In this guide, we'll show you how to implement semantic search in your PostgreSQL database using Cohere’s embedding models—in less than 10 minutes! By using the pgvector and pgai extensions, we'll simplify the workflow, while PopSQL will serve as our SQL client. With this approach, you can quickly build semantic search-powered applications without relying on any additional tools.
Vector Embeddings and Semantic Search
Before diving in, let’s first understand the concept of semantic search. At its core, semantic search relies on transforming data into vector embeddings using advanced embedding models. These embeddings represent data as numerical vectors, where similar items are positioned closer together in a high-dimensional vector space.
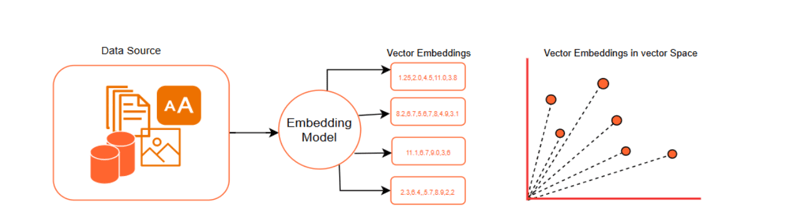
Semantic search utilizes the power of embeddings to deliver highly relevant results. Here's an overview of how it works:
- Generate embeddings for your text : Both the search query and the documents in your database are converted into embeddings using an embedding model.
- Measure similarity : The embeddings for the query are compared to those of the documents using similarity metrics like cosine similarity to find the most semantically relevant results.
- Retrieve the most relevant results : Based on the similarity scores, the system ranks documents and returns the most relevant ones to the user.
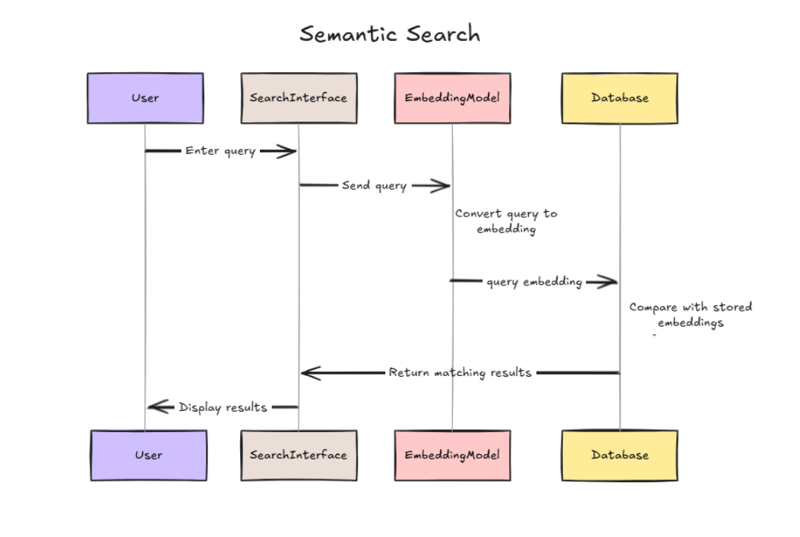
The success of semantic search relies heavily on how accurately embedding models capture the features of data in a vector format. As a result, the quality of the embedding model used plays a crucial role.
Cohere’s embedding models
Cohere’s embedding models are among the best-performing options available. At the time of writing this guide, Cohere offers several models you can choose from, depending on your application needs.
| Model | Embedding Dimension |
|---|---|
| embed-english-v3.0 | 1024 |
| embed-multilingual-v3.0 | 1024 |
| embed-english-light-v3.0 | 384 |
| embed-multilingual-light-v3.0 | 384 |
| embed-english-v2.0 | 4096 |
| embed-english-light-v2.0 | 1024 |
| embed-multilingual-v2.0 | 768 |
The embedding dimension refers to the number of features in the vector that represent the data. In this guide, we will use the embed-english-v3.0 model, which has 1,024 dimensions.
Implementation Steps
Let’s dive into the implementation. You can find all the code for this tutorial on GitHub. Here’s a high-level overview of the steps we’ll follow:
- Set up a PostgreSQL database with pgai and pgvector.
- Set up the PopSQL client.
- Get your Cohere API key and store it as a variable.
- Load a dataset from Hugging Face.
- Use the pgai function
ai.cohere_embed()to generate embeddings from the data. - Add an HNSW index to speed up semantic search queries.
- Perform semantic search by converting the user’s query into a vector embedding.
Set Up PostgreSQL
You’ll need a working installation of PostgreSQL with the pgai, pgvector, and pgvectorscale extensions. You can deploy it locally using Docker or sign up for Timescale Cloud to get a free PostgreSQL instance. For simplicity, let’s go with the latter approach.
When launching the PostgreSQL instance on Timescale, make sure to select AI and Vector capabilities.
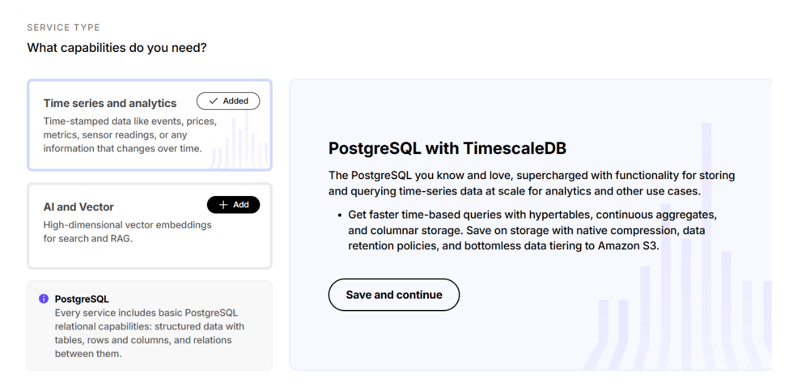
After you’ve launched the service, keep the connection details handy for the next step.
Set Up PopSQL
We will use PopSQL, a powerful collaborative SQL editor. Visit the PopSQL website, sign up, and download the desktop client. You can also use the browser app.
In the PopSQL client, create a new connection by choosing PostgreSQL.
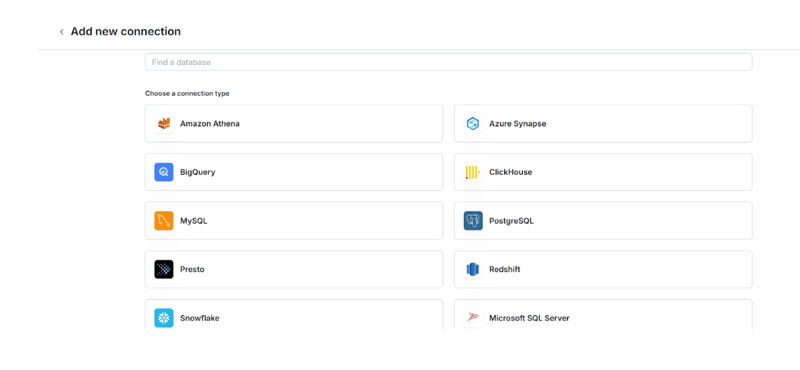
Enter the credentials from the connection details or the database configuration file you downloaded earlier, then click Connect.
You can now use PopSQL to run the SQL queries. Let’s enable the pgai and pgvector extensions using the following commands.
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS ai CASCADE;
CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE;
Get Cohere API
Sign up on Cohere and get an API key.
After you have logged into Cohere, you can generate your trial key from the API Keys section.
Cohere offers a limited free trial, which should be enough for this guide. Here is how we can set it in the PostgreSQL environment:
SELECT set_config('ai.cohere_api_key', '<YOUR-API-KEY>', false);
Load the dataset
For this guide, we’ll use the Cohere/movies dataset from Hugging Face. You can load it easily using the ai.load_dataset function provided by pgai. This function will also automatically create a table named movies.
SELECT ai.load_dataset(
'Cohere/movies',
if_table_exists := 'append'
);
You can verify the data using the following query:
SELECT * FROM movies LIMIT 20;
Since we’re using a trial API key from Cohere, we’ll create a replica table with fewer rows to avoid exceeding the API limits. If you have a paid account, you can skip this step.
CREATE TABLE movies_dataset AS
SELECT *
FROM movies
LIMIT 20;
Add a primary key column
You’ll need to add a primary key column, as the dataset doesn’t have it. Let’s add movie_id as SERIAL PRIMARY KEY:
ALTER TABLE movies_dataset
ADD COLUMN movie_id SERIAL PRIMARY KEY;
Vectorizer
Next, you'll set up the vectorizer for the movies_dataset table. This vectorizer will generate embeddings from the overview column, which will later be used for semantic search.
We're using the cohere/embed-english-v3.0 model for embedding generation. The vectorizer will be named movies_embeddings_vectorized. The embedding dimension is set to 1,024 , as specified by the model.
We will also create an HSNW index to speed up similarity searches. HNSW is a graph-based algorithm designed for approximate nearest neighbor (ANN) searches.
The HNSW algorithm builds a multi-layer graph where:
- Top layers : contain fewer nodes for coarse-grained navigation
- Lower layers : offer fine-grained navigation for more precise searches
The search process begins at the top layer and traverses downward, leveraging the small-world graph structure to locate neighbors efficiently. HNSW delivers high search speed and accuracy, making it well-suited for large datasets.
SELECT ai.create_vectorizer(
'movies_dataset'::regclass,
destination => 'movies_dataset_embeddings_vectorized',
embedding => ai.embedding_litellm(
'cohere/embed-english-v3.0',
1024,
api_key_name => 'COHERE_API_KEY' ---do not change this-it's the name not api key
),
chunking => ai.chunking_recursive_character_text_splitter('overview'),
formatting => ai.formatting_python_template('$title: $chunk'),
indexing => ai.indexing_hnsw(opclass => 'vector_cosine_ops')
);
For larger datasets, you can create a StreamingDiskANN index instead. This index overcomes the limitations of in-memory indexes like HNSW by storing part of the index on disk.
(Optional) Running vectorizer worker
If you are using a PostgreSQL instance on Timescale Cloud, you don’t need to worry about running the vectorizer worker (background job).
However, if you have installed PostgreSQL and pgai manually or using Docker, you would need to also run the vectorizer worker. Read through the vectorizer quickstart for an overview of how to set it up.
Semantic search
To perform semantic search, you’ll need to convert the query into a vector embedding using the same embedding model used to embed your data. Once the query is embedded, you can perform semantic search by leveraging the cosine similarity metric. The returned results will include details such as the title, overview, genres, and cast.
Here’s how you can perform the semantic search:
WITH query_embedding AS (
SELECT ai.cohere_embed(
'embed-english-v3.0',
'show me action packed movies',
input_type => 'search_query',
api_key => '<COHERE_API_KEY>'
) AS embedding
)
SELECT
m.title,
m.overview,
m.genres,
m.producer,
m.cast,
t.embedding <-> qe.embedding AS distance
FROM movies_dataset_embeddings_vectorized t
CROSS JOIN query_embedding qe
LEFT JOIN movies_dataset m ON t.movie_id = m.movie_id
ORDER BY distance
LIMIT 5;
In PopSQL, you can view your data in a tabular format. Here are the results of our query.
| # | Title | Overview | Genres | Cast |
|---|---|---|---|---|
| 1 | Titanic | 84 years later, a 101-year-old woman named Rose DeWitt Bukater | Drama, Romance, Thriller | Kate Winslet as Rose DeWitt Bukater, Leonardo DiCaprio as Jack |
| 2 | Frozen | Young princess Anna of Arendelle dreams about finding true love | Animation, Adventure, Family | Kristen Bell as Anna (voice), Idina Menzel as Elsa (voice), Jonathan |
| 3 | Skyfall | When Bond's latest assignment goes gravely wrong and agents | Action, Adventure, Thriller | Daniel Craig as James Bond, Judi Dench as M, Javier Bardem as Silva, Ralph Fiennes as Gareth Mallory / M, Naomie Harris as Eve |
As you can see, the results are quite accurate in both cases. Rather than relying on keyword matches, the results leverage the semantic context of the underlying data. Moreover, we didn’t need any additional libraries or tools—pgai allowed us to create a powerful semantic search workflow directly within the PostgreSQL database.
Conclusion
Semantic search with vector embeddings offers a revolutionary way to improve information retrieval by focusing on the meaning behind text rather than exact keyword matches. With this guide, we demonstrated how to set up a semantic search in PostgreSQL using Cohere's embedding model and pgai. You can apply a similar approach for use cases like building recommendation systems, document retrieval, and contextual search.
If you want to perform semantic search in your applications, install pgai and pgvector with PostgreSQL, or sign up for a free PostgreSQL instance on Timescale Cloud.

Top comments (0)