Identifiers are one of the most important parts of a program. They literally identify the parts of the program.
If you're not completely familiar with the term identifier, we'll quickly define it. Identifiers are the names you give the various pieces and constructs of a program. They are the variable names, class names, constant names, function names, method names, etc of your program. Identifiers make a program more about the programmers than about the computer. And they are a key to readability and maintenance.
There's an old saying: the two hardest tasks in programming are naming and cache invalidation (the second item is often substituted for equally difficult concepts). The point of this saying is to juxtapose the two items. Naming is so simple, and the second item, in this case, cache invalidation is so complex. Yet both are inordinately difficult.
The "names" in our program are the identifiers. So naming them well is something upon which we should spend appropriate time and effort.
So let's discuss the code smell of identifiers that are "too short".
It is tempting to move quickly when naming identifiers while writing an application, and not give it the appropriate amount of thought. Need to count something? how about "cnt". Want to sum up something? Let's just use "sum". It's so seductive. We can give them a cursory amount of effort and in the end our program is working correctly and we can move on to the next piece.
Oh, we need another count of something? How about "count" since "cnt" is already taken, or maybe we'll go with "cnt2". And while we're at it, the next sum will be "total" and the one after that we'll name "totalsum".
Let's look at a real world-example:

(this is code I wrote myself, btw)
Now at first glance this looks fine. And I can't honestly say that this is terrible code. But we can always look for improvement.
Notice in this code the identifier "val". What is that? You can probably surmise that it's short for "value". But do we know what this value is? what does it do?
Maybe we just need more context?
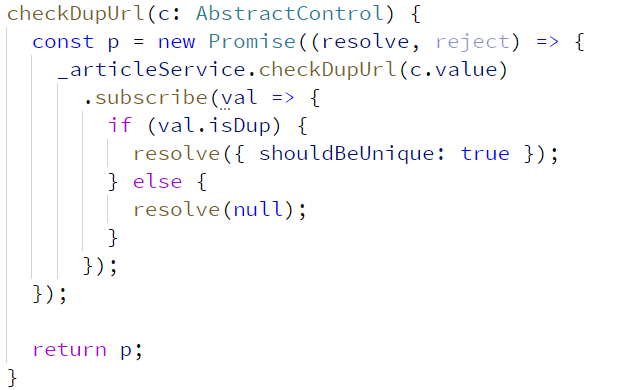
Well, that helps a little. We now know the algorithm is checking URL. But we still can't be sure what the "val" variable is supposed to contain. is it a URL? is it part of a URL? is it something related to a URL?
We can tell that the "val" variable is the "value" property of some kind of control. That's something. It's not like I named it "a" or "foo" or even "str". But it doesn't tell us what is IN that variable. It doesn't tell us what the user should have typed. It doesn't help us know how to work with the data.
Is it subtle? Yes. I purposely chose this example because it's not "wrong" but it could be better. When I wrote this, I just quickly threw in the name "val" for the identifier. I didn't want to take the time to make it more explicit and spend time thinking on the name.
But names like this live on. If we extract that callback into its own function, then we REALLY lose context.
Is it some extra time? yes. Extra mental effort? yes. But Does it get easier with practice? yes. And does it pay off in the long run? YES.
Happy Coding!
Enjoy this discussion? Sign up for our newsletter here.
Visit Us: thinkster.io | Facebook: @gothinkster | Twitter: @gothinkster





Top comments (1)
Or make it even easier to understand by destructuring isDup and remove the redundant val variable althogether.
Personally I think val is fine here, that it's a url isn't really relevant to the subscribe block as proved by the destructure refactor. If you treat it as url later on then by all means rename the variable otherwise let TypeScript guide you and move on.