The interview question of the week for this week on Cassidoo’s weekly newsletter is,
Write a function that takes in a string of valid JSON and converts it to an object (or whatever your chosen language uses, dicts, maps, etc).Example input:
fakeParseJSON('{ "data": { "fish": "cake", "array": [1,2,3], "children": [{ "something": "else" }, { "candy": "cane" }, { "sponge": "bob" }] } } ')
At one point, I was tempted to just to write:
const fakeParseJSON = JSON.parse;
But, I thought, I’ve written quite a few articles about AST:
- Creating custom JavaScript syntax with Babel
- Step-by-step guide for writing a custom babel transformation
- Manipulating AST with JavaScript
which covers the overview of the compiler pipeline, as well as how to manipulate AST, but I haven’t covered much on how to implement a parser.
That’s because, implementing a JavaScript compiler in an article is a task too daunting for me.
Well, fret not. JSON is also a language. It has its own grammar, which you can refer from the specifications. The knowledge and technique you need to write a JSON parser is transferrable to writing a JS parser.
So, let’s start writing a JSON parser!
Understand the grammar
If you look at the specification page, there’s 2 diagrams:
- The syntax diagram (or railroad diagram) on the left,
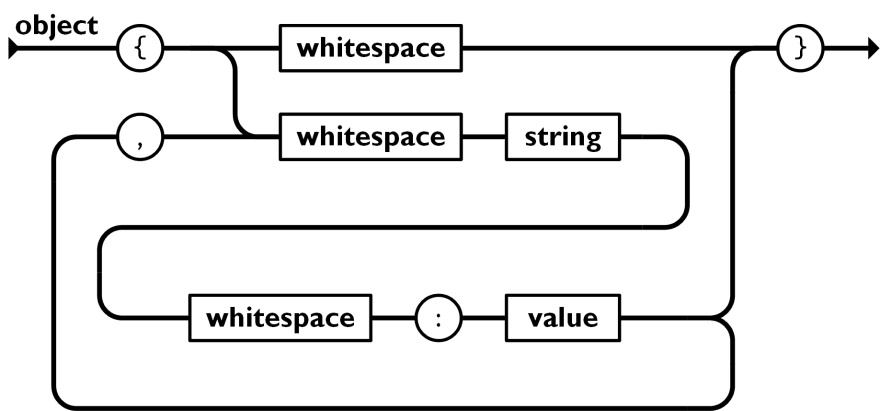 Image source: https://www.json.org/img/object.png
Image source: https://www.json.org/img/object.png
- The McKeeman Form, a variant of Backus-Naur Form (BNF), on the right
json
element
value
object
array
string
number
"true"
"false"
"null"
object
'{' ws '}'
'{' members '}'
Both diagrams are equivalent.
One is visual and one is text based. The text based grammar syntax, Backus-Naur Form, is usually fed to another parser that parse this grammar and generate a parser for it. Speaking of parser-ception! 🤯
In this article, we will focus on the railroad diagram, because it is visual and seemed to be more friendly to me.
Lets’ look at the first railroad diagram:
Image source: https://www.json.org/img/object.png
So this is the grammar for “object” in JSON.
We start from the left, following the arrow, and then we end at the right.
The circles, eg {, ,, :, }, are the characters, and the boxes eg: whitespace, string, and value is a placeholder for another grammar. So to parse the “whitespace”, we will need to look at the grammar for “whitepsace”.
So, starting from the left, for an object, the first character has to be an open curly bracket, {. and then we have 2 options from here:
-
whitespace→}→ end, or -
whitespace→string→whitespace→:→value→}→ end
Of course, when you reach “value”, you can choose to go to:
- →
}→ end, or - →
,→whitespace→ … → value
and you can keep looping, until you decide to go to:
- →
}→ end.
So, I guess we are now acquainted with the railroad diagram, let’s carry on to the next section.
Implementing the parser
Let’s start with the following structure:
function fakeParseJSON(str) {
let i = 0;
// TODO
}
We initialise i as the index for the current character, we will end as soon as i reaches the end of the str.
Let’s implement the grammar for the “object”:
function fakeParseJSON(str) {
let i = 0;
function parseObject() {
if (str[i] === '{') {
i++;
skipWhitespace();
// if it is not '}',
// we take the path of string -> whitespace -> ':' -> value -> ...
while (str[i] !== '}') {
const key = parseString();
skipWhitespace();
eatColon();
const value = parseValue();
}
}
}
}
In the parseObject, we will call parse of other grammars, like “string” and “whitespace”, when we implement them, everything will work 🤞.
One thing that I forgot to add is the comma, ,. The , only appears before we start the second loop of whitespace → string → whitespace → : → …
Based on that, we add the following lines:
function fakeParseJSON(str) {
let i = 0;
function parseObject() {
if (str[i] === '{') {
i++;
skipWhitespace();
let initial = true; // if it is not '}',
// we take the path of string -> whitespace -> ':' -> value -> ...
while (str[i] !== '}') {
if (!initial) { eatComma(); skipWhitespace(); } const key = parseString();
skipWhitespace();
eatColon();
const value = parseValue();
initial = false; }
// move to the next character of '}'
i++;
}
}
}
Some naming convention:
- We call
parseSomething, when we parse the code based on grammar and use the return value - We call
eatSomething, when we expect the character(s) to be there, but we are not using the character(s) - We call
skipSomething, when we are okay if the character(s) is not there.
Let’s implement the eatComma and eatColon:
function fakeParseJSON(str) {
// ...
function eatComma() {
if (str[i] !== ',') {
throw new Error('Expected ",".');
}
i++;
}
function eatColon() {
if (str[i] !== ':') {
throw new Error('Expected ":".');
}
i++;
}
}
So we have finished implemented the parseObject grammar, but what is the return value from this parse function?
Well, we need to return a JavaScript object:
function fakeParseJSON(str) {
let i = 0;
function parseObject() {
if (str[i] === '{') {
i++;
skipWhitespace();
const result = {};
let initial = true;
// if it is not '}',
// we take the path of string -> whitespace -> ':' -> value -> ...
while (str[i] !== '}') {
if (!initial) {
eatComma();
skipWhitespace();
}
const key = parseString();
skipWhitespace();
eatColon();
const value = parseValue();
result[key] = value; initial = false;
}
// move to the next character of '}'
i++;
return result; }
}
}
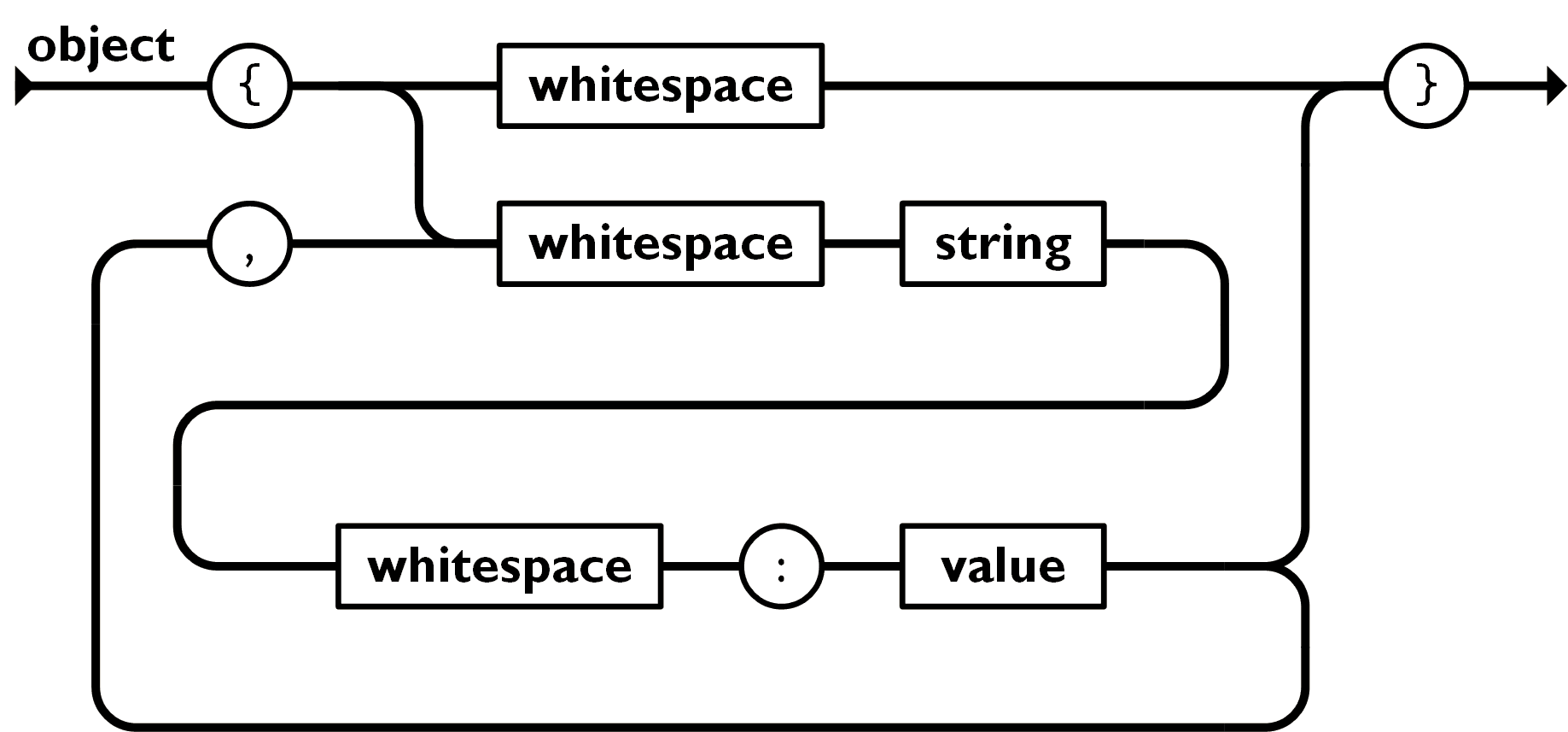
Now that you’ve seen me implementing the “object” grammar, it’s time for you to try out the “array” grammar:
 Image source: https://www.json.org/img/array.png
Image source: https://www.json.org/img/array.png
function fakeParseJSON(str) {
// ...
function parseArray() {
if (str[i] === '[') {
i++;
skipWhitespace();
const result = [];
let initial = true;
while (str[i] !== ']') {
if (!initial) {
eatComma();
}
const value = parseValue();
result.push(value);
initial = false;
}
// move to the next character of ']'
i++;
return result;
}
}
}
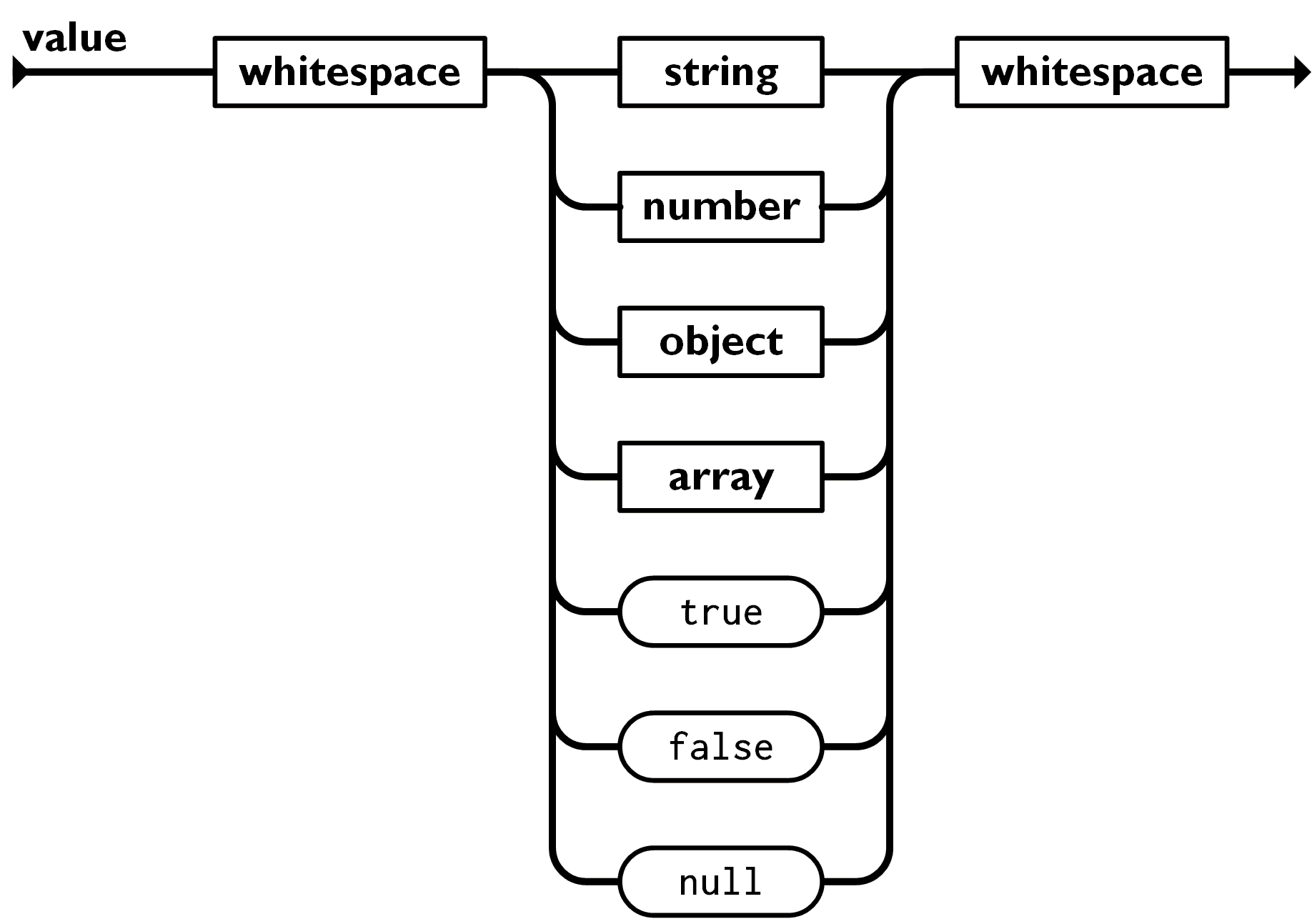
Now, move on to a more interesting grammar, “value”:
 Image source: https://www.json.org/img/value.png
Image source: https://www.json.org/img/value.png
A value starts with “whitespace”, then any of the following: “string”, “number”, “object”, “array”, “true”, “false” or “null”, and then end with a “whitespace”:
function fakeParseJSON(str) {
// ...
function parseValue() {
skipWhitespace();
const value =
parseString() ??
parseNumber() ??
parseObject() ??
parseArray() ??
parseKeyword('true', true) ??
parseKeyword('false', false) ??
parseKeyword('null', null);
skipWhitespace();
return value;
}
}
The ?? is called the nullish coalescing operator, it is like the || that we used to use for defaulting a value foo || default, except that || will return the default as long as foo is falsy, whereas the nullish coalescing operator will only return default when foo is either null or undefined.
The parseKeyword will check whether the current str.slice(i) matches the keyword string, if so, it will return the keyword value:
function fakeParseJSON(str) {
// ...
function parseKeyword(name, value) {
if (str.slice(i, i + name.length) === name) {
i += name.length;
return value;
}
}
}
That’s it for parseValue!
We still have 3 more grammars to go, but I will save the length of this article, and implement them in the following CodeSandbox:
After we have finished implementing all the grammars, now let’s return the value of the json, which is return by the parseValue:
function fakeParseJSON(str) {
let i = 0;
return parseValue();
// ...
}
That’s it!
Well, not so fast my friend, we’ve just finished the happy path, what about unhappy path?
Handling the unexpected input
As a good developer, we need to handle the unhappy path gracefully as well. For a parser, that means shouting at the developer with appropriate error message.
Let’s handle the 2 most common error cases:
- Unexpected token
- Unexpected end of string
Unexpected token
Unexpected end of string
In all the while loops, for example the while loop in parseObject:
function fakeParseJSON(str) {
// ...
function parseObject() {
// ...
while(str[i] !== '}') {
We need to make sure that we don’t access the character beyond the length of the string. This happens when the string ended unexpectedly, while we are still waiting for a closing character, ”}” in this example:
function fakeParseJSON(str) {
// ...
function parseObject() {
// ...
while (i < str.length && str[i] !== '}') { // ...
}
checkUnexpectedEndOfInput();
// move to the next character of '}'
i++;
return result;
}
}
Going the extra mile
Do you remember the time you were a junior developer, every time when you encounter Syntax error with cryptic messages, you are completely clueless of what went wrong?
Now you are more experienced, it is time to stop this virtuous cycle and stop yelling
Unexpected token "a"
and leave the user staring at the screen confounded.
There’s a lot of better ways of handling error messages than yelling, here are some points you can consider adding to your parser:
Error code and standard error message
This is useful as a standard keyword for user to Google for help.
// instead of
Unexpected token "a"
Unexpected end of input
// show
JSON_ERROR_001 Unexpected token "a"
JSON_ERROR_002 Unexpected end of input
A better view of what went wrong
Parser like Babel, will show you a code frame, a snippet of your code with underline, arrow or highlighting of what went wrong
// instead of
Unexpected token "a" at position 5
// show
{ "b"a
^
JSON_ERROR_001 Unexpected token "a"
An example on how you can print out the code snippet:
function fakeParseJSON(str) {
// ...
function printCodeSnippet() {
const from = Math.max(0, i - 10);
const trimmed = from > 0;
const padding = (trimmed ? 3 : 0) + (i - from);
const snippet = [
(trimmed ? '...' : '') + str.slice(from, i + 1),
' '.repeat(padding) + '^',
' '.repeat(padding) + message,
].join('\n');
console.log(snippet);
}
}
Suggestions for error recovery
If possible, explain what went wrong and give suggestions on how to fix them
// instead of
Unexpected token "a" at position 5
// show
{ "b"a
^
JSON_ERROR_001 Unexpected token "a".
Expecting a ":" over here, eg:
{ "b": "bar" }
^
You can learn more about valid JSON string in http://goo.gl/xxxxx
If possible, provide suggestions based on the context that the parser has collected so far
fakeParseJSON('"Lorem ipsum');
// instead of
Expecting a `"` over here, eg:
"Foo Bar"
^
// show
Expecting a `"` over here, eg:
"Lorem ipsum"
^
The suggestion that based on the context will feel more relatable and actionable.
With all the suggestions in mind, check out the updated CodeSandbox with
- Meaningful error message
- Code snippet with error pointing point of failure
- Provide suggestions for error recovery
Summary
To implement a parser, you need to start with the grammar.
You can formalise the grammar with the railroad diagrams or the Backus-Naur Form. Designing the grammar is the hardest step.
Once you’ve settled with the grammar, you can start implementing the parser based on it.
Error handling is important, what’s more important is to have meaningful error messages, so that the user knows how to fix it.
Now you know how a simple parser is implemented, it’s time to set eyes on a more complex one:
Lastly, do follow @cassidoo, her weekly newsletter is awesome!





{kind=link}
{kind=link}
{kind=link}
Top comments (0)