“Within the light cone is destiny” -- Cixin Liu
Performance is primarily determined by the algorithm of the code. There is no question of that. Some algorithm written in python is a lot slower than written in c. To me, this is also an algorithm problem, if you think the code and its language as a whole. It takes a lot more machine instruction to do the same thing in python than c. The sequence of machine instructions is an algorithm.
x86 instruction can be seen as a high-level language for micro-code used internally in the CPU. When CPU decode the x86 instruction to micro-code with speculative execution will cause significant performance difference. This can also be categorized as an algorithm (of increasing concurrency) problem, and it is not what I want to talk about here.
Besides the algorithm, what else can makes code slow to execute on the machine? The answer is "data locality", it takes time to read and write the data for computation. There are multiple examples of it
- CPU Cache
- GPU Architecture
- Distributed Map/Reduce
- Heap Management
Walking through these examples, we can see why Heterogeneous Computing is inevitable, and programming model in mainstream programming languages is overly simplified.
CPU Cache
Consider this example https://stackoverflow.com/questions/9936132/why-does-the-order-of-the-loops-affect-performance-when-iterating-over-a-2d-arra
Iterate matrix column-wise
#include <stdio.h>
#include <stdlib.h>
main () {
int i,j;
static int x[4000][4000];
for (i = 0; i < 4000; i++) {
for (j = 0; j < 4000; j++) {
x[j][i] = i + j; }
}
}
Iterate matrix row-wise
#include <stdio.h>
#include <stdlib.h>
main () {
int i,j;
static int x[4000][4000];
for (j = 0; j < 4000; j++) {
for (i = 0; i < 4000; i++) {
x[j][i] = i + j; }
}
}
Row-wise version is 3x to 10x times faster than column-wise version. When the memory address is written continuously, the write can be combined into a single request to save the time on the round-trip.

According to https://en.wikipedia.org/wiki/CPU_cache, as the x86 microprocessors reached clock rates of 20 MHz and above in the 386, small amounts of fast cache memory began to be featured in systems to improve performance. The biggest problem of processor design is that the memory cannot keep up with the speed of the processor.

We can see the chart above, modern CPU can crunch a lot of numbers per second. The theoretical data transfer rate to keep the cpu busy is way higher than the bandwidth currently main memory can provide.
The latency between CPU and main memory is ultimately governed by the speed of light. We have to bring the memory closer to CPU to lower the latency. But on-chip memory (L1/L2/L3 cache) cannot be too large, otherwise, the circuit will be long, and latency will be high.
GPU Architecture
In the design of CPU, the cache is invisible, the memory is coherent. You do not need to take care of the synchronization between the cache and memory of all sockets. Although you do need to use a memory barrier to declare the actions sequence on one memory address as if they have contended directly on the memory itself directly. To make this happen, CPU need high-speed ring/mesh to synchronize the cache between sockets.
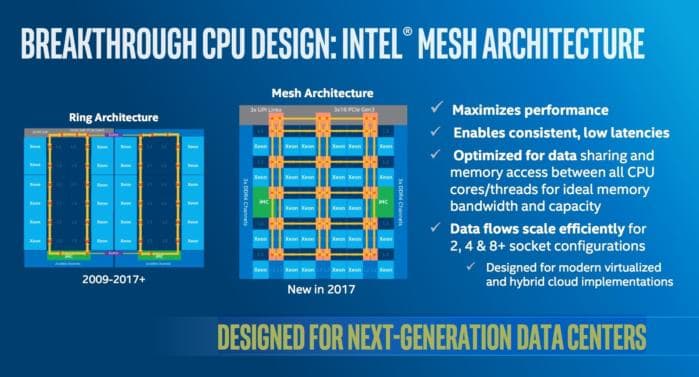
This programming model prevents the cores from growing. It is too costly to maintain the illusion of direct memory sharing between cores because the latency of data transfer is inevitable. The memory change needs to be broadcasted to all cache.
GPU architecture is different. It solves the memory latency issue by making the "cache" explicit. Instead of calling it "cache", it is just another layer of memory you can use.
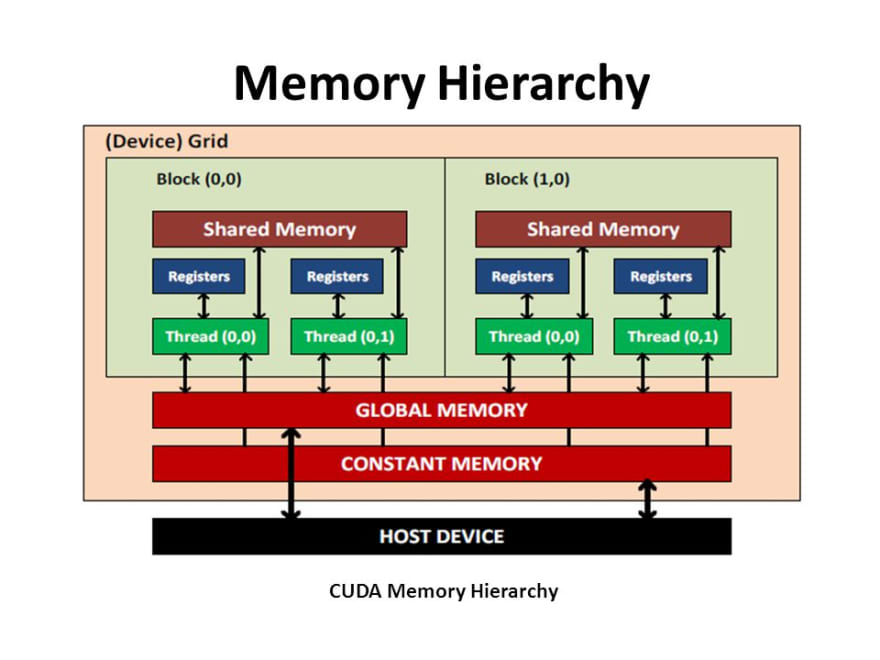
In this programming model, there is not just one "heap" of memory, instead the variable need to be explicit about its scope. For example
__global__ void parallel_shared_reduce_kernel(float *d_out, float* d_in){
int myID = threadIdx.x + blockIdx.x * blockDim.x;
int tid = threadIdx.x;
extern __shared__ float sdata[];
sdata[tid] = d_in[myID];
__syncthreads();
//divide threads into two parts according to threadID, and add the right part to the left one,
//lead to reducing half elements, called an iteration; iterate until left only one element
for(unsigned int s = blockDim.x / 2 ; s>0; s>>=1){
if(tid<s){
sdata[tid] += sdata[tid + s];
}
__syncthreads(); //ensure all adds at one iteration are done
}
if (tid == 0){
d_out[blockIdx.x] = sdata[myId];
}
}
Variable either has no prefix, or __shared__ or __global__. In CPU programming, we need to guess how the cache works. Instead, we can just ask in GPU programming.
Distributed Map/Reduce
Map/Reduce can handle big data distributed because it avoids data transfer to do computation on the node where data originally is

The data sent from "map" nodes to "reduce" nodes is substantially smaller than original input because partial computation has already been done.
Heap Management
Big heap is hard to manage. In modern c++ or rust, we use ownership to manage the memory. Essentially, instead of managing the whole heap as a connected object graph using the garbage collector, the heap is divided into smaller scopes. For example
class widget {
private:
gadget g; // lifetime automatically tied to enclosing object
public:
void draw();
};
void functionUsingWidget () {
widget w; // lifetime automatically tied to enclosing scope
// constructs w, including the w.g gadget member
…
w.draw();
…
} // automatic destruction and deallocation for w and w.g
// automatic exception safety,
// as if "finally { w.dispose(); w.g.dispose(); }"
There are a lot of cases, the lifetime of one memory address aligned well with function enter/exit and object construction/destruction. There are cases, explicit annotation of the lifetime will be needed
fn substr<'a>(s: &'a str, until: u32) -> &'a str;
Lifetime declaration like 'a is similar with __shared__ in CUDA. Explicit lifetime management like c++ and rust is one extreme. Multi-thread safe garbage collected language like Java and Go is another extreme. Language like Nim partition the memory by threads, which lies in the middle of the spectrum. To ensure the memory in the different partition does not accidentally shared, memory needs to be copied when crossing the boundary. Again, minimizing cost of memory copy is a data locality problem.
JVM has garbage collection. Instead of annotating the source code statically, it tries to figure out what goes with what in the runtime by dividing the big heap into rough generations:

It will a lot easier to deal with heap management problem if we do not share big heap in the first place. There will be cases having multiprocessor sharding memory be beneficial (https://en.wikipedia.org/wiki/Symmetric_multiprocessing). But for a lot of cases, co-locating data and computation (actor programming model) will be easier.
Co-locate data and computation
Instruction per clock is not growing very fast.

Main memory access latency is nearly flat

Having to deal with more than one processors, each with its own memory (Heterogeneous Computing) is likely to be pervasive. It is a clear trend that we need to ensure the data and computation co-located with each other in this paradigm. The problem is how to properly partition the data and computation, in the way data copy or message passing is minimized.




Top comments (0)