
Execute the SQL Script using \i with the Correct Path:
Once you're in the psql shell connected to the "test" database, directly provide the path to the SQL script file using the \i meta-command.
Ensure you use the correct path syntax:
- \i 'D:/PostGres/person.sql'
or if the script is in the same directory:
- \i 'person.sql'
DAY-89 (2/3/2024)
-
Select From
##Order By :- Takes a column and returns it according to ascending or descending order.
- It works on Dates, numbers and Strings
- If DESC case:
- Null has the high priority , then z , x , y
SELECT * FROM person ORDER BY id, email ASC limit 20; how this ORDER BY actually work on multiple column id and email?
Ans: When you use the ORDER BY clause with multiple columns, such as ORDER BY id, email ASC, PostgreSQL sorts the result set first by the values of the id column in ascending order and then by the values of the email column in ascending order.
Here's how the sorting works:
The result set is sorted based on the values of the id column in ascending order. This means that rows with lower id values will appear before rows with higher id values.
For rows with the same id value, the sorting continues based on the values of the email column in ascending order. This means that within rows with the same id value, rows with "lower" (alphabetically earlier) email values will appear before rows with "higher" (alphabetically later) email values.
So, the sorting priority is first given to the id column and then to the email column. If there are multiple rows with the same id value, they will be ordered based on the email column.
If you want to sort the email column in descending order instead, you can specify DESC after email, like so: ORDER BY id ASC, email DESC. This would sort the id column in ascending order and the email column in descending order.
- In post GresQl to clear the terminal use \! cls
DAY-90 (3/3/2024)
Distinct
- In normal search we can have duplicate data Like:
-
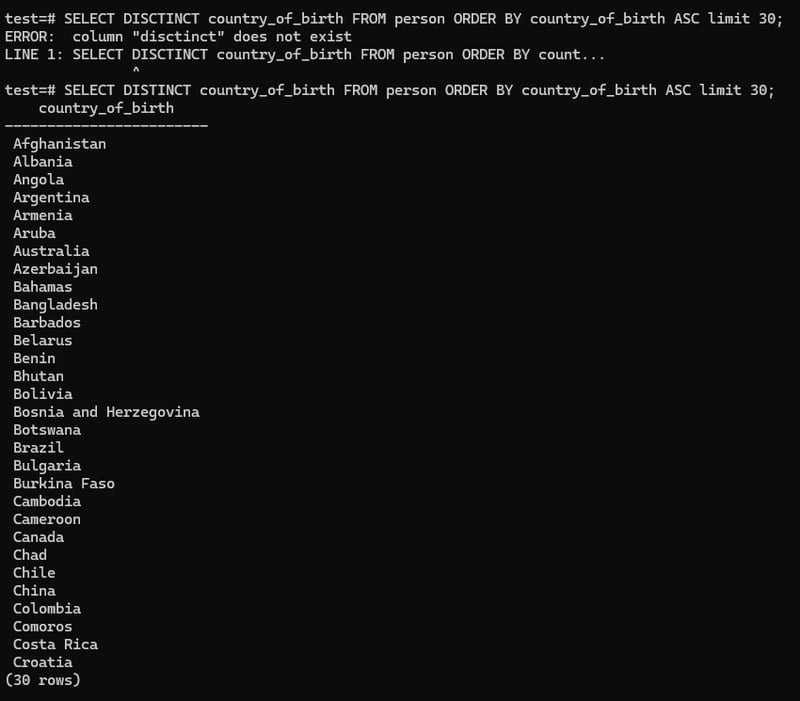
SELECT country_of_birth FROM person ORDER BY country_of_birth ASC limit 30;
-
- So that we can use DISTINCT
SELECT DISTINCT country_of_birth FROM person ORDER BY country_of_birth ASC limit 30;which helps us to distinguish unique values from the table.
(:
WHERE clause & AND
- We can give conditions using WHERE clause.
- By using AND we can add more conditions
- And the OR helps , if either true then shows the output.
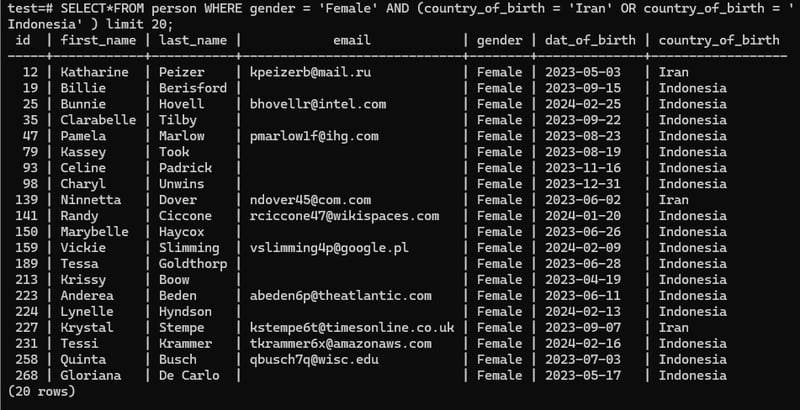
SELECT*FROM person WHERE gender = 'Female' AND (country_of_birth = 'Iran' OR country_of_birth = 'Indonesia' ) AND last_name = 'Peizer' limit 20;
DAY-91 (4/3/2024)
COMPARISON OPERATOR
- Most of the Time we will use arithmetic operator and comparison operator
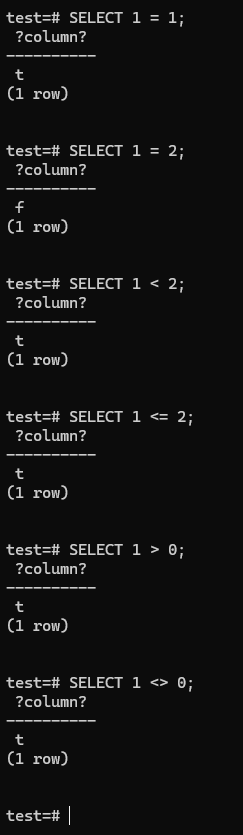
- `SELECT 1 = 1;
- For not equal: ` 1 <> 2`
SELECT 1 <> 0;
- These operator works on text, string, date, integer
Limit, Offset & Fetch
Limit
In PostgreSQL, the LIMIT clause is used in a SELECT statement to restrict the number of rows returned by a query. It allows you to limit the number of rows returned by the query result set to a specified number.
Here's the basic syntax of the LIMIT clause:
sql
SELECT column1, column2, ...
FROM table_name
LIMIT number_of_rows;
Where:
column1, column2, ...: The columns you want to retrieve data from.
table_name: The name of the table you want to query.
number_of_rows: The maximum number of rows to be returned by the query.
For example, if you want to retrieve only the first 10 rows from a table named my_table, you would use:
sql
SELECT *
FROM my_table
LIMIT 10;
This would return the first 10 rows from the my_table table.
The LIMIT clause is commonly used to optimize queries by reducing the amount of data returned, especially when dealing with large datasets, or to implement pagination in applications where you only want to display a limited number of rows per page.
OFFSET
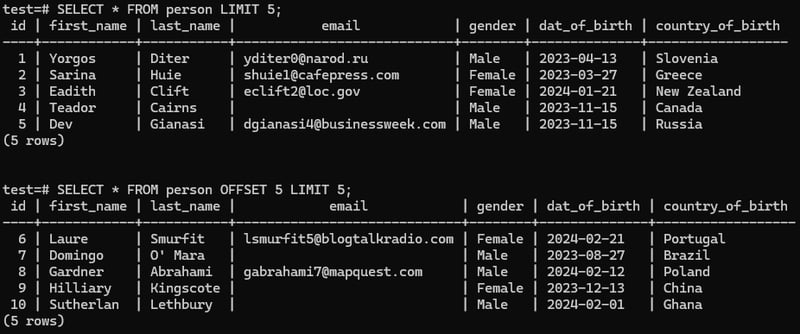
In PostgreSQL, the OFFSET clause is used in conjunction with the LIMIT clause to skip a specified number of rows from the beginning of the query result set. This allows you to retrieve rows starting from a certain position in the result set.
Here's the basic syntax of the OFFSET clause:
sql
SELECT column1, column2, ...
FROM table_name
LIMIT number_of_rows OFFSET offset_value;
Where:
column1, column2, ...: The columns you want to retrieve data from.
table_name: The name of the table you want to query.
number_of_rows: The maximum number of rows to be returned by the query.
offset_value: The number of rows to skip from the beginning of the query result set.
For example, if you want to retrieve 10 rows from a table named my_table, starting from the 11th row (i.e., skipping the first 10 rows), you would use:
sql
SELECT *
FROM my_table
LIMIT 10 OFFSET 10;
This query would return 10 rows from my_table, starting from the 11th row.
The OFFSET clause is commonly used in combination with LIMIT for implementing pagination in applications, where you want to retrieve a subset of rows from a large result set, starting from a specific page.
FETCH
In PostgreSQL, the FETCH clause is used in a SELECT statement to retrieve a specified number of rows from a result set, similar to the LIMIT clause. However, the FETCH clause provides more flexibility by allowing you to specify options such as skipping a certain number of rows (OFFSET) and limiting the number of rows to fetch.
Here's the basic syntax of the FETCH clause:
sql
SELECT column1, column2, ...
FROM table_name
FETCH { FIRST | NEXT } number_of_rows { ROW | ROWS } { ONLY | WITH TIES } OFFSET offset_value;
Where:
column1, column2, ...: The columns you want to retrieve data from.
table_name: The name of the table you want to query.
number_of_rows: The number of rows to be fetched from the result set.
OFFSET offset_value: (Optional) The number of rows to skip from the beginning of the result set.
FIRST or NEXT:** Specifies whether to fetch the first number_of_rows rows or the next number_of_rows rows after skipping the specified OFFSET rows.
**ROW or ROWS: Specifies the unit of the number of rows to be fetched.
ONLY: (Optional) Specifies to fetch exactly the specified number of rows.
WITH TIES: (Optional) Specifies to include additional rows tied in value with the last row fetched when using ORDER BY.
Here's an example of using the FETCH clause:
sql
SELECT *
FROM my_table
ORDER BY id
FETCH FIRST 10 ROWS ONLY OFFSET 10;
This query fetches the next 10 rows from the my_table table after skipping the first 10 rows, ordered by the id column. It will return rows 11 through 20 from the result set.
The FETCH clause is particularly useful when combined with ORDER BY and for implementing pagination in applications. It provides more control over the rows to be fetched compared to the LIMIT and OFFSET clauses.
ROW AND ROWS in FETCH
The choice between ROW and ROWS depends on whether you want to fetch a specific number of individual rows or a number of rows as a set or group.
ROW: Specifies that you want to fetch a specific number of individual rows.
ROWS: Specifies that you want to fetch a set or group of rows.
In most cases, there is no difference between using ROW and ROWS, and they can be used interchangeably.
IN Command
SELECT * FROM person WHERE country_of_birth = 'China' OR country_of_birth = 'Bangladesh' OR country_of_birth = 'Iran' FETCH FIRST 20 ROWS ONLY;
Here we can see, there is multiple occurrence of country_of_birth.
So we can reduce it using IN command, Like:
NOTE: We can not use ORDER BY after FETCH command

SELECT * FROM person WHERE country_of_birth IN ('Brazil','Iran','Indonsia','Japa') FETCH FIRST 20 ROWS ONLY ORDER BY country_of_birth;
This command will not execute but
SELECT * FROM person WHERE country_of_birth IN ('Brazil','Iran','Indonsia','Japa') ORDER BY country_of_birth FETCH FIRST 20 ROWS ONLY;
This one will executes. Here at first the colums is sorted and then it fetch the data.
DAY-92 (5/3/2024)
**NOTE: In the PostgreSQL terminal (psql), you can clear the screen by issuing the meta-command ! cls. This command utilizes the ! escape sequence to execute a shell command, in this case, cls to clear the screen. Here's how you do it:
Copy code
\! cls
After running this command, the screen will be cleared, and you'll have a clean terminal window.**
BETWEEN
- Born between 2023-09-01 and 2024-01-01:
SELECT * FROM person WHERE dat_of_birth BETWEEN '2023-09-01' AND '2024-01-01' ORDER BY dat_of_birth DESC FETCH FIRST 19 ROWS ONLY;
LIKE & iLIKE
So like is wild card in database. It helps to search values using given pattern. There are different ways of searching.
SELECT * FROM person WHERE email LIKE'%.com';
It will search all the emails , that ends with .comSELECT * FROM person WHERE email LIKE'%google%.com';
It find google first and then .com .SELECT * FROM person WHERE email LIKE'%@ihg.%';
Here it fetch all the emails with @ihg.
Difference Between LIKE & ILIKE
So the main difference is, Like is Case sensitive and ILIKE is not case sensitive.
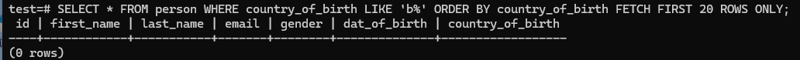
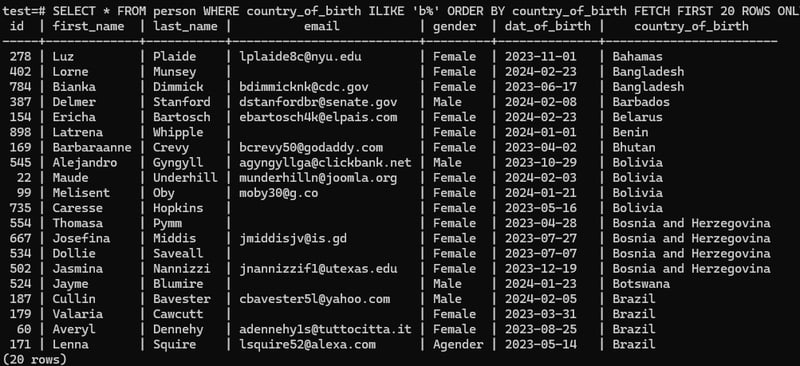
LIKE: SELECT * FROM person WHERE country_of_birth LIKE 'b%' ORDER BY country_of_birth FETCH FIRST 20 ROWS ONLY;
ILIKE: SELECT * FROM person WHERE country_of_birth ILIKE 'b%' ORDER BY country_of_birth FETCH FIRST 20 ROWS ONLY;
Basic Pattern Matching:
sql
Copy code
SELECT * FROM table_name WHERE column_name LIKE 'pattern';
Example: Select all rows where the name column starts with 'John':
sql
Copy code
SELECT * FROM employees WHERE name LIKE 'John%';
Case Insensitive Matching using ILIKE:
sql
Copy code
SELECT * FROM table_name WHERE column_name ILIKE 'pattern';
Example: Select all rows where the email column contains 'example.com' (case insensitive):
sql
Copy code
SELECT * FROM users WHERE email ILIKE '%example.com%';
Wildcard Characters:
%: Matches any sequence of characters (including zero characters).
_: Matches any single character.
Example: Select all rows where the name column contains 'son' in the third position:
sql
Copy code
SELECT * FROM students WHERE name LIKE '__son%';
Character Class Matching:
sql
Copy code
SELECT * FROM table_name WHERE column_name LIKE '[characters]';
Example: Select all rows where the name column starts with 'A', 'B', or 'C':
sql
Copy code
SELECT * FROM employees WHERE name LIKE '[ABC]%';
Negation:
sql
Copy code
SELECT * FROM table_name WHERE column_name NOT LIKE 'pattern';
Example: Select all rows where the email column does not end with '.com':
sql
Copy code
SELECT * FROM users WHERE email NOT LIKE '%.com';
Escaping Special Characters:
If you need to search for literal occurrences of %, _, or [, you can escape them using the backslash \ character.
Example: Select all rows where the name column contains '%':
sql
Copy code
SELECT * FROM students WHERE name LIKE '%\%%';
These are some common examples of using the LIKE operator in PostgreSQL for pattern matching.
User
Select all rows where the email column does
end with '.com':
ChatGPT
To select all rows where the email column ends with '.com', you can use the LIKE operator with the % wildcard character, which matches any sequence of characters. Here's the SQL query for that:
sql
Copy code
SELECT * FROM table_name WHERE email LIKE '%.com';
Replace table_name with the actual name of your table. This query will retrieve all rows where the email column ends with '.com'.
For example, if your table is named users, the query would be:
sql
Copy code
SELECT * FROM users WHERE email LIKE '%.com';
This query will return all rows from the users table where the email column ends with '.com'.
DAY-93 (6/3/2024)
GROUP BY
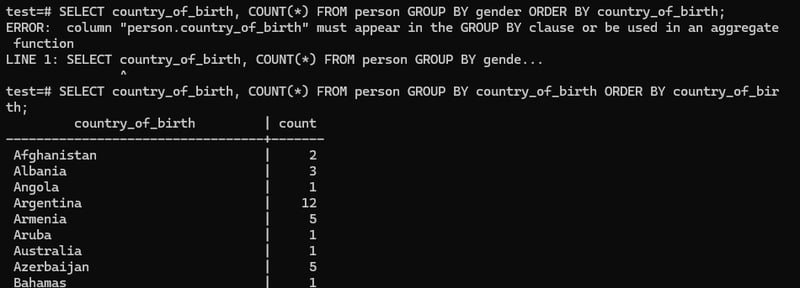
In GROUP BY we can use this command,
SELECT country_of_birth, COUNT(*) FROM person GROUP BY country_of_birth ORDER BY country_of_bir
th;But if we change a little bit like, if we select country_of_birth but for grouping we use gender then it will not work.
SELECT country_of_birth, COUNT(*) FROM person GROUP BY gender ORDER BY country_of_birth;
OUTPUT: column "person.country_of_birth" must appear in the GROUP BY clause or be used in an aggregate function
LINE 1: SELECT country_of_birth, COUNT(*) FROM person GROUP BY gende...
GROUP BY HAVING

SELECT country_of_birth, COUNT(*) FROM person GROUP BY country_of_birth HAVING COUNT(*) >= 87 ORDER BY country_of_birth;
Having Keyword must be written before ORDER BY keyword.
After HAVING we have to pass a function like greater than lass then or else.
Creating car table using mockaroo
- Inserting data: \i 'D:/100DayOfCode/Day93/car.sql';
Calculating MIN, MAX, AVERAGE
SELECT make, model, MIN(price) FROM car GROUP BY model, make;
- SELECT make, model, MIN(price) FROM car FETCH FIRST 20 ROWS ONLY; ERROR: column "car.make" must appear in the GROUP BY clause or be used in an aggregate function LINE 1: SELECT make, model, MIN(price) FROM car FETCH FIRST 20 ROWS ...
ANS:
The error message you encountered, "column 'car.make' must appear in the GROUP BY clause or be used in an aggregate function," indicates that the make column in the car table is being used in the SELECT clause without being included in the GROUP BY clause or used in an aggregate function like MIN, MAX, AVG, etc.
In PostgreSQL, when you use the GROUP BY clause in a query, any columns that appear in the SELECT list must either be included in the GROUP BY clause or used with an aggregate function. This is a requirement to ensure that the query produces deterministic results.
In your case, if you want to use the make column in the SELECT list without grouping by it or using an aggregate function, you should remove it from the SELECT list or adjust the query accordingly.
If you want to retrieve the first 20 rows from the car table without any grouping, you can simply remove the MIN(price) aggregation and the GROUP BY clause, like this:
sql
SELECT make, model, price FROM car FETCH FIRST 20 ROWS ONLY;
This will select the make, model, and price columns from the car table without any grouping or aggregation, and then fetch the first 20 rows from the result set.
In SQL, the GROUP BY clause is used to group rows that have the same values into summary rows, like "total price per make and model" or "average price per make and model." When you use GROUP BY, you're essentially telling the database to treat all rows with the same values in the specified columns as a single group.
In your query:
sql
Copy code
SELECT make, model, MIN(price) FROM car GROUP BY model, make;
The GROUP BY clause specifies that the rows should be grouped by the model and make columns. This means that rows with the same combination of model and make values will be aggregated together into a single row in the result set.
The MIN(price) function calculates the minimum price within each group. So, for each combination of model and make, you'll get the minimum price.
The role of GROUP BY in this query is to ensure that the MIN(price) function operates on distinct groups of rows. Without GROUP BY, the query would attempt to retrieve the minimum price across all rows without any grouping, which wouldn't make sense in this context.
So, in summary, the GROUP BY clause helps in organizing the data into meaningful groups based on the specified columns, and it's essential for queries that involve aggregation functions like MIN, MAX, AVG, etc.
Actually what happens is , GROUP BY will fetch all the cars with same company name (FORD) and model and then it will send it to MIN or MAX. After this it will give the output.
- We can not do ORDER BY on SUM column.

SELECT make, SUM(price) FROM car GROUP BY make ORDER BY price ASC;
But this will work:
SELECT make, SUM(price) FROM car GROUP BY make ORDER BY make DESC;
BASIC OF ARITHMATIC OPERATIONS
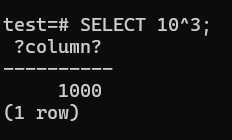
same way other operations works
ALIAS
Table Alias:
You can use aliases to give a temporary name to a table in a query. This can make your SQL query more readable, especially when dealing with long table names or when you need to join the same table multiple times.
Syntax:
sql
Copy code
SELECT alias.column_name FROM table_name AS alias;
Example:
sql
Copy code
SELECT u.id, u.name FROM users AS u;
Column Alias:
You can use aliases to rename columns in the result set of a query. This is useful for providing more descriptive or concise column names.
Syntax:
sql
Copy code
SELECT column_name AS alias FROM table_name;
Example:
sql
Copy code
SELECT first_name AS "First Name", last_name AS "Last Name" FROM employees;
Table and Column Alias Combined:
You can also use aliases for both tables and columns in the same query.
Example:
sql
Copy code
SELECT u.id AS user_id, u.name AS user_name FROM users AS u;
Aliases are not limited to just SELECT statements. They can also be used in UPDATE, DELETE, and INSERT statements, as well as in subqueries and joins. Aliases make SQL queries more readable and maintainable by providing shorter or more descriptive names for tables and columns.
Coalesec
How to handle null in sql
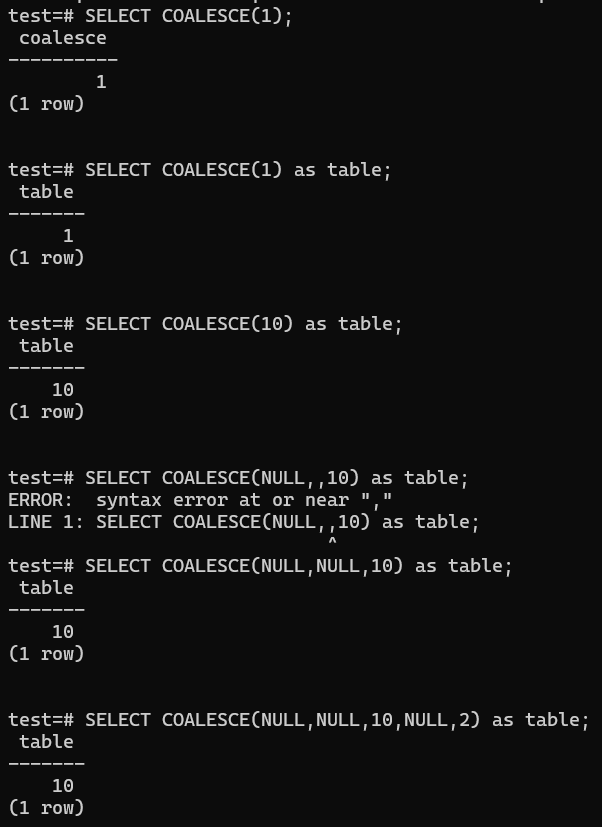
DAY-94 (7/3/2024)
Coalesec
SELECT COALESCE(email, 'Email ora day ni') FROM person;
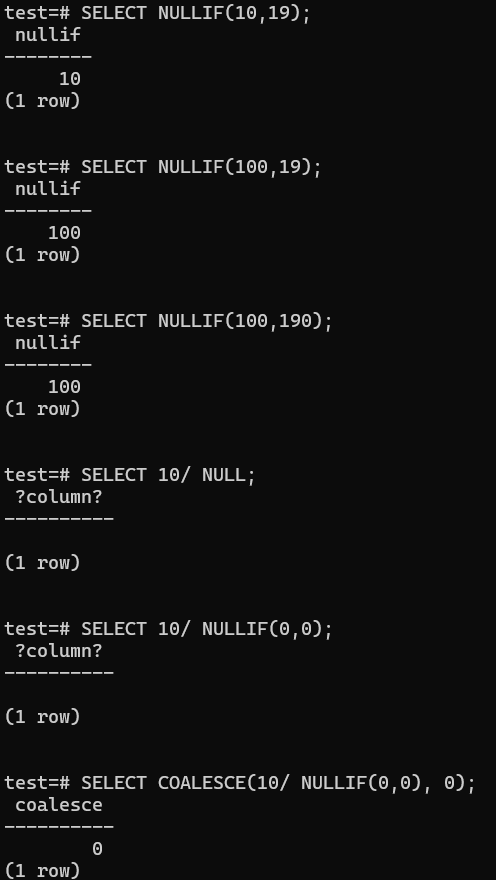
NULLIF
- To tackle the error like in c++ and java here we can use NULLIF. Example,

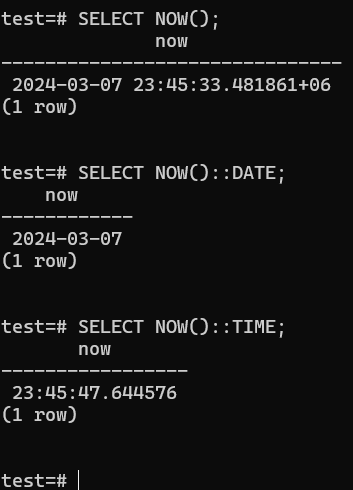
Timestamps and Dates
Adding and Subtracting with DATES
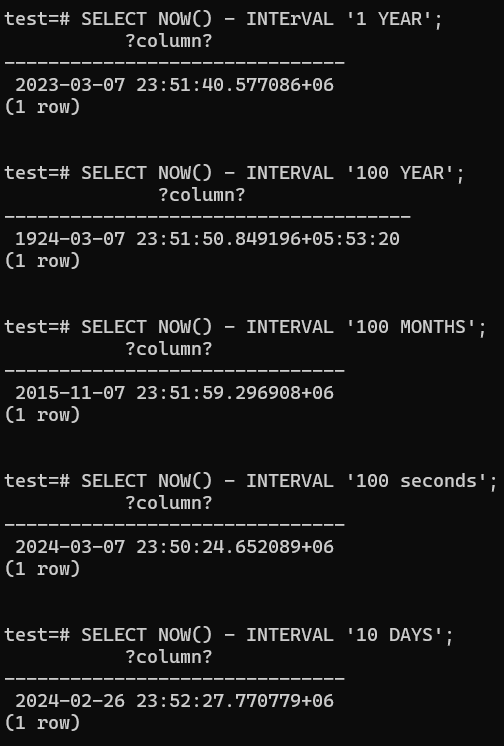
DAY-95 (8/3/2024)
PRIMARY KEY
Its used to uniquely identify record in tables.

Dropping Primary Key contrain
ALTER TABLE person DROP CONSTRAINT person_pkey;
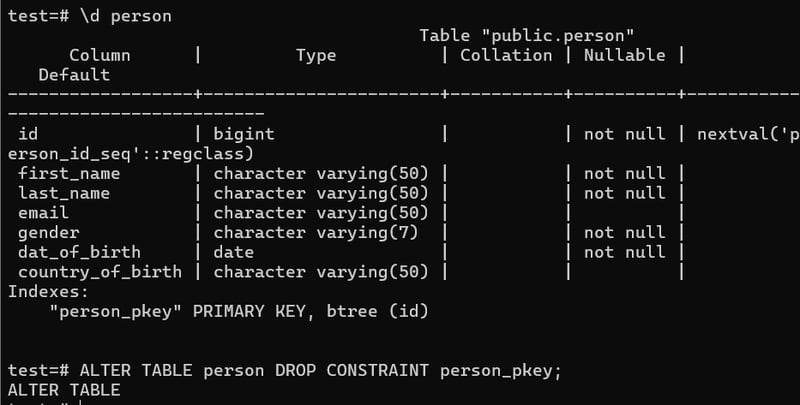
Now we can have different person with same id.
Adding Primary Key
ALTER TABLE person ADD PRIMARY KEY(id);
Unique constraint
ALTER Table person ADD CONSTRAINT <'give a name'> UNIQUE email;
But we can give this command without giving the name. Then it will by default name given by the postgres. ALTER TABLE person ADD UNIQUE(email);
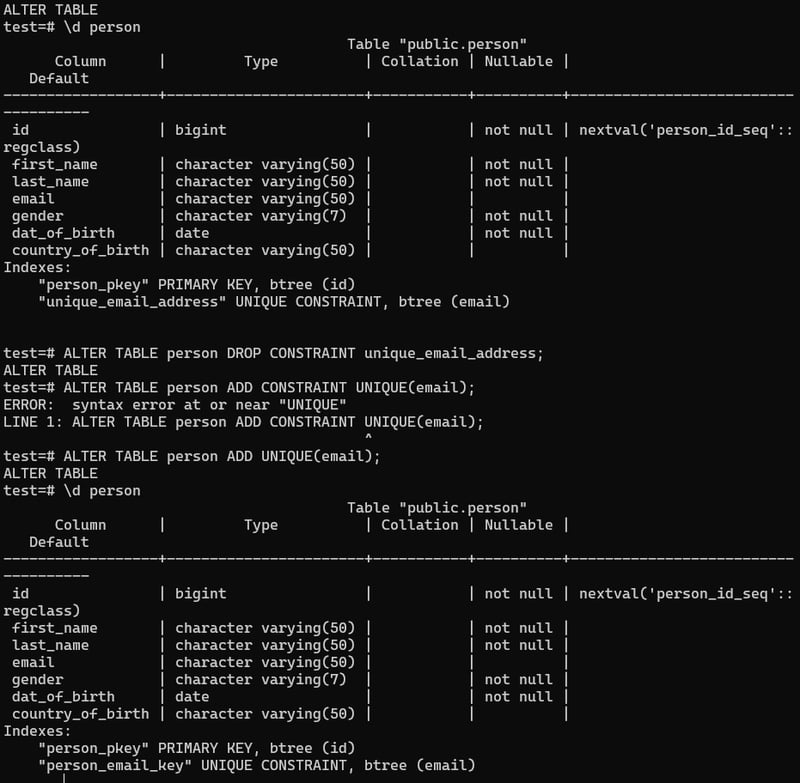

Here we can see, adding unique constraint showing error because previously we inserted new data with same email ID.
Now we can change the email, or make it NULL.
So we are going to delete now,
DELETE FROM person WHERE id = 920;
DAY-96 (9/3/2024)
Check Constraints
It actually helps us to set a constraints, so that every time we insert a new value it have to match with that constraint. Like, Here we have inserted a new value with gender Rifat.
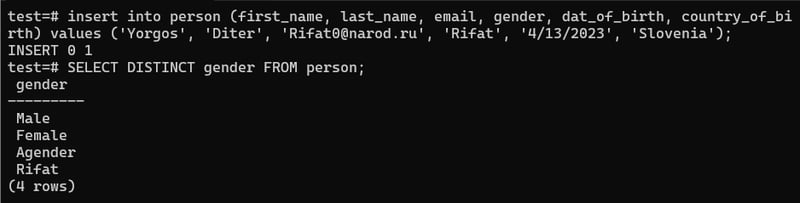
Now, we are going to add the check constraint to our gender . Add constraint name 'gender_constraint' and gender must be equal to 'Male' or 'Female'.
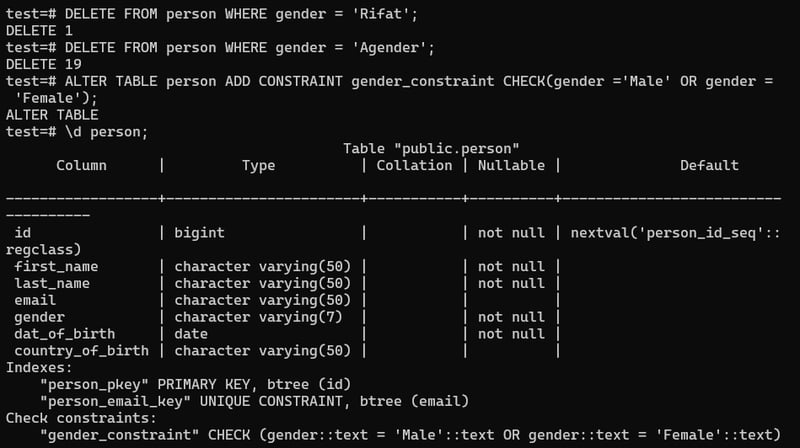
Now if want to insert new data with different gender rather than male and female, then it will show error.

For Droping the Constraint
ALTER TABLE person DROP CONSTRAINT gender_constraint;
DELETE RECORDS
DELETE FROM person WHERE gender = 'Female' AND country_of_birth = 'America' OR email = 'kpeizerb@mail.ru';
DELETE 1
PLEASE dont give DELETE FROM <table name> it will wipe out whole table from the database;
To avoid this use where clause and give conditions as your wish.
DAY-97 (10/3/2024)
UPDATE RECORDS
UPDATE person SET email = 'rifat@gima.com' WHERE id = 200;
Without using WHERE command, we will set the email command to that new email.
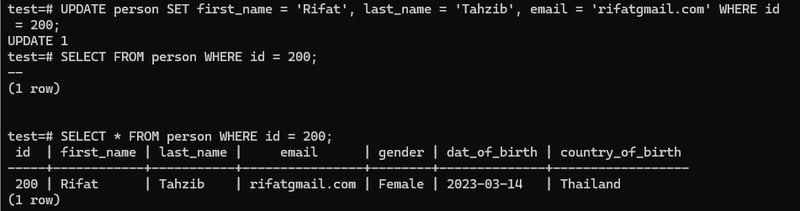
here we can see a demo of update command.
We can easily switch column using (,) and without WHERE clause it will set it to every row.
On Conflict Do Nothing

So, it will match the id. If it matches then it will do nothing.
Upsert

INSERT INTO person(id, first_name, last_name, gender, email, dat_of_birth, country_of_birth) VALUES(200,'Tazbi','Rifat', 'Male', 'email.com', DATE '2032-03-03','Bangl')
test-# ON CONFLICT (id) DO UPDATE SET email = EXCLUDED.email;
INSERT INTO person(id, first_name, last_name, gender, email, dat_of_birth, country_of_birth) VALUES(200,'Tazbi','Rifat', 'Male', 'email.com', DATE '2032-03-03','Bangl')
test-# ON CONFLICT (id) DO UPDATE SET email = EXCLUDED.email, last_name = EXCLUDED.last_name, first_name = EXCLUDED.first_name;
this is also correct.
DAY-98 (11/3/2024)
Foreign Key, Join & Relationship
Adding Relationship between tables
Inserting data with table,
\i 'D:/PostGres/person-car.sql';
Updating Foreign Key
You can only assign a foreign key , when there is a relation with other table.
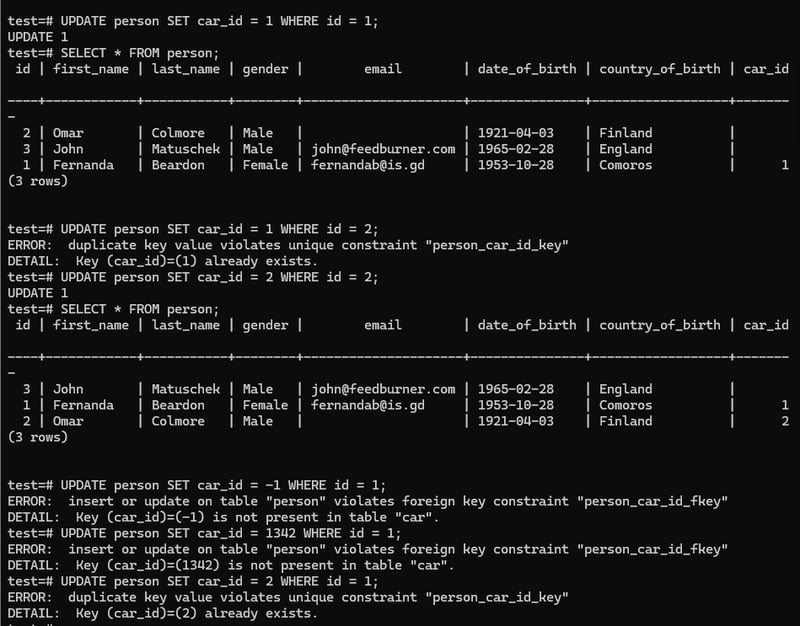
If The primary key value once assign to foreign key, Then we can not assign that value to other column.
INNER JOIN
Its a effective way of combining two tables. It takes two tables and add them up. In result , it will give those which are common in both table.
Showing expanded Display
To turn it on, we just give \x
And for turn of give the same command.
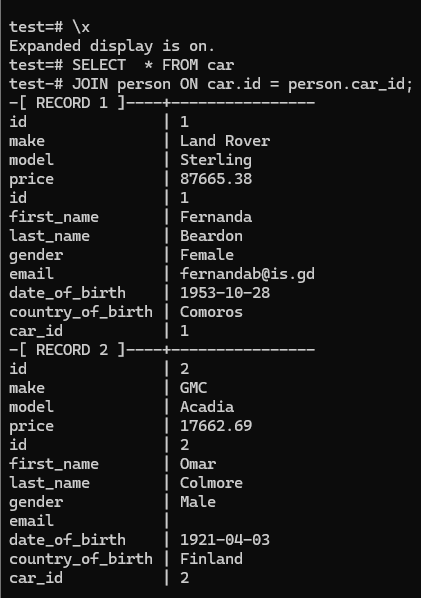
Inner Join vs WHERE clause
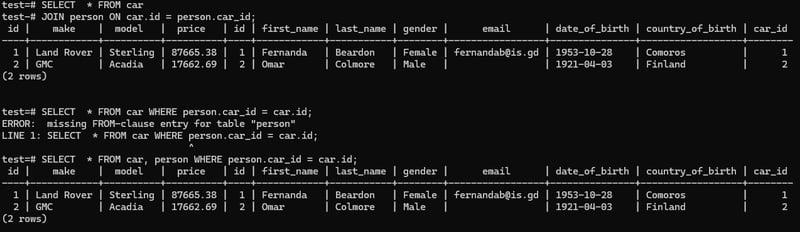
Here we can see, they both gives the same output. Internally both works the same way.
The JOIN command is used to combine rows from two or more tables based on a related column between them. While it's true that you can achieve similar results using a WHERE clause to filter rows based on a common column, there are several reasons why JOIN is often preferred:
Clarity and Readability: Using JOIN explicitly expresses the intention to combine data from multiple tables, making the query more understandable to other developers or to your future self. It improves the readability and maintainability of the SQL code.
Performance Optimization: The query optimizer in the database engine can better understand the relationship between tables when JOIN is used. This can lead to better query execution plans and potentially better performance compared to using multiple WHERE clauses.
Handling Outer Joins: JOIN syntax provides options for different types of joins, such as INNER JOIN, LEFT JOIN, RIGHT JOIN, and FULL OUTER JOIN, which allow you to control how rows are combined, including cases where there may be no matching rows in one of the tables.
Avoiding Cartesian Products: Using JOIN helps prevent unintentional Cartesian products (cross joins) that occur when you forget to specify a join condition. Cartesian products can result in a massive increase in the number of rows returned, which is usually not desired.
Expressiveness: JOIN syntax provides a more expressive way to specify relationships between tables and conditions for joining them. It allows you to separate join conditions from filtering conditions in the WHERE clause, making the query easier to understand.
LEFT JOIN
DAY-99 (12/3/2024)
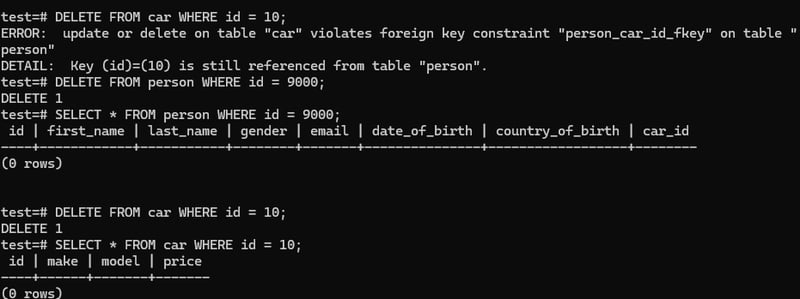
DELETING records with FOREIGN KEYs
updating person car_id:
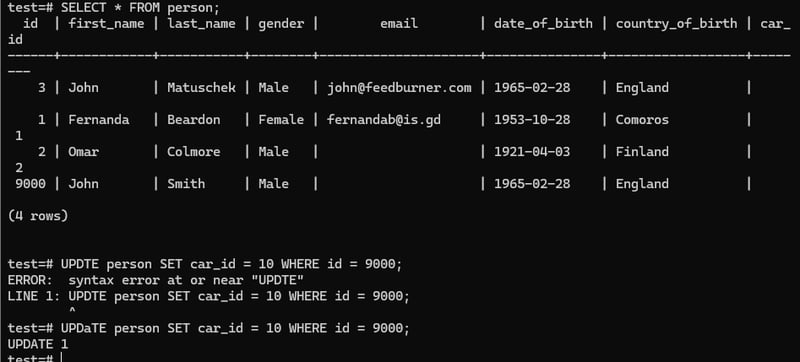
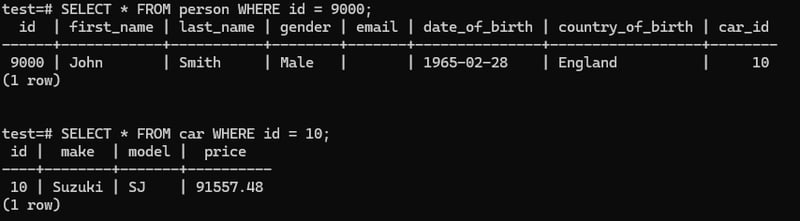
This will not worK: DELETE FROM car WHERE id = 10;

Because here we have value in person table car_id which is a foreign key. So that we can't directly delete a primary key value if it has a relation with foreign key.
So we have 2 ways to delete that primary key value.

We can delete the row in person table. It will no more contain the primary key value.
We can simply update the car_id value in person table and make it null.
- Another way is using cascade. Which will all the data related to Primary key. But it is very
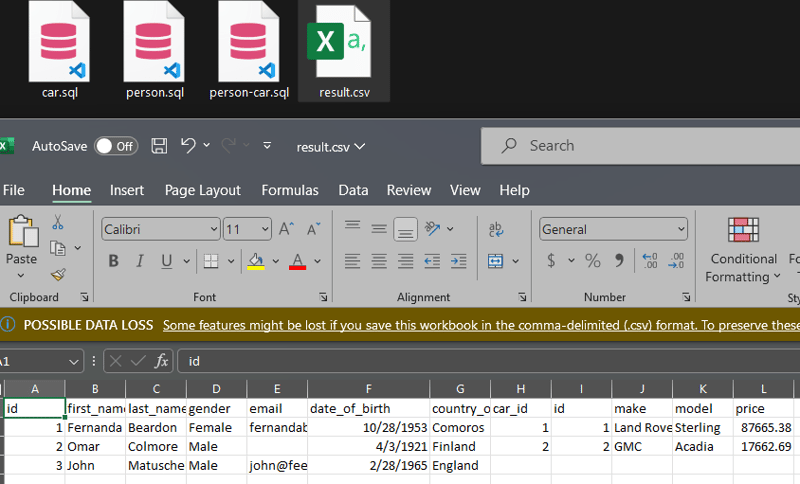
Exporting Query results to CSV

Suppose we want to store this data to a csv file.
- we will use
\copy('give the query comand')\copy (SELECT * FROM person LEFT JOIN car ON car.id = person.car_id) TO 'D:/PostGres/result.csv'DELIMITER ',' CSV HEADER;
DAY-100 (13/3/2024)
Serial & Sequences
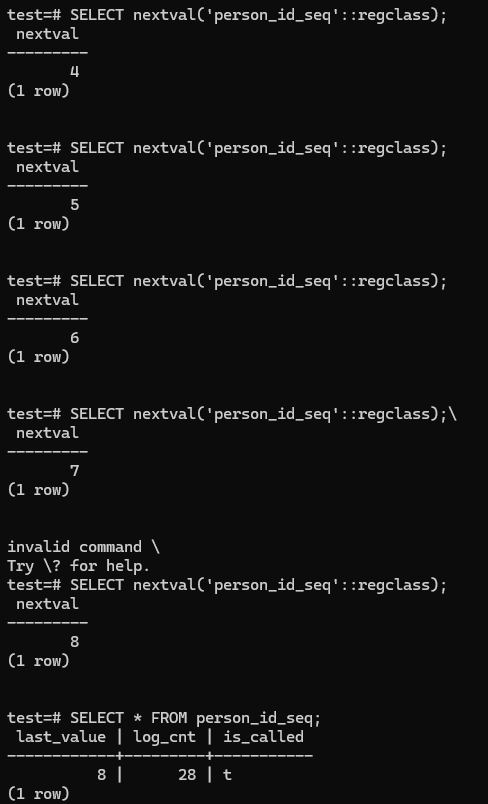
Here we can see, we invoked the sequence value 8 times, so next value we insert will have the id of 9;
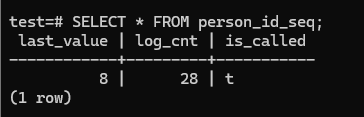
The person table:

After inserting new data:
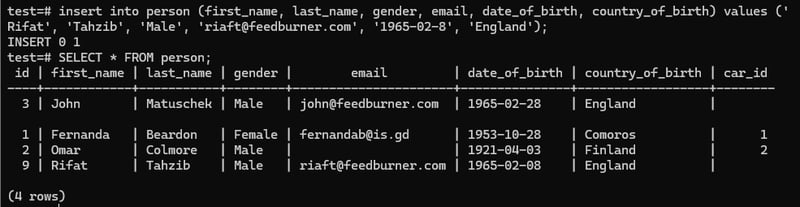
we can see the last data id is 9.
So, if the sequence is too high and we want to go back to a precise seq value then we can do this,
ALTER SEQUENCE person_id_seq RESTART WITH 10;
Now, it will set the sequence to 10. Same way we can set seq to existing sequence value. Like 2 already exist but if we use ALTER SEQUENCE person_id_seq RESTART WITH 2; then it will set the seq to 2. And now if we want to insert in the table then a amazing thing will happen lets see,

It will not give you permission to insert new data in id 2 because of primary key conditions.
Extensions
To see the available extensions in postGres,
SELECT * FROM pg_available_extensions;
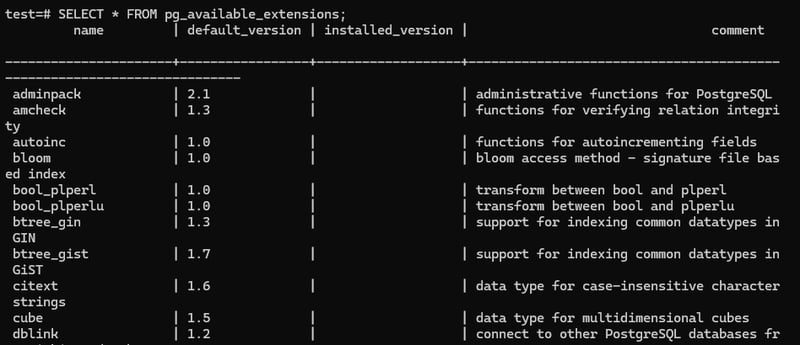
Understanding UUID Data Types
Now we are going to install the extensions. For this the command is:
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";

How to generate UUID:
At first we have to invoke a function(\df).
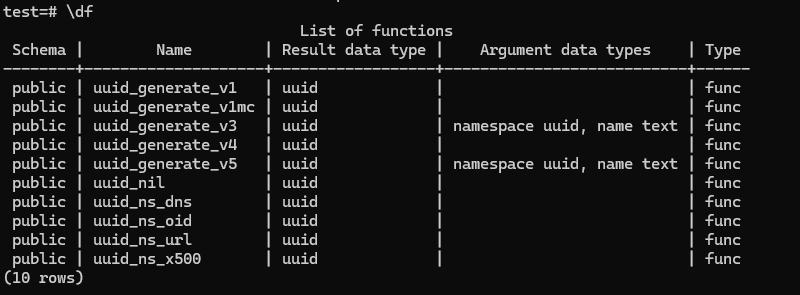
we can now easily call uuid by
SELECT uuid_generate_v4();
This will generate new id every time we call it.
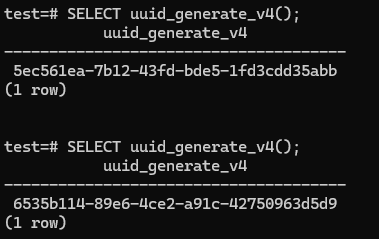
So that, we can easily use it as a Primary Key in out table. And its values are globally UNIQUE.
UUID as PRIMARY KEY
new tables of person and car is caraeted.
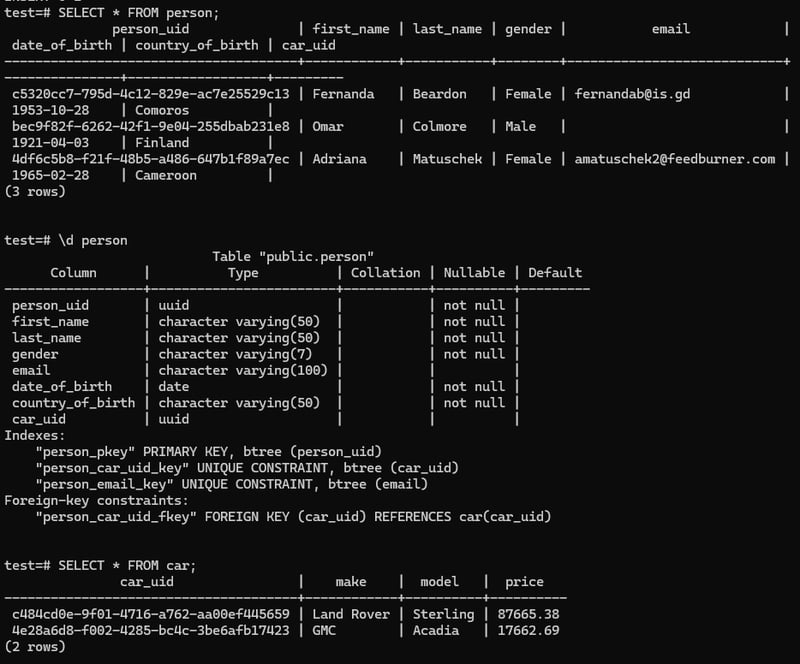
Updating Table value:
UPDATE person SET car_uid = 'c484cd0e-9f01-4716-a762-aa00ef445659' WHERE person_uid = 'c5320cc7-795d-4c12-829e-ac7e25529c13';
Amazing error occure:

We can not put space in uuid value.
so The correct syntax is:
UPDATE person SET car_uid = '4e28a6d8-f002-4285-bc4c-3be6afb17423' WHERE person_uid = 'bec9f82f
-6262-42f1-9e04-255dbab231e8';
Now we perform natural join:
SELECT * FROM person
JOIN car ON car.car_uid = person.car_uid;
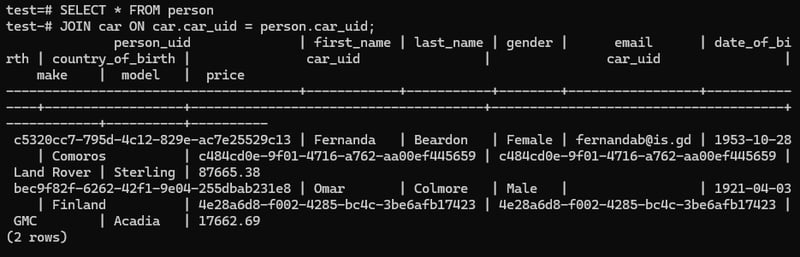
Having same name of PRIMARY KEY and FOREIGN KEY
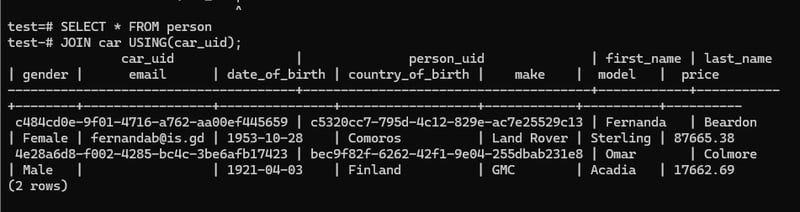
Because the car.car_uid and person.car_uid are same name , so we can use one variable by using USING command. The command will look like,
SELECT * FROM person
JOIN car USING(car_uid);





Top comments (0)