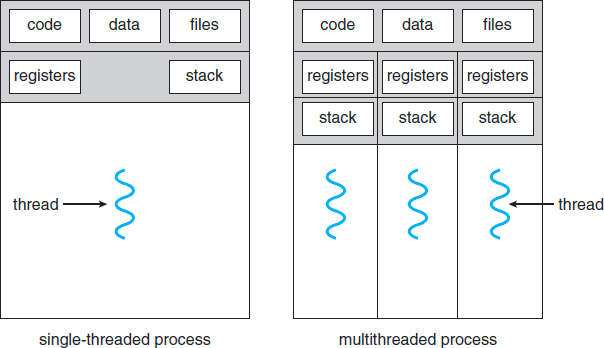
Difference between single-threaded process and multithreaded process.
When you open up a program on your computer, a process (instance) of the program gets created.
A thread is simply a unit of execution within a process.
So if your program is single-threaded that means that the process has one thread (this is usually called the main thread).
On the other hand, if your program utilizes multiple threads this means that your program is multitasking, meaning that it's running computations concurrently hence speeding up the program.
This is the high-level definition of threads, let's take a slightly deeper look into how threads are stored in memory.
Thread Control Block

Information about threads must be saved in memory, but how would it be represented?
Good question.
Threads are represented by Thread Control Block (TCBs).
It contains information such as:
- Thread ID – A unique identifier that gets generated by the operating system when a thread gets created.
- Thread States – State of the thread that changes as the thread progresses throughout the system.
- CPU information – This includes everything that the OS needs to know about the thread such as Program Count and Register Contents.
- Thread Priority – It indicates the weight (or priority) of the thread over other threads which helps the thread scheduler to determine which thread should be selected next from the READY queue.
- Process Pointer – A pointer to the process that started this thread.
- Thread Pointer(s) – A pointer or list of pointers to other threads that were created by the current thread. Now that we know
Now that we know how threads are stored, let's look at how do they increase performance.
How do multiple threads speed up my code?
Let's take a web server as an example.
If the server created a separate process for every HTTP request, we would wait forever for our page to load. The reason is that creating a new process is an expensive procedure for the operating system.
Instead of creating a new process, it would be more efficient to create a new thread.
But sometimes this wouldn't speed up your application.
If your lacking program uses a lot of computing power, then utilizing multiple processes would be more beneficial.
On the other hand, if your facing an Input-Ouput (IO) problem, then multithreading will help you.
Next, let's look at different types of threads and their relationships to each other.
Thread Types

There are two types of threads:
- User Threads
- Kernel Threads
Supporting threads at the user level means that there is a user-level library that is linked with the process and this library provides all the management and runtime support for the thread.
Kernel threads are managed by the operating system (OS), meaning that the OS kernel itself is multithreaded.
The OS kernel maintains things such as:
- Thread Abstraction – It abstracts the use of threads by having a thread data structure such as Thread Control Block.
- Scheduling and Synchronization
Next, let's discuss several mechanisms how user-level threads can be mapped to the underlying kernel-level threads.
Thread Mapping
One to Many Model

In this model, several user threads are mapped to one OS kernel thread. All thread management is handled by a custom user library, and this is the advantage of this approach. The disadvantage is that if one single thread makes a blocking call, then the entire process is slowed down.
One to One Model

This is the simplest model, in which each thread created in some process is directly controlled by the OS kernel scheduler and mapped to a single thread in kernel mode. To prevent the application from creating threads uncontrollably hence overloading the OS, they introduce a limit on the maximum number of threads supported in the OS.
Many to Many Model
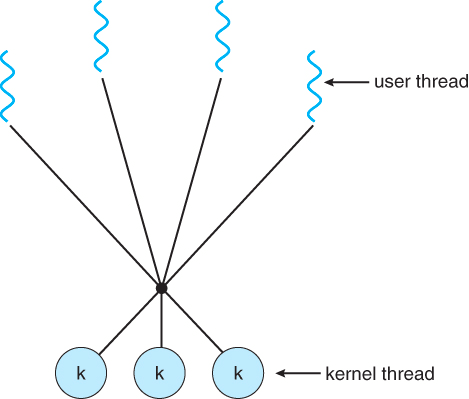
With this approach, many user threads are multiplexed into the same or fewer than N (number) of kernel threads. The negative effects of the other two models are overcome: the threads are truly executed in parallel and there is no need for the OS to impose restrictions on their total number. However, this model is quite difficult to implement from a programming point of view.
Conclusion
Multithreading can significantly speed up your code if used right.
But it's not all sunshine and rainbows, so it's up to you as the developer to figure out whether its worth implementing or not.
I hope you learned something today and in our next article, we will cover how to implement multithreading in C/C++.
Thanks for reading.





Top comments (0)