Let’s talk a little bit about indexes, their relation with data pages, and their importance in querying data from databases.
Database indexes are used to provide faster access to relational data. An index is a separated physical data structure that enables faster access to one or multiple rows to an entity or table.
Analogous, we can think of a book index or the yellow pages (phone numbers) as examples of indexes.
So, what it means to have or not have an index?
Well, let’s imagine that we have a table, with a primary key, and no index on it. To find the row(s) we want on the data pages, we’ll blindly start our search with no clue of where to find them. Thus, to ensure that we end on the aimed row(s) successfully, we must start reading sequentially from beginning to end until we find what we want. The higher is the number of rows on the table the higher will be the time consumed on this task. Image what would be to try to find a row in the middle of 1000000.
Here is where indexes are useful… Since they are built in a separated physical data structure, more exactly on a B+-tree structure, will build a sort of “route map” that will perform faster access to data. On average, the operation time complexities will be faster than without indexes.
We can have two types of indexes on our tables:
- Clustered – The B+-tree of a clustered index will be fulfilled with root, intermediary and leaves nodes. The root and intermediary nodes will be in index pages structures, containing a key value and a pointer to the data row on the leaf level, seeking through them in cascading way. This type of index is unique by table and it is created taking in basis the table primary key.
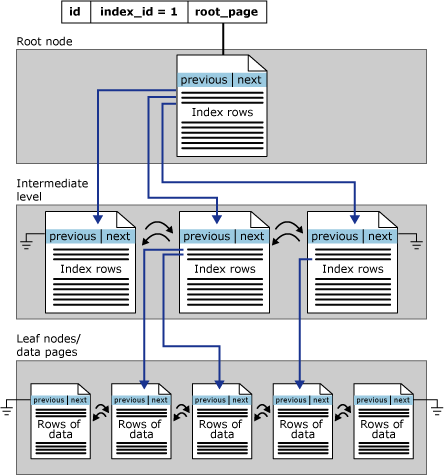
Took from docs.microsoft.com
- Nonclustered – They have the same structure as clustered indexes, having a difference that the leaves are also index pages instead of data pages. For this type of indexes, we have no maximum number for them, but should be taken into consideration that the SQL server will need to balance these B+-tree structures on any insert or delete operation, and these comport and effort. This effort will increase with the number of indexes, therefore these indexes should be added wisely after deeper analysis.
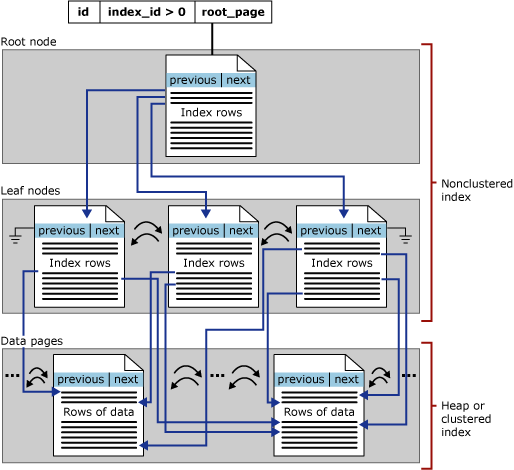
Took from docs.microsoft.com
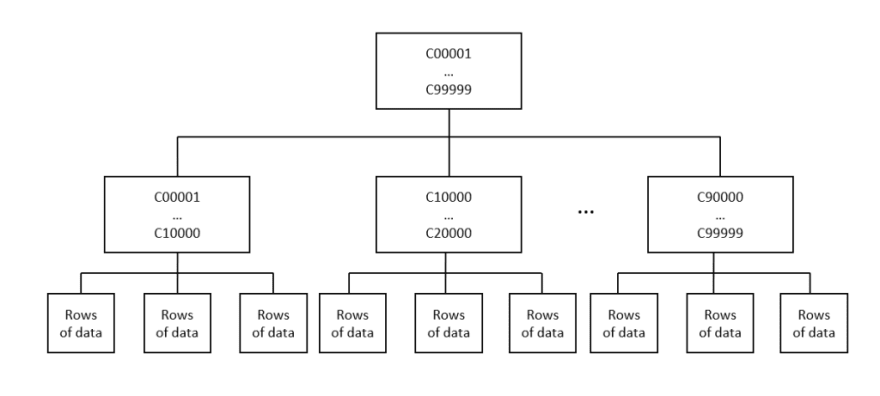
Friendliest representation of Clustered indexes…
Friendliest representation of Nonclustered indexes…
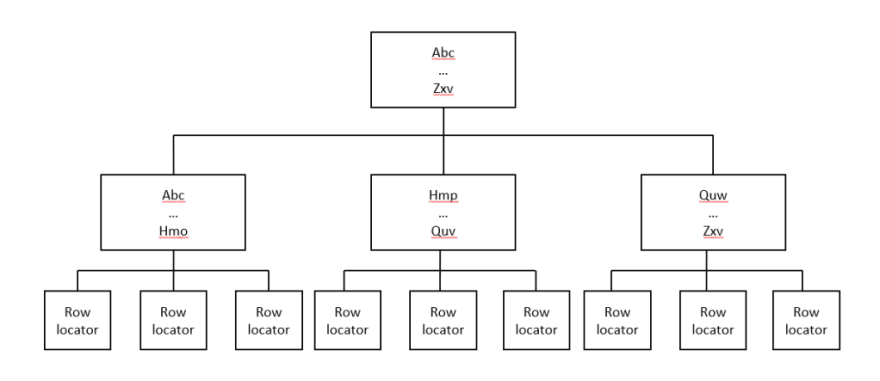
Now, that you know that index pages are a “route map” to faster data page access and how they work, you might end with a final doubt…
Are we able to see how it looks like a data page?
To exemplify what we have inside of a data page, I’ll use the structure created on this post (if you didn’t read it, now it is a good time to jump into it).
Let’s add some dummy data to it…
INSERT INTO dbo.customer (CustomerNo,CustomerFirstName,CustomerLastName,CountryCode)
VALUES (1,'Bruno','Guedes','PT'),
(2,'Marcelo','Sousa','PT'),
(3,'Antonio','Costa','PT');
Now let’s get a look at our table’s page structure by using the following query:
DBCC IND('SampleTest',customer,-1)
GO
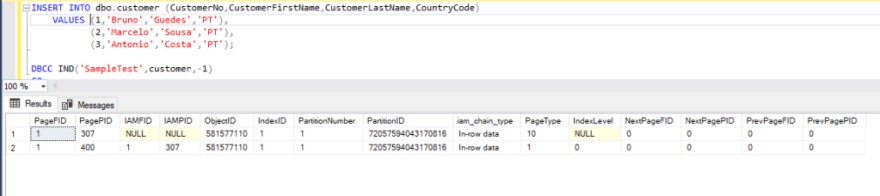
Here we are seeking the rows with PageType 1 that is the type of data page. ( PageType 2 – index pages and PageType 10 – IAM page that maintains the index itself).
Now that we know the PagePID from our data page, let’s use the following query to check the answer to our final doubt…
DBCC TRACEON(3604)
DBCC PAGE('SampleTest',1,400,3) WITH TABLERESULTS
GO
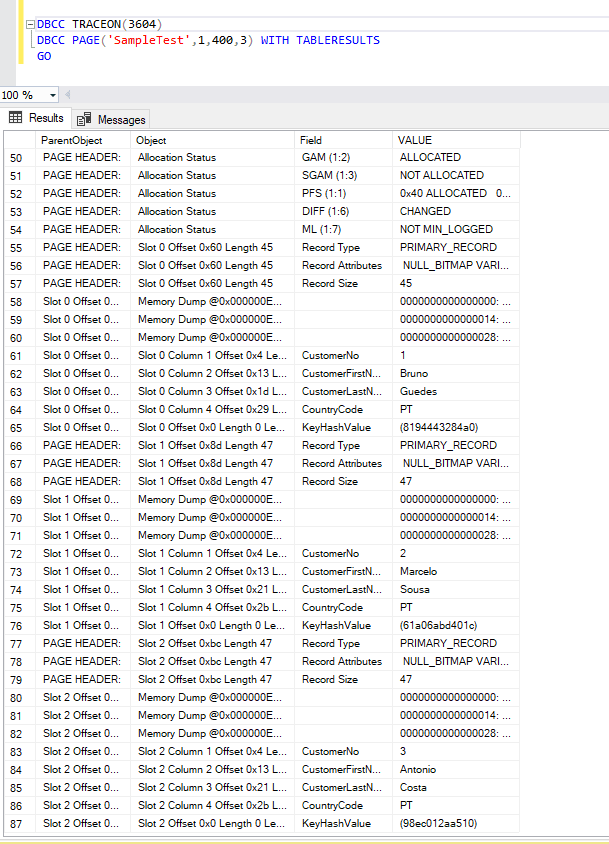
If you scroll until the end you can see that the data rows are stored in slots that start with a zero offset.
And that’s it, the complex monster (aka Indexes), and its herculean relation with data pages ended, in this post, by being diminished for the world. Well, at least hopefully! 
What’s next?
Above you can find a small explanation for the index behavior on SQL server, but if you are looking to dive deeper into the concept I can suggest you the reading of this post from Brent Ozar that is light reading and very explanatory of how indexes act. I can also suggest the reading of the following book that has one chapter fully dedicated to this subject. Good readings!
Stay safe!





Top comments (0)