
GraphQL came to solve lots of problems in how do we handle data access. One of its benefits is providing an API to the frontend so it can fetch the data as it wants without the need of the backend team to provide a specific endpoint for each data combination. The frontend needs a client (Apollo or Relay) to provide the link with the GraphQL API and so be able to perform queries and mutations as you define them. It gives more power to the frontend to design how they will be handled.
"With great power comes great responsibilities", Uncle Ben
If you don't architect your queries correctly in the frontend, you might have bad problems in the future and some will be hard to fix. So following I'll give some examples from my past experiences about anti-pattern you might avoid when building your queries and fragments to use in your GraphQL Client.
TL;DR
Avoid anti-patterns on your queries and mutations to avoid issues as your application grows
Reuse Fragments in different queries
As smart developers, as we are, we try to avoid repeating ourselves as much as possible (DRY), and so we are into writing reusable codes everywhere and importing them whenever we need it. That's nice! But it may not be so nice when it comes to fragments and queries.
This mindset might lead us to think we can reuse fragments along with different queries. If I need the user name and email, why don't I create a userFragment and spread it on every query that needs the user?
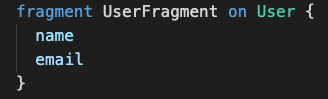
The problem is: what if in a specific component you need now the user job role? And in another component, you need the user friends list? Especially if you're working in a big team, you may easily fall into over fetching issues, and that's what we want the less. GraphQL is designed specially to solve this problem and we are recreating it.
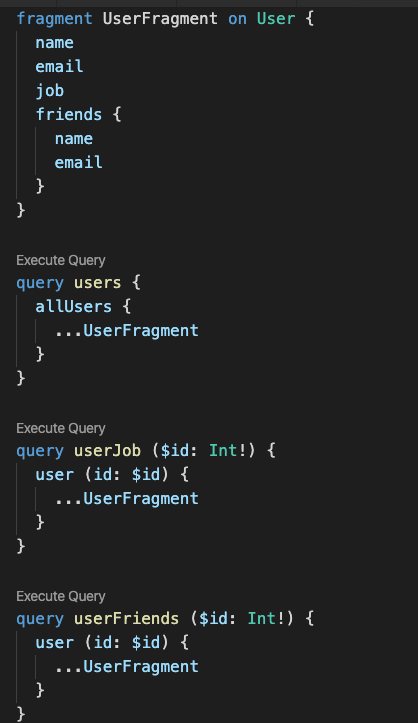
A simple example of different queries using the same fragment
So it's not a matter of never using it, but avoiding using it. Of course, there might be use cases where this approach can be helpful, but in general, it's so easy to get tempted to keep adding items to this fragment and face issues in the future
Solution
Instead of doing that, you can use smart components to solve this issue. So each component in your tree is responsible for defining the fragment with all the data it needs to be rendered. You might repeat yourself more often, but you'll never face over fetch, under fetch, or performance issues. It also helps with the scalability and maintainability of the project.

Nested fragments and over fetching
In the previous topic, we talked about the issue of reusing the fragments and over fetching issues. This one is kind related. Let's say we have an application where the user selects the latest books he/she read. Then, we want to display the list of users and the books they read. So we create a query in our GraphQL using a UserFragment and a BookFragment. Something like this:

Let's say that we need to display to the users the list of the books available in our application to be selected. We would need a query like this:

Cool! Now let's say we want to display the author data in the books' list. We can create an AuthorFragment and add it to the BookFragment:

And here our problem begins.
If we don't need the author data in the user list since we're spreading the AuthorFragment in the BookFragment, and the BookFragment in the UserFragment, when you load the user list your query will fetch more data than your component needs, and so you'll fall into the over fetching issues.

The same applies if after a few months in the project you no longer need some data in the users' list, but you do in the books' list, you might end removing some data from the AuthorFragment to fix the users' list and then introduce errors to the books' list.

This is quite a simple example but think about it in a large and complex application. You'll definitely have headaches when start to face performance issues.
Solution
Instead of using nested fragments, I'd suggest keeping your fragments as flatten as possible. Even if your fragment looks big (too many lines), it's better to have a well-controlled fragment in a single component, than facing over fetching or data dependency issues.

Nested fragments and argument dependencies
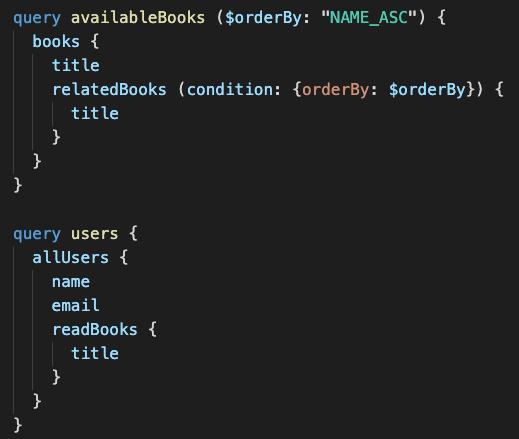
Another issue of nested fragments is the argument dependencies. Taking our previous case as an example let's say in our books' list we want to display a list of related books, to do so we create a fragment and use an argument to order the related books by name, so it'll look something like this:

It works great! But do you remember that we have this BookFragment spread in the users' list?

So, since we added the RelatedBooks node with an argument, we now need to define the same argument in the users' list query, otherwise, it'll break your GraphQL request.

If you use the approach of having multiple files for your GraphQL SDL (Schema Definition Language), you might get into the situation of getting this error only in the runtime. As your application grows, and if you don't have enough tests on it, you might only be aware of this new error when your application is already deployed. And of course, we don't want our customers to see a Bad Request GraphQL error.
Solution
The smart components and flatten fragments solution also helps to prevent this error.
Refetch after mutate, instead of using mutate result
This one divides opinions in the community. Especially because Apollo Client has the refetchQueries option in the mutation that allows you to specify which queries you want to refetch after the mutation completes. The main problem with this approach is that it prevents us from using one of the GraphQL concepts.
The GraphQL mutation is designed to send a write method to the server and return a read as a result. So every time you call a mutation, you're also returning a query from it. And this is where it might be considered as an anti-pattern to use the refetchQueries after the mutation. You can design your mutation to return the query you need and update your cache based on this return, so you'll only need a single request in your server.
If you use the refetchQueries, instead, you'll have to reach to your server multiple times: one for the mutation and N more times for as many queries as you have defined in the refetchQueries, which may imply on performance and bandwidth issues.
Solution
So, as already mentioned, the ideal solution for this is to design your mutations to return what your component needs to update your cache, instead of calling all the queries over again.

Final thoughts
So that's it. I just would like to share some of my past experiences and how not following some good practices, in the beginning, can lead to tremendous issues and refactoring in the future. Hope this article can help someone else. I'm also open to suggestions and opinions!





Top comments (0)