
Whisper is a general-purpose speech recognition model open-sourced by OpenAI.
According to the official article, the automatic speech recognition system is trained on 680,000 hours of multilingual and multitask supervised data collected from the web.
I was surprised by Whisper’s high accuracy and ease of use.
Whisper provides so useful command line that you can feel free to try it.
I'll present how to run Whisper on Google Colaboratory here.
You can refer to this Colab notebook if you want to try Whisper immediately on Google Colaboratory.
📖 Colaboratory whisper-mock-en
Create a new Colab notebook
You need to crate a new Colab notebook from your Google Drive at the first.
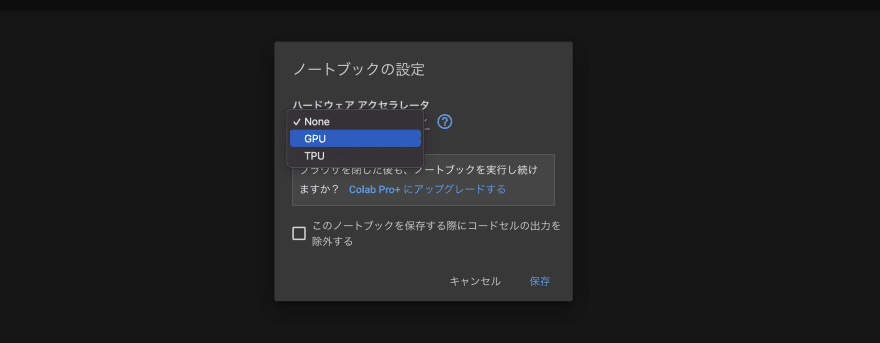
You have to make sure your notebook is using a GPU. To do that, change a runtime type to GPU from the menu.
Install package
You need to install a package like the following line to run Whisper.
# Install packages
!pip install git+https://github.com/openai/whisper.git
Add folders
Add this code to create new folders when you click the play button.
import os
# Add folders
checkContentFolder = os.path.exists("content")
checkDownLoadFolder = os.path.exists("download")
if not checkContentFolder:
os.mkdir("content")
if not checkDownLoadFolder:
os.mkdir("download")
Upload an audio file
You have to upload at least an audio file into the content folder after you've installed packages and added folders.
Transcription with Python
You can modify the file name of the audio and target language to translate.
import whisper
fileName = "sample.m4a"
lang = "en"
model = whisper.load_model("base")
# Load audio
audio = whisper.load_audio(f"content/{fileName}")
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# Output the recognized text
options = whisper.DecodingOptions(language=lang, without_timestamps=True)
result = whisper.decode(model, mel, options)
print(result.text)
# Write into a text file
with open(f"download/{fileName}.txt", "w") as f:
f.write(f"▼ Transcription of {fileName}\n")
f.write(result.text)
Download a transcription file
It would be easy to download a transcription file if you added this code.
from google.colab import files
!zip -r download.zip download
files.download("download.zip")
Let's run Whisper on Google Colaboratory
Let's check how your code works on Colab notebook.
I prepared a Colab notebook to use Whisper, so you can copy this notebook.
📖 Colaboratory whisper-mock-en
Conclusion
I hope this tutorial got you to generate your first transcription.





Top comments (1)