SQL Reporting Task for Cloudera Flow Management / HDF / Apache NiFi
Would you like to have reporting tasks gathering metrics and sending them to your database or Kafka from NiFi based on a query of NiFi provenance, bulletins, metrics, processor status or other KPI?
Now you can. If you are using HDF 3.5.0, this Reporting task NAR is pre installed and ready to go.
Let's add some Reporting tasks that use SQL!!! QueryNiFiReportingTask.

The first one that was interesting for me was to write queries against provenance for one processor that consumes from a certain topic, I decided to query it every 10 seconds. My query and some results are below.
So let's go to Controller Settings / Reporting Tasks and then add QueryNiFiReportingTask :
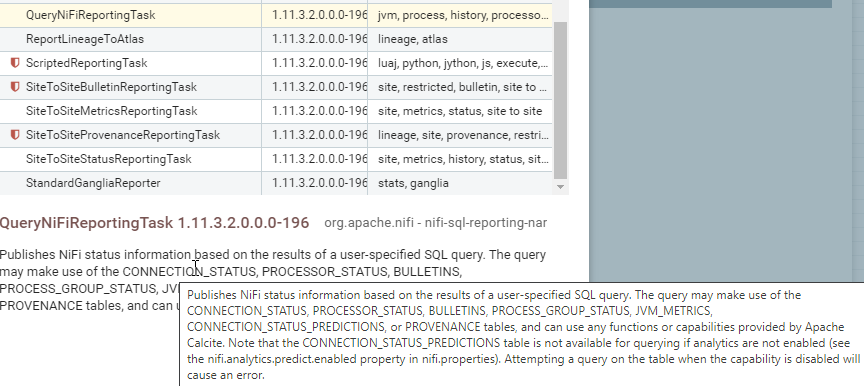
We add one per item we want to monitor. Then for the reporting task we will need a place to send the records (a sink), we can send it to a JDBC Database ( DatabaseRecordSink, KafkaRecordSink, PrometheusRecordSink, ScriptedRecordSink or SiteToSiteReportingRecordSink ). ** ** I am going to do Kafka, but Prometheus, Database and S2S are good options. If you send SiteToSite you can send to another NiFi cluster for processing for that NiFinception processing route,
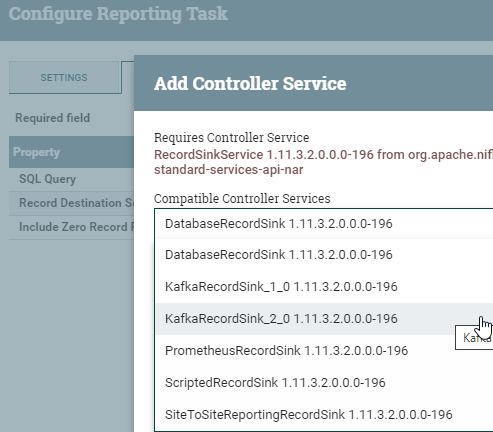
We have to write an Apache Calcite compliant SQL query, set our sink and decide if we want to include zero record results (false is a good idea).
One option is to query the BULLETINS table, which are NiFi Cluster bulletins (warnings/errors).

Another option is the CONNECTION_STATUS table.

How about NiFi JVM Metrics? That has some good stuff in there.

Let's configure some Kafka Record Sinks. I am using Kafka 2.3, so I'll use the Kafka 2 sink. I set some brokers (default port of 9092), create a new topic for it, chose the record writer. I chose JSON, but it could be CSV, AVRO, Parquet, XML or something else. Stick with JSON or AVRO for Kafka.

So data starts getting sent, by default the schedule is every 5 minutes. This can be adjusted, for provenance I set mine to every 10 seconds.

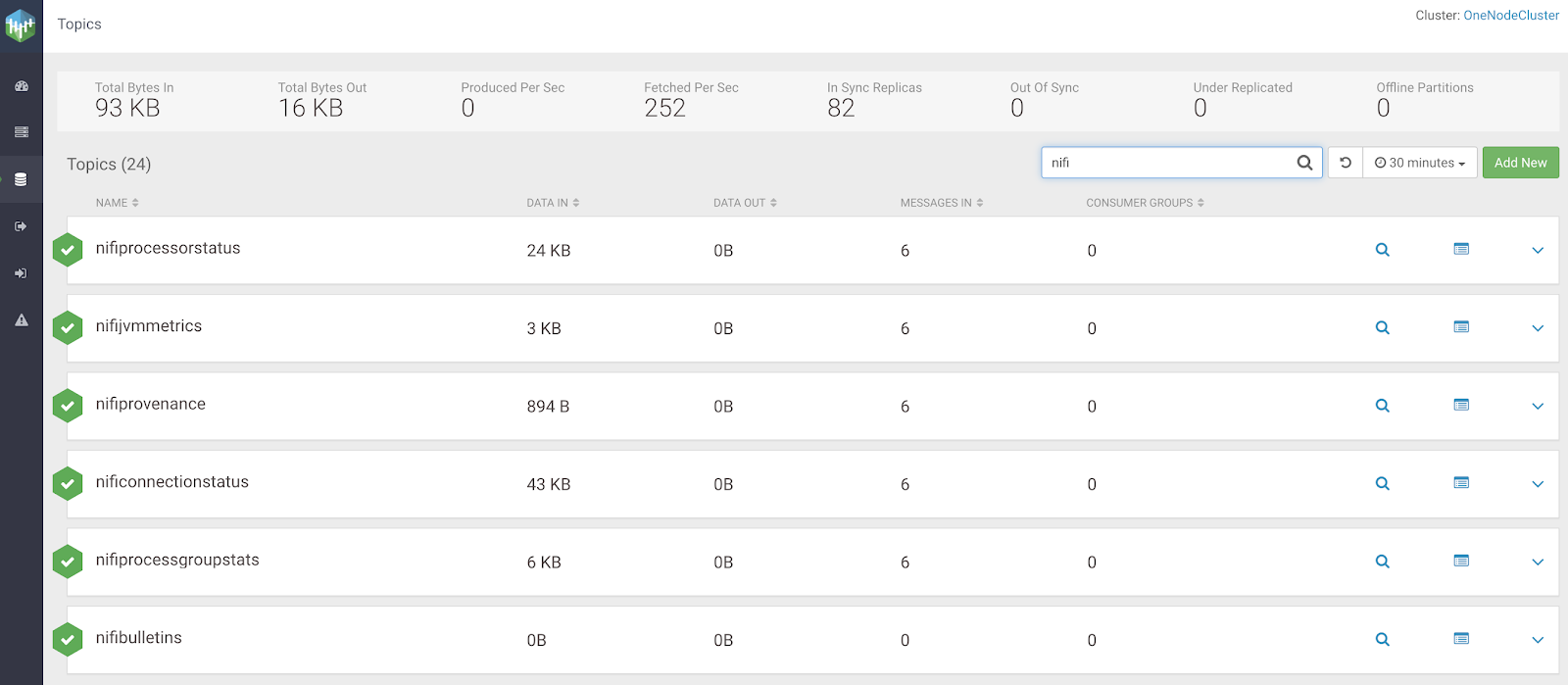
Let's look at data as it passes through Kafka, in the follow up to this article we'll land in Impala/Kudu/Hive/Druid/Phoenix/HBase or HDFS/S3 and query it. For now, we can examine the data within Kafka via Cloudera Streams Messaging Manager (SMM).

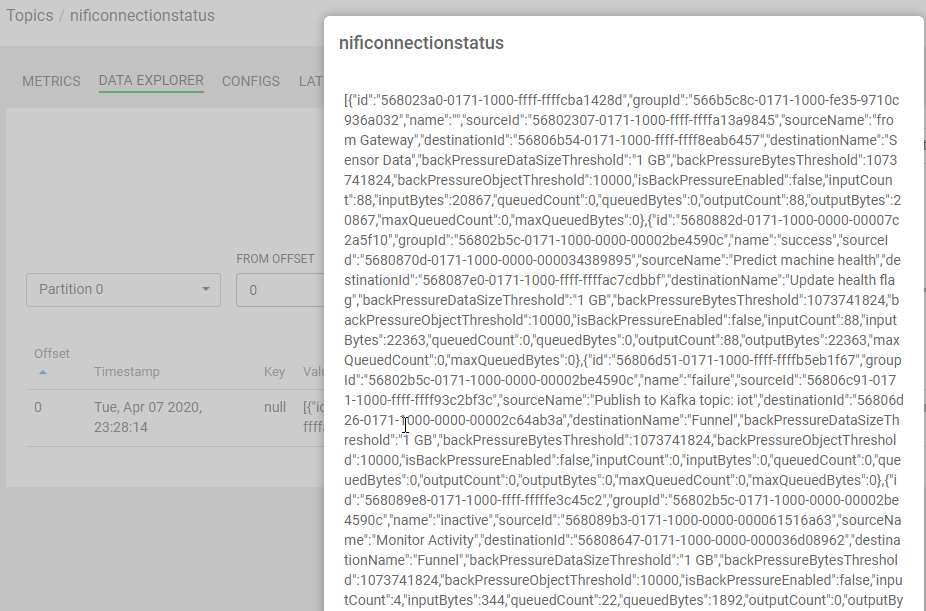

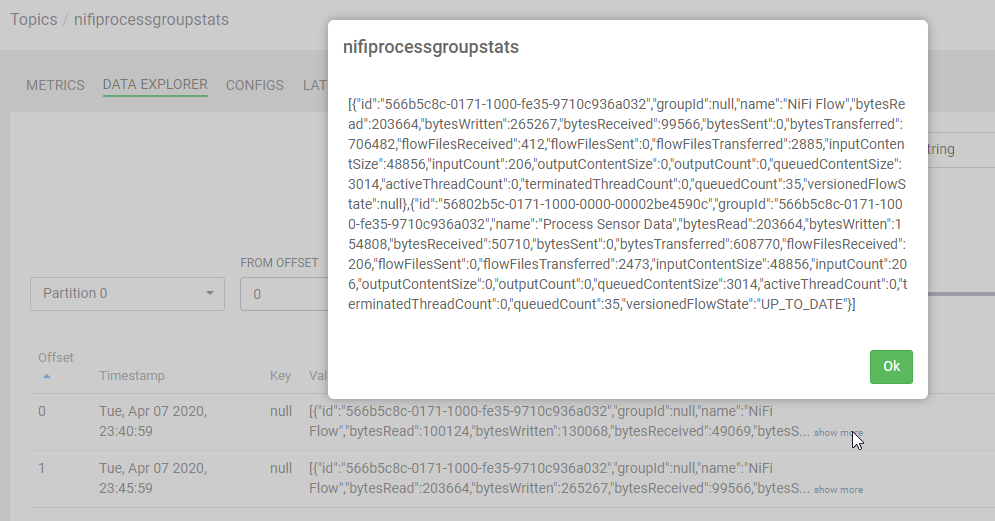


We can examine any of the topics in Kafka with SMM. We can then start consuming these records and build live metric handling applications or send to live data marts and dashboards powered by Cloudera Data Platform (CDP).
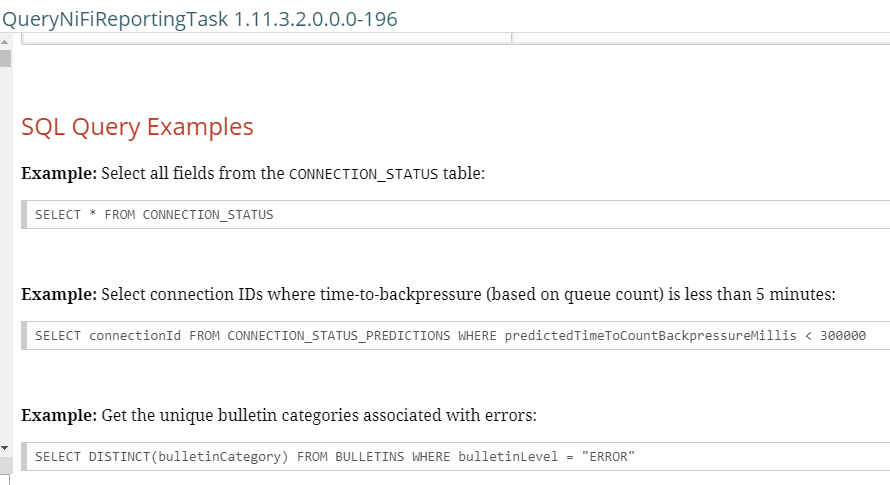
We have a full set of SQL to use for these reporting tasks including selecting columns, doing aggregates like MAX and AVG, ordering, grouping, where clauses and row limits.
Provenance Query
SELECT eventId, durationMillis, lineageStart, timestampMillis,
updatedAttributes, entitySize, details
FROM PROVENANCE
WHERE componentName = 'Consume Kafka iot messages'
LIMIT 25
Provenance Results
[{" eventId":2724," durationMillis":69," lineageStart":1586294707989," timestampMillis":1586294708002," updatedAttributes":"{path=./, schema.protocol.version=1, filename=be499074-c595-46f5-a03a-482607fb9c8c, schema.identifier=1, kafka. partition =7, kafka. offset =36, schema. name =SensorReading, kafka. timestamp =1586294707933, kafka. topic =iot, schema.version=1, mime. type =application/json, uuid=be499074-c595-46f5-a03a-482607fb9c8c}"," entitySize":246,"details":null},{"eventId":2736,"durationMillis":20,"lineageStart":1586294708905,"timestampMillis":1586294708916,"updatedAttributes":"{path=./, schema.protocol.version=1, filename=74c9e28d-82a4-4cea-8331-92b7a4bee1b3, schema.identifier=1, kafka.partition=3, kafka.offset=36, schema.name=SensorReading, kafka.timestamp=1586294708898, kafka.topic=iot, schema.version=1, mime.type=application/json, uuid=74c9e28d-82a4-4cea-8331-92b7a4bee1b3}","entitySize":247,"details":null},..]
I have classes on using this technology and some webinars coming to you in the East Coast of the US and virtually at my meetup.
https://www.meetup.com/futureofdata-princeton/
Cloudera HDF 3.5.0 Is Now Available For Download
https://docs.cloudera.com/HDPDocuments/HDF3/HDF-3.5.0/release-notes/content/whats-new.html
https://www.cloudera.com/downloads/hdf.html
HDF 3.5.0 includes the following components:
- Apache Ambari 2.7.5
- Apache Kafka 2.3.1
- Apache NiFi 1.11.1
- NiFi Registry 0.5.0
- Apache Ranger 1.2.0
- Apache Storm 1.2.1
- Apache ZooKeeper 3.4.6
- Apache MiNiFi Java Agent 0.6.0
- Apache MiNiFi C++ 0.6.0
- Hortonworks Schema Registry 0.8.1
- Hortonworks Streaming Analytics Manager 0.6.0
- Apache Knox 1.0.0
- SmartSense 1.5.0
SQL reporting task. The QueryNiFiReportingTask allows users to execute SQL queries against tables containing information on Connection Status, Processor Status, Bulletins, Process Group Status, JVM Metrics, Provenance and Connection Status Predictions. In combination with Site to Site, it is particularly useful to define fine-grained monitoring capabilities on top of the running workflows.




Top comments (1)
We noticed that QueryReportingTask include zero record for Process_GROUP_STATUS and PROCESSOR_STATUS and CONNECTION_STATUS does not work, it give zero records also. Is there any way to fix it?