
The importance of testing in modern software development is really hard to overstate. Delivering a successful product is not something you do once and forget about but is rather a continuous recurring process. With every line of code that changes, software must remain in a functional state, which implies the need for rigorous testing.
Over time, as the software industry evolved, testing practices have matured as well. Gradually moving towards automation, testing approaches have also influenced software design itself, spawning mantras like test-driven development, emphasizing patterns such as dependency inversion, and popularizing high-level architectures that are built around it.
Nowadays, automated testing is embedded so deeply within our perception of software development, it's hard to imagine one without the other. And since that ultimately enables us to produce software quickly without sacrificing quality, it's hard to argue that it's not a good thing.
However, despite there being many different approaches, modern "best practices" primarily push developers specifically towards unit testing. Tests, whose scope lies higher on Mike Cohn's pyramid are either written as part of a wider suite (often by completely different people) or even disregarded entirely.
The benefit of this approach is often supported by the argument that unit tests provide the most value during development because they're able to catch errors quickly and help enforce design patterns that facilitate modularity. This idea has become so widely accepted that the term "unit testing" is now somewhat conflated with automated testing in general, losing part of its meaning and contributing to confusion.
When I was a less experienced developer, I believed in following these "best practices" to the letter, as I thought that would make my code better. I didn't particularly enjoy writing unit tests because of all the ceremony involved with abstractions and mocking, but it was the recommended approach after all, so who am I to know better.
It was only later, as I've experimented more and built more projects, that I started to realize that there are much better ways to approach testing and that focusing on unit tests is, in most cases, a complete waste of time.
Aggressively popularized "best practices" often have a tendency of manifesting cargo cults around them, enticing developers to apply design patterns or use specific approaches without giving them a much needed second thought. In the context of automated testing, I find this prevalent when it comes to our industry's unhealthy obsession with unit testing.
In this article I will share my observations about this testing technique and go over why I believe it to be inefficient. I'll also explain which approaches I'm currently using instead to test my code, both in open source projects and day-to-day work.
Note: this article contains code examples which are written in C#, but the language itself is not (too) important to the points I'm making.
Note 2: I've come to realize that programming terms are completely useless at conveying meanings because everyone seems to understand them differently. In this article I will be relying on the "standard" definitions, where unit testing targets smallest separable parts of code, end-to-end testing targets software's outermost entry points, while integration testing is for everything in-between.
Fallacies of unit testing
Unit tests, as evident by the name, revolve around the concept of a "unit", which denotes a very small isolated part of a larger system. There is no formal definition of what a unit is or how small it should be, but it's mostly accepted that it corresponds to an individual function of a module (or method of an object).
Normally, when the code isn't written with unit tests in mind, it may be impossible to test some functions in complete isolation because they can have external dependencies. In order to work around this issue, we can apply the dependency inversion principle and replace concrete dependencies with abstractions. These abstractions can then be substituted with real or fake implementations, depending on whether the code is executing normally or as part of a test.
Besides that, unit tests are expected to be pure. For example, if a function contains code that writes data to the file system, that part needs to be abstracted away as well, otherwise the test that verifies such behavior will be considered an integration test instead, since its coverage extends to the unit's integration with the file system.
Considering the factors mentioned above, we can reason that unit tests are only useful to verify pure business logic inside of a given function. Their scope does not extend to testing side-effects or other integrations because that belongs to the domain of integration testing.
To illustrate how these nuances affect design, let's take a look at an example of a simple system that we want to test. Imagine we're working on an application that calculates local sunrise and sunset times, which it does through the help of the following two classes:
public class LocationProvider : IDisposable
{
private readonly HttpClient _httpClient = new HttpClient();
// Gets location by query
public async Task<Location> GetLocationAsync(string locationQuery) { /* ... */ }
// Gets current location by IP
public async Task<Location> GetLocationAsync() { /* ... */ }
public void Dispose() => _httpClient.Dispose();
}
public class SolarCalculator : IDiposable
{
private readonly LocationProvider _locationProvider = new LocationProvider();
// Gets solar times for current location and specified date
public async Task<SolarTimes> GetSolarTimesAsync(DateTimeOffset date) { /* ... */ }
public void Dispose() => _locationProvider.Dispose();
}
Although the design above is perfectly valid in terms of OOP, neither of these classes are actually unit-testable. Because LocationProvider depends on its own instance of HttpClient and SolarCalculator in turn depends on LocationProvider, it's impossible to isolate the business logic that may be contained within methods of these classes.
Let's iterate on that code and replace concrete implementations with abstractions:
public interface ILocationProvider
{
Task<Location> GetLocationAsync(string locationQuery);
Task<Location> GetLocationAsync();
}
public class LocationProvider : ILocationProvider
{
private readonly HttpClient _httpClient;
public LocationProvider(HttpClient httpClient) =>
_httpClient = httpClient;
public async Task<Location> GetLocationAsync(string locationQuery) { /* ... */ }
public async Task<Location> GetLocationAsync() { /* ... */ }
}
public interface ISolarCalculator
{
Task<SolarTimes> GetSolarTimesAsync(DateTimeOffset date);
}
public class SolarCalculator : ISolarCalculator
{
private readonly ILocationProvider _locationProvider;
public SolarCalculator(ILocationProvider locationProvider) =>
_locationProvider = locationProvider;
public async Task<SolarTimes> GetSolarTimesAsync(DateTimeOffset date) { /* ... */ }
}
By doing so we were able to decouple LocationProvider from SolarCalculator, but in exchange our code nearly doubled in size. Also note that we had to drop IDisposable from both classes because they no longer own their dependencies and thus have no business taking responsibility for their lifecycle.
While these changes may seem as an improvement to some, it's important to point out that the interfaces we've defined serve no practical purpose other than making unit testing possible. There's no need for actual polymorphism in our design, so, as far as our code is concerned, these abstractions are autotelic.
Let's try to reap the benefits of all that work and write a unit test for SolarCalculator.GetSolarTimesAsync:
public class SolarCalculatorTests
{
[Fact]
public async Task GetSolarTimesAsync_ForKyiv_ReturnsCorrectSolarTimes()
{
// Arrange
var location = new Location(50.45, 30.52);
var date = new DateTimeOffset(2019, 11, 04, 00, 00, 00, TimeSpan.FromHours(+2));
var expectedSolarTimes = new SolarTimes(
new TimeSpan(06, 55, 00),
new TimeSpan(16, 29, 00)
);
var locationProvider = Mock.Of<ILocationProvider>(lp =>
lp.GetLocationAsync() == Task.FromResult(location)
);
var solarCalculator = new SolarCalculator(locationProvider);
// Act
var solarTimes = await solarCalculator.GetSolarTimesAsync(date);
// Assert
solarTimes.Should().BeEquivalentTo(expectedSolarTimes);
}
}
Here we have a basic test that verifies that SolarCalculator works correctly for a known location. Since unit tests and their units are tightly coupled, we're following the recommended naming convention, where the test class is named after the class under test, and the name of the test method follows the Method_Precondition_Result pattern.
In order to simulate the desired precondition in the arrange phase, we have to inject corresponding behavior into the unit's dependency, ILocationProvider. In this case we do that by substituting the return value of GetLocationAsync() with a location for which the correct solar times are already known ahead of time.
Note that although ILocationProvider exposes two different methods, from the contract perspective we have no way of knowing which one actually gets called. This means that by choosing to mock a specific one of these methods, we are making an assumption about the underlying implementation of the method we're testing (which was deliberately hidden in the previous snippets).
All in all, the test does correctly verify that the business logic inside GetSolarTimesAsync works as expected. However, let's expand on some of the observations we've made in the process.
- Unit tests have a limited purpose
It's important to understand that the purpose of any unit test is very simple: verify business logic in an isolated scope. Depending on which interactions you intend to test, unit testing may or may not be the right tool for the job.
For example, does it make sense to unit test a method that calculates solar times using a long and complicated mathematical algorithm? Most likely, yes.
Does it make sense to unit test a method that sends a request to a REST API to get geographical coordinates? Most likely, not.
If you treat unit testing as a goal in itself, you will quickly find that, despite putting a lot of effort, most tests will not be able to provide you with the confidence you need, simply because they're testing the wrong thing. In many cases it's much more beneficial to test wider interactions with integration tests, rather than focusing specifically on unit tests.
Interestingly, some developers do end up writing integration tests in such scenarios, but still refer to them as unit tests, mostly due to confusion surrounding the concept. Although it could be argued that a unit size can be chosen arbitrarily and can span multiple components, this makes the definition very fuzzy, ultimately just turning overall usage of the term completely useless.
- Unit tests lead to more complicated design
One of the most popular arguments in favor of unit testing is that it enforces you to design software in a highly modular way. This builds on an assumption that it's easier to reason about code when it's split into many smaller components rather than a few larger ones.
However, it often leads to the opposite problem, where the functionality may end up becoming unnecessarily fragmented. This makes it much harder to assess the code because a developer needs to scan through multiple components that make up what should have been a single cohesive element.
Additionally, the abundant usage of abstraction, which is required to achieve component isolation, creates a lot of unneeded indirection. Although an incredibly powerful and useful technique in itself, abstraction inevitably increases cognitive complexity, making it further more difficult to reason about the code.
Through that indirection we also end up losing some degree of encapsulation that we were able to maintain otherwise. For example, the responsibility of managing lifetimes of individual dependencies shifts from components that contain them to some other unrelated service (usually the dependency container).
Some of that infrastructural complexity can be also delegated to a dependency injection framework, making it easier to configure, manage, and activate dependencies. However, that reduces portability, which may be undesirable in some cases, for example when writing a library.
At the end of the day, while it's clear that unit testing does influence software design, it's highly debatable whether that's really a good thing.
- Unit tests are expensive
Logically, it would make sense to assume that, since they are small and isolated, unit tests should be really easy and quick to write. Unfortunately, this is just another fallacy that seems to be rather popular, especially among managers.
Even though the previously mentioned modular architecture lures us into thinking that individual components can be considered separately from each other, unit tests don't actually benefit from that. In fact, the complexity of a unit test only grows proportionally to the number of external interactions the unit has, due to all the work that you must do to achieve isolation while still exercising required behavior.
The example illustrated previously in this article is very simple, but in a real project it's not unusual to see the arrange phase spanning many long lines, just to set preconditions for a single test. In some cases, the mocked behavior can be so complex, it's almost impossible to unravel it back to figure out what it was supposed to do.
Besides that, unit tests are by design very tightly coupled to the code they're testing, which means that any effort to make a change is effectively doubled as the test suite needs to be updated as well. What makes this worse is that very few developers seem to find doing that an enticing task, often just pawning it off to more junior members on the team.
- Unit tests rely on implementation details
The unfortunate implication of mock-based unit testing is that any test written with this approach is inherently implementation-aware. By mocking a specific dependency, your test becomes reliant on how the code under test consumes that dependency, which is not regulated by the public interface.
This additional coupling often leads to unexpected issues, where seemingly non-breaking changes can cause tests to start failing as mocks become out of date. It can be very frustrating and ultimately discourages developers from trying to refactor code, because it's never clear whether the error in test comes from an actual regression or due to being reliant on some implementation detail.
Unit testing stateful code can be even more tricky because it may not be possible to observe mutations through the publicly exposed interface. To work around this, you would normally inject spies, which is a type of mocked behavior that records when a function is called, helping you ensure that the unit uses its dependencies correctly.
Of course, when you not only rely on a specific function being called, but also on how many times it happened or which arguments were passed, the test becomes even more coupled to the implementation. Tests written in such way are only useful if the internal specifics are not ever expected to change, which is a highly unreasonable expectation to have.
Relying too much on implementation details also makes the tests themselves very complex, considering how much setup is required to configure mocks in order to simulate a specific behavior, especially when the interactions are not that trivial or when there are a lot of dependencies. When the tests get so complicated that their own behavior is hard to reason about, who is going to write tests to test the tests?
- Unit tests don't exercise user behavior
No matter what type of software you're developing, its goal is to provide value for the end user. In fact, the primary reason why we're writing automated tests in the first place is to ensure that there are no unintended defects that would diminish that value.
In most cases, the user works with the software through some top-level interface such as a UI, CLI, or API. While the code itself might involve numerous layers of abstractions, the only one that matters to the user is the one they get to actually see and interact with.
It doesn't even matter if a few layers deep there's a bug in some part of the system, as long as it never surfaces to the user and doesn't affect the provided functionality. Conversely, it makes no difference that we may have full coverage on all the lower-level pieces, if there's a defect in the user interface that renders our system effectively useless.
Of course, if you want to ensure that something works correctly, you have to check that exact thing and see if it does. In our case, the best way to gain confidence in the system is to simulate how a real user would interact with the top-level interface and see if it works properly according to expectations.
The problem with unit tests is that they're the exact opposite of that. Since we're always dealing with small isolated pieces of our code that the user doesn't directly interact with, we never test the actual user behavior.
Doing mock-based testing puts the value of such tests under an even bigger question, because the parts of our system that would've been used otherwise are replaced with mocks, further distancing the simulated environment from reality. It's impossible to gain confidence that the user will have a smooth experience by testing something that doesn't resemble that experience.

Pyramid-driven testing
So why would we, as an industry, decide that unit testing should be the primary method of testing software, given all of its existing flaws? For the most part, it's because testing at higher levels has always been considered too hard, slow, and unreliable.
If you refer to the traditional test pyramid, you will find that it suggests that the most significant part of testing should be performed at the unit level. The idea is that, since coarse-grained tests are assumed to be slower and more complicated, you will want to concentrate efforts towards the bottom of the integration spectrum to end up with an efficient and maintainable test suite:
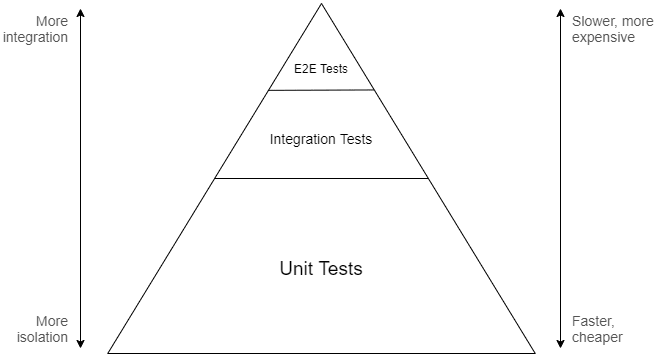
The metaphorical model offered by the pyramid is meant to convey that a good testing approach should involve many different layers, because focusing on the extremes can lead to issues where the tests are either too slow and unwieldy, or are useless at providing any confidence. That said, the lower levels are emphasized as that's where the return on investment for development testing is believed to be the highest.
Top-level tests, despite providing the most confidence, often end up being slow, hard to maintain, or too broad to be included as part of typically fast-paced development flow. That's why, in most cases, such tests are instead maintained separately by dedicated QA specialists, as it's usually not considered to be the developer's job to write them.
Integration testing, which is an abstract part of the spectrum that lies somewhere between unit testing and complete end-to-end testing, is quite often just disregarded entirely. Because it's not really clear what exact level of integration is preferable, how to structure and organize such tests, or for the fear that they might get out of hand, many developers prefer to avoid them in favor of a more clear-cut extreme which is unit testing.
For these reasons, all testing done during development typically resides at the very bottom of the pyramid. In fact, over time this has become so commonplace that development testing and unit testing are now practically synonymous with each other, leading to confusion that is only further perpetuated by conference talks, blog posts, books, and even some IDEs (all tests are unit tests, as far as JetBrains Rider is concerned).
In the eyes of most developers, the test pyramid looks somewhat like this instead:

While the pyramid is a noble attempt to turn software testing into a solved problem, there are obviously many issues with this model. In particular, the assumptions it relies on might not be true for every context, especially the premise of highly integrated test suites being slow or hard.
As humans, we are naturally inclined to rely on information passed on to us from those who are more experienced, so that we can benefit from the knowledge of past generations and apply our second thinking system on something more useful instead. This is an important evolutionary trait that makes our species extremely fit for survival.
However, whenever we extrapolate experiences into guidelines, we tend to think of them as being good on their own, forgetting about the circumstances that are integral to their relevancy. The reality is that circumstances change, and once perfectly reasonable conclusions (or best practices) might not apply so well anymore.
If we look back, it's clear that high-level testing was tough in 2000, it probably still was in 2009, but it's 2020 outside and we are, in fact, living in the future. Advancements in technology and software design have made it a much less significant issue than it once was.
Most modern application frameworks nowadays provide some sort of separate API layer used for testing, where you can run your application in a simulated in-memory environment that is very close to the real one. Virtualization tools like Docker also make it possible to execute tests that rely on actual infrastructural dependencies, while still remaining deterministic and fast.
We have solutions like Mountebank, WireMock, GreenMail, Appium, Selenium, Cypress, and countless others that simplify different aspects of high-level testing that were once considered unapproachable. Unless you're developing desktop applications for Windows and are stuck with UIAutomation framework, you will likely have many options available.
On one of my previous projects, we had a web service which was tested at the system boundary using close to a hundred behavioral tests that took just under 10 seconds to run in parallel. Sure, it's possible to get much faster execution time than that with unit tests but given the confidence they provide this was a no-brainer.
The slow test fallacy is, however, not the only false assumption that the pyramid is based on. The idea of having the majority of testing concentrated at the unit level only works out if those tests actually provide value, which of course depends on how much business logic is contained within the code under test.
Some applications may have a lot of business logic (e.g. payroll systems), some may have close to none (e.g. CRUD apps), most are somewhere in between. Majority of the projects I've personally worked on didn't have nearly enough of it to warrant extensive coverage with unit tests but had plenty of infrastructural complexity on the other hand, which would benefit from integration testing.
Of course, in an ideal world one would evaluate the context of the project and come up with a testing approach that is most suitable for the problem at hand. In reality, however, most developers don't even begin to think about it at all, instead just blindly stacking mountains of unit tests following what the best practices seemingly advise you to do.
Finally, I think it's fair to say, the model provided by the test pyramid is just too simplistic in general. The vertical axes present the testing spectrum as a linear scale, where any gain in confidence you get by going up is apparently offset by an equivalent amount of loss in maintainability and speed. This may be true if you compare the extremes, but not necessarily so for the rest of the points in between.
It also doesn't account for the fact that isolation has a cost in itself and isn't something that comes for free simply by "avoiding" external interactions. Given how much effort it takes to write and maintain mocks, it's entirely possible that a less-isolated test can be cheaper and end up providing more confidence, albeit running slightly slower.
If you consider these aspects, it seems likely that the scale is not linear after all and that the point of highest return on investment resides somewhere closer to the middle rather than at the unit level:
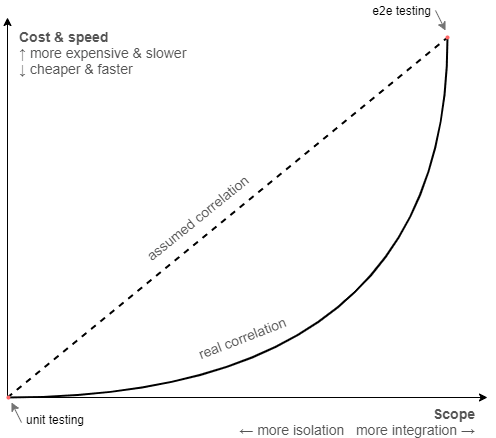
All in all, when you're trying to establish an efficient test suite for your project, the test pyramid isn't the best guideline you can follow. It makes a lot more sense to focus on what's relevant specifically to your context, instead of relying on "best practices".
Reality-driven testing
At the most basic level, a test provides value if it grants certainty that the software is working correctly. The more confident we feel, the less we have to rely on ourselves to spot potential bugs and regressions while introducing changes in code, because we trust our tests to do that for us.
That trust in turn depends on how accurately the test resembles the actual user behavior. A test scenario operating at the system boundary without knowledge of any internal specifics is bound to provide us with greater confidence (and thus, value) than a test working at a lower level.
In essence, the degree of confidence we gain from tests is the primary metric by which their value should be measured. Pushing it as high as possible is also the primary goal.
Of course, as we know, there are other factors in play as well, such as cost, speed, ability to parallelize, and whatnot, which are all important. The test pyramid makes strong assumptions about how these things scale in relation to each other, but these assumptions are not universal.
Moreover, these factors are also secondary to the primary goal of obtaining confidence. An expensive test that takes a really long time to run but provides a lot of confidence is still infinitely more useful than an extremely fast and simple test that does nothing.
For that reason, I find it best to write tests that are as highly integrated as possible, while keeping their speed and complexity reasonable.
Does this mean that every test we write should be an end-to-end test? No, but we should be trying to get as far as we can in that direction, while keeping the downsides at an acceptable level.
What's acceptable or not is subjective and depends on the context. At the end of the day, it's important that those tests are written by developers and are used during development, which means they shouldn't feel like a burden to maintain and it should be possible to run them for local builds and on CI.
Doing this also means that you will likely end up with tests that are scattered across different levels of the integration scale, with seemingly no clear sense of structure. This isn't an issue we would have had with unit testing, because there each test is coupled to a specific method or a function, so the structure usually ends up mirroring that of the code itself.
Fortunately, this doesn't matter because organizing tests by individual classes or modules is not important in itself but is rather a side-effect of unit testing. Instead, the tests should be partitioned by the actual user-facing functionality that they are meant to verify.
Such tests are often called functional because they are based on the software's functional requirements that describe what features it has and how they work. Functional testing is not another layer on the pyramid, but instead a completely orthogonal concept.
Contrary to the popular belief, writing functional tests does not require you to use Gherkin or a BDD framework, but can be done with the very same tools that are typically used for unit testing. For example, consider how we can rewrite the example from the beginning of the article so that the tests are structured around supported user behavior rather than units of code:
public class SolarTimesSpecs
{
[Fact]
public async Task User_can_get_solar_times_automatically_for_their_location() { /* ... */ }
[Fact]
public async Task User_can_get_solar_times_during_periods_of_midnight_sun() { /* ... */ }
[Fact]
public async Task User_can_get_solar_times_if_their_location_cannot_be_determined() { /* ... */ }
}
Note that the actual implementation of the tests is hidden because it's not relevant to the fact that they're functional. What matters is that the tests and their structure are driven by the software requirements, while their scope can theoretically range anywhere from end-to-end to even unit level.
Naming tests in accordance to specifications rather than classes has an additional advantage of removing that unnecessary coupling. Now, if we decide to rename SolarCalculator to something else or move it to a different directory, the test names won't need to be updated to reflect that.
By adhering to this structure, our test suite will effectively take form of a living documentation. For example, this is how the test suite is organized in CliWrap (the underscores are replaced with spaces by xUnit):
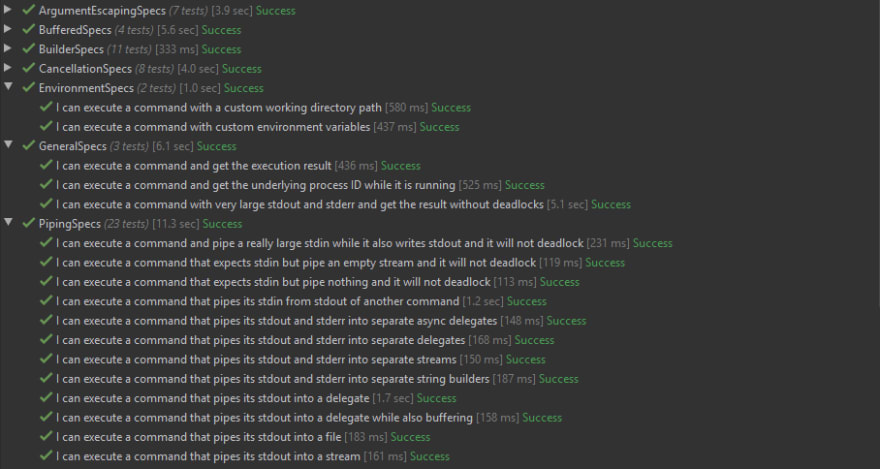
As long as a piece of software does something at least remotely useful, it will always have functional requirements. Those can be either formal (specification documents, user stories, etc.) or informal (verbally agreed upon, assumed, JIRA tickets, written on toilet paper, etc.)
Turning informal specifications into functional tests can often be difficult because it requires us to take a step away from code and challenge ourselves to think from a user's perspective. What helps me with my open source projects is that I start by creating a readme file where I list a bunch of relevant usage examples, and then encode those into tests.
To summarize, we can conclude that it's best to partition tests based on threads of behavior, rather than the code's internal structure.
If we combine all these ideas, we get a mental framework that provides us with a clear goal for writing tests and a good sense of organization, while not relying on any assumptions. We can use it to establish a test suite for our project that focuses on value, and then scale it according to priorities and limitations relevant to the current context.
Functional testing for web services (via ASP.NET Core)
There might still be some confusion as to what constitutes functional testing or how exactly it's supposed to look especially if you've never done it before, so it makes sense to show a simple but complete example. For this, we will turn the solar calculator from earlier into a web service and cover it with tests according to the rules we've outlined in the previous part of the article. This app will be based on ASP.NET Core, which is a web framework I'm most familiar with, but the same idea should also equally apply to any other platform.
Our web service is going to expose endpoints to calculate sunrise and sunset times based on the user's IP or provided location. To make things a bit more interesting, we'll also add a Redis caching layer to store previous calculations for faster responses.
The tests will work by launching the app in a simulated environment where it can receive HTTP requests, handle routing, perform validation, and exhibit almost identical behavior to an app running in production. At the same time, we will also use Docker to make sure our tests rely on the same infrastructural dependencies as the real app does.
Let us first go over the implementation of the web app to understand what we're dealing with. Note, some parts in the code snippets below are omitted for brevity, but you can also check out the full project on GitHub.
First off, we will need a way to get the user's location by IP, which is done by the LocationProvider class we've seen in earlier examples. It works simply by wrapping an external GeoIP lookup service called IP-API:
public class LocationProvider
{
private readonly HttpClient _httpClient;
public LocationProvider(HttpClient httpClient) =>
_httpClient = httpClient;
public async Task<Location> GetLocationAsync(IPAddress ip)
{
// If IP is local, just don't pass anything (useful when running on localhost)
var ipFormatted = !ip.IsLocal() ? ip.MapToIPv4().ToString() : "";
var json = await _httpClient.GetJsonAsync($"http://ip-api.com/json/{ipFormatted}");
var latitude = json.GetProperty("lat").GetDouble();
var longitude = json.GetProperty("lon").GetDouble();
return new Location
{
Latitude = latitude,
Longitude = longitude
};
}
}
In order to turn location into solar times, we're going to rely on the sunrise/sunset algorithm published by US Naval Observatory. The algorithm itself is too long to include here, but the rest of the implementation for SolarCalculator is as follows:
public class SolarCalculator
{
private readonly LocationProvider _locationProvider;
public SolarCalculator(LocationProvider locationProvider) =>
_locationProvider = locationProvider;
private static TimeSpan CalculateSolarTimeOffset(Location location, DateTimeOffset instant,
double zenith, bool isSunrise)
{
/* ... */
// Algorithm omitted for brevity
/* ... */
}
public async Task<SolarTimes> GetSolarTimesAsync(Location location, DateTimeOffset date)
{
/* ... */
}
public async Task<SolarTimes> GetSolarTimesAsync(IPAddress ip, DateTimeOffset date)
{
var location = await _locationProvider.GetLocationAsync(ip);
var sunriseOffset = CalculateSolarTimeOffset(location, date, 90.83, true);
var sunsetOffset = CalculateSolarTimeOffset(location, date, 90.83, false);
var sunrise = date.ResetTimeOfDay().Add(sunriseOffset);
var sunset = date.ResetTimeOfDay().Add(sunsetOffset);
return new SolarTimes
{
Sunrise = sunrise,
Sunset = sunset
};
}
}
Since it's an MVC web app, we will also have a controller that provides endpoints to expose the app's functionality:
[ApiController]
[Route("solartimes")]
public class SolarTimeController : ControllerBase
{
private readonly SolarCalculator _solarCalculator;
private readonly CachingLayer _cachingLayer;
public SolarTimeController(SolarCalculator solarCalculator, CachingLayer cachingLayer)
{
_solarCalculator = solarCalculator;
_cachingLayer = cachingLayer;
}
[HttpGet("by_ip")]
public async Task<IActionResult> GetByIp(DateTimeOffset? date)
{
var ip = HttpContext.Connection.RemoteIpAddress;
var cacheKey = $"{ip},{date}";
var cachedSolarTimes = await _cachingLayer.TryGetAsync<SolarTimes>(cacheKey);
if (cachedSolarTimes != null)
return Ok(cachedSolarTimes);
var solarTimes = await _solarCalculator.GetSolarTimesAsync(ip, date ?? DateTimeOffset.Now);
await _cachingLayer.SetAsync(cacheKey, solarTimes);
return Ok(solarTimes);
}
[HttpGet("by_location")]
public async Task<IActionResult> GetByLocation(double lat, double lon, DateTimeOffset? date)
{
/* ... */
}
}
As seen above, the /solartimes/by_ip endpoint mostly just delegates execution to SolarCalculator, but also has very simple caching logic to avoid redundant requests to 3rd party services. The caching is done by the CachingLayer class which encapsulates a Redis client used to store and retrieve JSON content:
public class CachingLayer
{
private readonly IConnectionMultiplexer _redis;
public CachingLayer(IConnectionMultiplexer connectionMultiplexer) =>
_redis = connectionMultiplexer;
public async Task<T> TryGetAsync<T>(string key) where T : class
{
var result = await _redis.GetDatabase().StringGetAsync(key);
if (result.HasValue)
return JsonSerializer.Deserialize<T>(result.ToString());
return null;
}
public async Task SetAsync<T>(string key, T obj) where T : class =>
await _redis.GetDatabase().StringSetAsync(key, JsonSerializer.Serialize(obj));
}
Finally, all of the above parts are wired together in the Startup class by configuring request pipeline and registering required services:
public class Startup
{
private readonly IConfiguration _configuration;
public Startup(IConfiguration configuration) =>
_configuration = configuration;
private string GetRedisConnectionString() =>
_configuration.GetConnectionString("Redis");
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc(o => o.EnableEndpointRouting = false);
services.AddSingleton<IConnectionMultiplexer>(
ConnectionMultiplexer.Connect(GetRedisConnectionString()));
services.AddSingleton<CachingLayer>();
services.AddHttpClient<LocationProvider>();
services.AddTransient<SolarCalculator>();
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
app.UseDeveloperExceptionPage();
app.UseMvcWithDefaultRoute();
}
}
Note that we didn't have our classes implement any autotelic interfaces because we're not planning to use mocks. It may happen that we will need to substitute one of the services in tests but it's not yet clear now, so we avoid unnecessary work (and design damage) until we're sure we need it.
Although it's a rather simple project, this app already incorporates a decent amount of infrastructural complexity by relying on a 3rd party web service (GeoIP provider) as well as a persistence layer (Redis). This is a rather common setup which a lot of real-life projects can relate to.
With a classical approach focused on unit testing, we would find ourselves targeting the service layer and possibly the controller layer of our app, writing isolated tests that ensure that every branch of code executes correctly. Doing that would be useful to an extent but could never give us confidence that the actual endpoints, with all of the middleware and peripheral components, work as intended.
Instead, we will write tests that target the endpoints directly. To do that, we will need to create a separate testing project and add a few infrastructural components that will support our tests. One of them is FakeApp which is going to be used to encapsulate a virtual instance of our app:
public class FakeApp : IDisposable
{
private readonly WebApplicationFactory<Startup> _appFactory;
public HttpClient Client { get; }
public FakeApp()
{
_appFactory = new WebApplicationFactory<Startup>();
Client = _appFactory.CreateClient();
}
public void Dispose()
{
Client.Dispose();
_appFactory.Dispose();
}
}
The majority of the work here is already done by WebApplicationFactory, which is a utility provided by the framework that allows us to bootstrap the app in-memory for testing purposes. It also provides us with API to override configuration, service registrations, and the request pipeline if needed.
We can use an instance of this object in tests to run the app, send requests with the provided HttpClient, and then check that the response matches our expectations. This instance can be either shared among multiple tests or instead created separately for each one.
Since we also rely on Redis, we want to have a way to spin up a fresh server to be used by our app. There are many ways to do it, but for a simple example I decided to use xUnit's fixture API for this purpose:
public class RedisFixture : IAsyncLifetime
{
private string _containerId;
public async Task InitializeAsync()
{
// Simplified, but ideally should bind to a random port
var result = await Cli.Wrap("docker")
.WithArguments("run -d -p 6379:6379 redis")
.ExecuteBufferedAsync();
_containerId = result.StandardOutput.Trim();
}
public async Task ResetAsync() =>
await Cli.Wrap("docker")
.WithArguments($"exec {_containerId} redis-cli FLUSHALL")
.ExecuteAsync();
public async Task DisposeAsync() =>
await Cli.Wrap("docker")
.WithArguments($"container kill {_containerId}")
.ExecuteAsync();
}
The above code works by implementing the IAsyncLifetime interface that lets us define methods which are going to be executed before and after the tests run. We are using these methods to start a Redis container in Docker and then kill it once the testing has finished.
Besides that, the RedisFixture class also exposes ResetAsync method which can be used to execute the FLUSHALL command to delete all keys from the database. We will be calling this method to reset Redis to a clean slate before each test. As an alternative, we could also just restart the container instead, which takes a bit longer but is probably more reliable.
Now that the infrastructure is set up, we can move on to writing our first test:
public class SolarTimeSpecs : IClassFixture<RedisFixture>, IAsyncLifetime
{
private readonly RedisFixture _redisFixture;
public SolarTimeSpecs(RedisFixture redisFixture)
{
_redisFixture = redisFixture;
}
// Reset Redis before each test
public async Task InitializeAsync() => await _redisFixture.ResetAsync();
[Fact]
public async Task User_can_get_solar_times_for_their_location_by_ip()
{
// Arrange
using var app = new FakeApp();
// Act
var response = await app.Client.GetStringAsync("/solartimes/by_ip");
var solarTimes = JsonSerializer.Deserialize<SolarTimes>(response);
// Assert
solarTimes.Sunset.Should().BeWithin(TimeSpan.FromDays(1)).After(solarTimes.Sunrise);
solarTimes.Sunrise.Should().BeCloseTo(DateTimeOffset.Now, TimeSpan.FromDays(1));
solarTimes.Sunset.Should().BeCloseTo(DateTimeOffset.Now, TimeSpan.FromDays(1));
}
}
As you can see, the setup is really simple. All we need to do is create an instance of FakeApp and use the provided HttpClient to send requests to one of the endpoints, just like you would if it was a real web app.
This specific test works by querying the /solartimes/by_ip route, which determines user's sunrise and sunset times for the current date based on their IP. Since we're relying on an actual GeoIP provider and don't know what the result is going to be, we're performing property-based assertions to ensure that the solar times are valid.
Although those assertions will be able to catch a multitude of potential bugs, it doesn't give us full confidence that the result is fully correct. There are a couple of different ways we can improve on this, however.
An obvious option would be to replace the real GeoIP provider with a fake instance that will always return the same location, allowing us to hard-code the expected solar times. The downside of doing that is that we will be effectively reducing the integration scope, which means we won't be able to verify that our app talks to the 3rd party service correctly.
As an alternative approach, we can instead substitute the IP address that the test server receives from the client. This way we can make the test more strict, while maintaining the same integration scope.
To accomplish this, we will need to create a startup filter that lets us inject a custom IP address into request context using middleware:
public class FakeIpStartupFilter : IStartupFilter
{
public IPAddress Ip { get; set; } = IPAddress.Parse("::1");
public Action<IApplicationBuilder> Configure(Action<IApplicationBuilder> nextFilter)
{
return app =>
{
app.Use(async (ctx, next) =>
{
ctx.Connection.RemoteIpAddress = Ip;
await next();
});
nextFilter(app);
};
}
}
We can then wire it into FakeApp by registering it as a service:
public class FakeApp : IDisposable
{
private readonly WebApplicationFactory<Startup> _appFactory;
private readonly FakeIpStartupFilter _fakeIpStartupFilter = new FakeIpStartupFilter();
public HttpClient Client { get; }
public IPAddress ClientIp
{
get => _fakeIpStartupFilter.Ip;
set => _fakeIpStartupFilter.Ip = value;
}
public FakeApp()
{
_appFactory = new WebApplicationFactory<Startup>().WithWebHostBuilder(o =>
{
o.ConfigureServices(s =>
{
s.AddSingleton<IStartupFilter>(_fakeIpStartupFilter);
});
});
Client = _appFactory.CreateClient();
}
/* ... */
}
Now we can update the test to rely on concrete data:
[Fact]
public async Task User_can_get_solar_times_for_their_location_by_ip()
{
// Arrange
using var app = new FakeApp
{
ClientIp = IPAddress.Parse("20.112.101.1")
};
var date = new DateTimeOffset(2020, 07, 03, 0, 0, 0, TimeSpan.FromHours(-5));
var expectedSunrise = new DateTimeOffset(2020, 07, 03, 05, 20, 37, TimeSpan.FromHours(-5));
var expectedSunset = new DateTimeOffset(2020, 07, 03, 20, 28, 54, TimeSpan.FromHours(-5));
// Act
var query = new QueryBuilder
{
{"date", date.ToString("O", CultureInfo.InvariantCulture)}
};
var response = await app.Client.GetStringAsync($"/solartimes/by_ip{query}");
var solarTimes = JsonSerializer.Deserialize<SolarTimes>(response);
// Assert
solarTimes.Sunrise.Should().BeCloseTo(expectedSunrise, TimeSpan.FromSeconds(1));
solarTimes.Sunset.Should().BeCloseTo(expectedSunset, TimeSpan.FromSeconds(1));
}
Some developers might still feel uneasy about relying on a real 3rd party web service in tests, because it may lead to non-deterministic results. Conversely, one can argue that we do actually want our tests to incorporate that dependency, because we want to be aware if it breaks or changes in unexpected ways, as it can lead to bugs in our own software.
Of course, using real dependencies is not always possible, for example if the service has usage quotas, costs money, or is simply slow or unreliable. In such cases we would want to replace it with a fake (preferably not mocked) implementation to be used in tests instead. This, however, is not one of those cases.
Similarly to how we did with the first one, we can also write a test that covers the second endpoint. This one is simpler because all input parameters are passed directly as part of URL query:
[Fact]
public async Task User_can_get_solar_times_for_a_specific_location_and_date()
{
// Arrange
using var app = new FakeApp();
var date = new DateTimeOffset(2020, 07, 03, 0, 0, 0, TimeSpan.FromHours(+3));
var expectedSunrise = new DateTimeOffset(2020, 07, 03, 04, 52, 23, TimeSpan.FromHours(+3));
var expectedSunset = new DateTimeOffset(2020, 07, 03, 21, 11, 45, TimeSpan.FromHours(+3));
// Act
var query = new QueryBuilder
{
{"lat", "50.45"},
{"lon", "30.52"},
{"date", date.ToString("O", CultureInfo.InvariantCulture)}
};
var response = await app.Client.GetStringAsync($"/solartimes/by_location{query}");
var solarTimes = JsonSerializer.Deserialize<SolarTimes>(response);
// Assert
solarTimes.Sunrise.Should().BeCloseTo(expectedSunrise, TimeSpan.FromSeconds(1));
solarTimes.Sunset.Should().BeCloseTo(expectedSunset, TimeSpan.FromSeconds(1));
}
We can keep adding tests like this one to ensure that the app supports all possible locations, dates, and handles potential edge cases such as the midnight sun phenomenon. However, you may not want to re-test the entire pipeline each time but focus just on the business logic that calculates the solar times.
Doing that would imply that we need to isolate SolarCalculator from LocationProvider somehow and that in turn implies mocking which we want to avoid. Fortunately, there is a more clever way to achieve that.
We can alter the implementation of SolarCalculator by separating the pure and impure parts of the code away from each other:
public class SolarCalculator
{
private static TimeSpan CalculateSolarTimeOffset(Location location, DateTimeOffset instant,
double zenith, bool isSunrise)
{
/* ... */
}
public SolarTimes GetSolarTimes(Location location, DateTimeOffset date)
{
var sunriseOffset = CalculateSolarTimeOffset(location, date, 90.83, true);
var sunsetOffset = CalculateSolarTimeOffset(location, date, 90.83, false);
var sunrise = date.ResetTimeOfDay().Add(sunriseOffset);
var sunset = date.ResetTimeOfDay().Add(sunsetOffset);
return new SolarTimes
{
Sunrise = sunrise,
Sunset = sunset
};
}
}
What changed is now, instead of relying on LocationProvider to provide it, the GetSolarTimes method takes location as an explicit parameter. Doing that means that we also no longer require dependency inversion, as there are no dependencies to invert.
To wire everything back together, all we need to do is update the controller:
[ApiController]
[Route("solartimes")]
public class SolarTimeController : ControllerBase
{
private readonly SolarCalculator _solarCalculator;
private readonly LocationProvider _locationProvider;
private readonly CachingLayer _cachingLayer;
public SolarTimeController(
SolarCalculator solarCalculator,
LocationProvider locationProvider,
CachingLayer cachingLayer)
{
_solarCalculator = solarCalculator;
_locationProvider = locationProvider;
_cachingLayer = cachingLayer;
}
[HttpGet("by_ip")]
public async Task<IActionResult> GetByIp(DateTimeOffset? date)
{
var ip = HttpContext.Connection.RemoteIpAddress;
var cacheKey = ip.ToString();
var cachedSolarTimes = await _cachingLayer.TryGetAsync<SolarTimes>(cacheKey);
if (cachedSolarTimes != null)
return Ok(cachedSolarTimes);
// Composition instead of dependency injection
var location = await _locationProvider.GetLocationAsync(ip);
var solarTimes = _solarCalculator.GetSolarTimes(location, date ?? DateTimeOffset.Now);
await _cachingLayer.SetAsync(cacheKey, solarTimes);
return Ok(solarTimes);
}
/* ... */
}
Since our existing tests are not aware of implementation details, this simple refactoring didn't break them in any way (which would not be the case with unit tests). With that done, we can write some additional light-weight tests to cover the business logic more extensively, while still not mocking anything:
[Fact]
public void User_can_get_solar_times_for_New_York_in_November()
{
// Arrange
var location = new Location
{
Latitude = 40.71,
Longitude = -74.00
};
var date = new DateTimeOffset(2019, 11, 04, 00, 00, 00, TimeSpan.FromHours(-5));
var expectedSunrise = new DateTimeOffset(2019, 11, 04, 06, 29, 34, TimeSpan.FromHours(-5));
var expectedSunset = new DateTimeOffset(2019, 11, 04, 16, 49, 04, TimeSpan.FromHours(-5));
// Act
var solarTimes = new SolarCalculator().GetSolarTimes(location, date);
// Assert
solarTimes.Sunrise.Should().BeCloseTo(expectedSunrise, TimeSpan.FromSeconds(1));
solarTimes.Sunset.Should().BeCloseTo(expectedSunset, TimeSpan.FromSeconds(1));
}
[Fact]
public void User_can_get_solar_times_for_Tromso_in_January()
{
// Arrange
var location = new Location
{
Latitude = 69.65,
Longitude = 18.96
};
var date = new DateTimeOffset(2020, 01, 03, 00, 00, 00, TimeSpan.FromHours(+1));
var expectedSunrise = new DateTimeOffset(2020, 01, 03, 11, 48, 31, TimeSpan.FromHours(+1));
var expectedSunset = new DateTimeOffset(2020, 01, 03, 11, 48, 45, TimeSpan.FromHours(+1));
// Act
var solarTimes = new SolarCalculator().GetSolarTimes(location, date);
// Assert
solarTimes.Sunrise.Should().BeCloseTo(expectedSunrise, TimeSpan.FromSeconds(1));
solarTimes.Sunset.Should().BeCloseTo(expectedSunset, TimeSpan.FromSeconds(1));
}
Although these tests no longer exercise the full integration scope, they are still driven by functional requirements of the app. Because we already have another high-level test that covers the entire endpoint, we can keep these ones more narrow without sacrificing overall confidence. This trade-off makes sense if we're trying to improve execution speed, but I would recommend to stick to high-level tests as much as possible, at least until it becomes a problem.
Finally, we may also want to do something to ensure that our Redis caching layer works correctly as well. Even though we're using it in our tests, it never actually returns a cached response because the database gets reset between tests.
The problem with testing things like caching is that they can't be defined by functional requirements. A user, with no awareness of the app's internal affairs, has no way of knowing whether the responses are returned from cache or not.
However, if our goal is only to test the integration between the app and Redis, we don't need to write implementation-aware tests and can do something like this instead:
[Fact]
public async Task User_can_get_solar_times_for_their_location_by_ip_multiple_times()
{
// Arrange
using var app = new FakeApp();
// Act
var collectedSolarTimes = new List<SolarTimes>();
for (var i = 0; i < 3; i++)
{
var response = await app.Client.GetStringAsync("/solartimes/by_ip");
var solarTimes = JsonSerializer.Deserialize<SolarTimes>(response);
collectedSolarTimes.Add(solarTimes);
}
// Assert
collectedSolarTimes.Select(t => t.Sunrise).Distinct().Should().ContainSingle();
collectedSolarTimes.Select(t => t.Sunset).Distinct().Should().ContainSingle();
}
The test will query the same endpoint multiple times and assert that the result always remains the same. This is enough to ensure that the responses are cached properly and then returned in the same way as normal responses.
At the end of the day we have a simple test suite that looks like this:

Note that the duration of the tests is pretty good, with the fastest integration test completing at 55ms and the slowest being under a second (due to suffering from cold start). Considering that these tests involve the entire lifecycle, include all dependencies and infrastructure, while relying on a grand total of zero mocks, I would say that this is more than acceptable.
If you want to tinker with the example project yourself, you can find it on GitHub.
Drawbacks and considerations
Unfortunately, there is no silver bullet and the approaches described in this article also suffer from some potential drawbacks. In the interest of fairness, it makes sense to mention them as well.
One of the biggest challenges I've found when doing high-level functional testing is figuring out a good balance between usefulness and usability. Compared to approaches that focus specifically on unit testing, it does take more effort to ensure that such tests are sufficiently deterministic, don't take too long, can run independently of each other, and are generally usable during development.
The wide scope of tests also implies the need for a deeper understanding of the project's dependencies and technologies it relies upon. It's important to know how they're used, whether they can be easily containerized, which options are available and what are the trade-offs.
In the context of integration testing, the "testability" aspect is not defined by how well the code can be isolated, but instead by how well the actual infrastructure accommodates and facilitates testing. This puts a certain prerequisite on the responsible person and the team in general in terms of technical expertise.
It may also take some time to set up and configure the testing environment, as it includes creating fixtures, wiring fake implementations, adding custom initialization and cleanup behavior, and so on. All these things need to be maintained as the project scales and becomes more complicated.
Writing functional tests in itself involves a bit more planning as well, because it's no longer just about covering every method of every class, but rather about outlining software requirements and turning them into code. Understanding what those requirements are and which of them are functional can also be tricky sometimes, as it requires an ability to think from a user's perspective.
Another common concern is that high-level tests often suffer from a lack of locality. If a test fails, either due to unmet expectations or because of an unhandled exception, it's usually unclear what exactly caused the error.
Although there are ways to mitigate this issue, ultimately it's always going to be a trade-off: isolated tests are better at indicating the cause of an error, while integrated tests are better at highlighting the impact. Both are equally useful, so it comes down to what you consider to be more important.
At the end of the day, I still think functional testing is worth it even despite these shortcomings, as I find that it leads to a better developer experience overall. It's been a while since I've done classic unit testing and I'm not looking forward to starting again.
Summary
Unit testing is a popular approach for testing software, but mostly for the wrong reasons. It's often touted as an effective way for developers to test their code while also enforcing best design practices, however many find it encumbering and superficial.
It's important to understand that development testing does not equate to unit testing. The primary goal is not to write tests which are as isolated as possible, but rather to gain confidence that the code works according to its functional requirements. And there are better ways to achieve that.
Writing high-level tests that are driven by user behavior will provide you with much higher return on investment in the long run, and it isn't as hard as it seems. Find an approach that makes the most sense for your project and stick to it.
Here are the main takeaways:
- Think critically and challenge best practices
- Don't rely on the the test pyramid
- Separate tests by functionality, rather than by classes, modules, or scope
- Aim for the highest level of integration while maintaining reasonable speed and cost
- Avoid sacrificing software design for testability
- Consider mocking only as a last resort
There are also other great articles about alternative testing approaches in modern software development. These are the ones I've personally found really interesting:
- Write tests. Not too many. Mostly integration (Kent C. Dodds)
- Mocking is a Code Smell (Eric Elliott)
- Test-induced design damage (David Heinemeier Hansson)
- Slow database test fallacy (David Heinemeier Hansson)
- Fallacy of Unit Testing (Aaron W. Hsu)
- The No. 1 unit testing best practice: Stop doing it (Vitaliy Pisarev)
- Testing of Microservices at Spotify (André Schaffer)
Follow me on Twitter to get notified when I post a new article ✨





Top comments (32)
Just a few points
Thanks for the comment.
That's correct. It's related however because mocks are too often necessary to achieve isolation required for proper unit testing. Unfortunately it's not always possible to flatten the hierarchy or use pure-impure segregation principles to avoid it.
I personally don't agree with this, especially that you should "always depend on an abstraction instead of an implementation". If your use case doesn't envision polymorphism and your abstraction is there "just in case", you've essentially wasted effort. There's nothing wrong with coupling if that's intentional, not all coupling should be avoided just because you can. In fact, most of your interfaces are still coupled to implementations in ways you may not realize until you try to introduce a second implementation.
If the goal of unit test is to aid in design then I would argue the name is misleading and rightfully gets people confused. I personally don't believe it helps with design, but if it helps you then by all means. However, if your goal is to ensure that your software works, then maybe you want to re-evaluate your approaches. From a high-level perspective, if your software works correctly according to the functional requirements, there might be a million bugs in your code that ultimately don't matter because they never surface in any way that would impact user experience. Instead, by not relying on internal specifics, you get the freedom to change and refactor your code however you want, as long as it doesn't invalidate the top-level public contract.
What do you mean by low level bugs? Again, I would argue that if the bug never surfaces to the top level, it was never a bug to begin with.
To add to the thread here - I think I'm somewhere between the two of you.
Yes, SOLID is a good principle to follow, but only developers working alone in their bedroom can stick to it rigidly. There are times when the business needs outweigh the beauty of code.
On the point of interfaces... if I'm sharing some class with another project to interact with, yes, an interface is what gets shared. If I'm only using that class internally, and there's only 1 example of it's behaviour, then an interface is (to me) a waste of time (YAGNI).
Over time, as the project evolves, if I need something similar but not quite the same... asking the IDE to create an interface is a single key combination. Refactoring away from the concrete implementation to reference the interface instead is another, key combination. (That is to say, it's not difficult to add an interface if you need one later).
On the point of unit tests - there's a reason that they're at the bottom of the pyramid - if the foundations of the pyramid are incomplete, you risk the peak toppling over! The art there, is in figuring out what's appropriate test coverage at each level of the pyramid, and how you measure that.
In our corporate case, submitting for a peer review with no unit tests means that you have more work to do. Equally, submitting something that has 100% unit test coverage means you have some things to delete (nothing is more beautiful than deleting things!). The same point works for integration tests.
Our definitions:
Maybe it was simply a bug in some edge case that you didn't consider, and it exposes some sensitive information to an attacker? While it doesn't crash your application directly, it's definitely something that needs fixing... and since it's in an edge case that wasn't considered before, you wouldn't have seen it until a user found it.
Just out of curiosity:
How do you both trust and verify?
But if you considered it when writing a unit test, couldn't you consider it when writing a high-level test? Or conversely, if you didn't consider it when writing high-level test, you could very well also not consider it when writing unit tests.
I saw your location & presumed you'd be familiar with the concept (a friend of mine moved from Kyiv to UK, it was him that I first heard the saying from). :)
In our case, at the unit test level, we simply trust that 3rd party dependencies function as their authors intend. There is a small review process that we go through before deciding to include a 3rd party dependency. Basically - if Apache Commons, go ahead, if it's some obscure Docker image on Docker Hub (non-certified) and only 4 other people have downloaded it... err... let's not touch that until it's more popular.
Then, at the integration test level (still in development), tests can be written to use the transport mechanism, or the file system etc (verifying that, for example, Commons IO or Gson dependencies actually do what we expect).
Later still, QA have tests (automated) that will inspect the model being transmitted across the "wire" etc - and they will flag up if we're exposing internal identifiers etc that another service (or the general public) don't explicitly need (all specified as part of the service design).
Exactly.
I think my take there, is that it depends where you will fix the bug (with the benefit of hindsight), as to where you should be testing for it. If the bug is a simple "change this unit of code to fix it" then a unit test should be catching it (and this is one of the few use cases where TDD makes sense to me - I know the bug is in this code, so I'll write a test for it first, make the build fail, and then fix it).
However, if the bug is more subtle, and means that two (or more) units are working in unison to produce the problem further up (eg, A and B must be true, and both are in different units of code), then I'd write an integration test, and probably fix the issue(s) in the discrete unit(s). Then spend some time worrying about side effects & how we can potentially mitigate them.
My point being, unit tests are a necessary evil... but so are integration tests, QA tests (including manual testing) and in the majority of our cases, UAT too!
I agree that some companies/books/public speakers overly promote unit tests, but we certainly shouldn't be ignoring them entirely.
Makes sense, thanks.
I was actually familiar with the concept but was curious what exactly you meant by it ;)
I'd say your design process is just completely different than mine. When you are designing a class, you don't care about the implementation that you are communicating with. You don't create an interface because you want to introduce polymorphism, you create the interface because all you care about is "what" needs to happen, not "how" it needs to happen. Splitting what from how is absolutely essential when you want to create SOLID software. When you have proper separation of concerns, and your classes are single responsibility all you should care about is this interface, and thus, at that point in time, all you are writing is an interface.
What you propose is backwards you already have an implementation and then create an interface to start mocking. Honestly, it's not surprising why you dislike these tools for software design when you are following this path.
High level tests do not test low level intricacies of a class. It can be something as simple as multiple enumerations because you forgot to do a .ToList() (or whatever) on a database query, causing you to perform the same query over and over again. Good luck finding that out on a high level integration test. You need to ensure in your design that what you have designed is actually doing what you expect it to do.
While you are writing this high level tests and you do want to go over all these low level intricacies you are holding a model of many classes (units) in your head. We write small units because complexity increases when the unit size increases. As such, the complexity of a test increases when you are increasing the scope of the test. So you are either
Or you just write your unit test while you are designing your software.
This is already an advantage of following SOLID standards, writing small units with a single purpose, that is easily exchangeable and reusable. Also, since you were programming against an interface to start with, the implementations don't matter.
Can I also mention that a million bugs in your software that "supposedly" don't surface because your integrations tests don't cover it can cost your organization a serious amount of money. I've been working in banking and offshore before my current job, downtime of half a day can easily cost you 100k, just because a developer didn't want to design the software properly.
In a perfect world, you're right. My employer certainly doesn't exist in a perfect world though.
I presume you're a TDD advocate. I mostly write the implementation first then test it, but I wouldn't be creating an interface just to add mocks in tests. I also wouldn't be creating an interface if I only have one concrete implementation - since that implementation effectively works as the interface, until I need to abstract it in some way.
This is a rather large overstatement. Don't they? Why not? Is it impossible to write a high level test that invokes the low level intricacies? Do all of those low level intricacies need to be tested? I'm currently conducting interviews, and rejected one candidate in part because they were writing tests for getters/setters.
That's pretty cheap based on the industries I've worked in. In some regulated markets, the fine issued by the government authority for simply having to failover to the DR datacentre exceeds 100k, let alone other ancillary costs like loss of income.
End of the day, there has to be a balance. I personally think the title of this article was a little click-biased, and the author was trying to simulate a discussion by portraying a pretty biased argument. Nothing wrong with that, but the way I read it, the author doesn't entirely believe everything that they've written (as evidenced by my comment discussion with them).
I'm not sure how this is relevant? We are just discussing how we are creating software. It's not as if it takes longer to create/maintain.
I'm just wondering how the design process works. When you are writing class A and B, and A relies on B, but B is not yet written and you start with writing A, surely you'll program against the interface of B instead of its actual implementation? Anyway, that's how I do it. I will have an interface before an implementation 99.9999% of the time. I do not feel like a well defined interface is clogging up the code, for everyone that's not interested in the implementation it is an easy overview of the API.
And... even though I'd say it is irrelevant I'm neither an opponent nor advocate of TDD. In what order you write your tests or classes is for me an implementation detail. The interface here, however, is that your tests have a purpose in the design and maintenance of your code and that part is important.
I do believe I gave some options in my post, and why you shouldn't be testing logic of low level classes on a high level (something with complexity)
Your tests should be SOLID just like your code base. As soon as you need to go over multiple aspects you are increasing the complexity of your code (test) and with that the readability. Just keep it simple is all that I'm advocating here.
You write tests for logic, if your getters and setters have logic... for whatever reason, I would surely want to test my logic while designing my class. If you are testing the framework of getters and setters I agree with you, but that honestly has nothing to do with with the intricacies (=logic) of the class that I am referring to.
We're deliberately staying away from languages, and maybe it's just my approach, but rigidly sticking to SOLID principles (or any principles for that matter) certainly does take longer than me writing code and then tidying it up to obey principles whenever that's needed.
Don't get me wrong, I follow SOLID closely, right out of the gate, but just not strictly.
That approach is counter-intuitive, at least to me. If A depends on B, but B is not written yet... I'd be starting with writing B. Only in the case that B is being written by someone else on the team would we agree an interface up front so both can work independently.
I'm much the same, hence why I originally posted here that I think I'm somewhere between you & the original author.
In that case, I'd submit that they aren't getters and setters, and have side-effects that violate SOLID principles.
Hence my ".... for whatever reason", there's more to logic than side effects. For example, a myriad of if statements or whatever. All things that don't belong in a getter or setter, but if you insist that it should be in the getter or setter, at least write a contract (=test) on how you intend the getter or setter should behave.
And that's the core of this whole discussion right? Is it necessary to test logic that isn't directly visible to the outside world?
You could say, if it isn't directly visible then it doesn't need to be tested. I'd say if the code is there, it is there for a reason, if it there for a reason it should be tested. If the code is not there for a reason, get rid of it. And all these questions would've been circumvented if your tests were written during the design of a class.
You can potentially test this in a big integration test, but, why would you? I'd say that's a violation of KISS principles because the coupling between a class and its contract is lost and I, as a developer working on your code need to jump through hoops just to find out how you intended your piece of software to work.
Sure, perhaps, I don't think I'm necessarily faster than a two-step approach. And everything perfect in one go is utopic, sometimes it takes refactoring to get things right.
I do feel like it is our responsibility as software engineers to either convince our employer that a standardized approach is beneficial, and also that as an expert in the field, it is good to say no. I hope that writing standardized software doesn't only occur in a perfect world.
On this, we both agree. I also know that I've been in situations in the past where arguing for standardisation has fallen on deaf ears.
There's a multitude of reasons why others in the business will try to get us to cut corners, to deliver slightly faster etc. Sometimes we can say no, sometimes we're overruled.
Hence my belief that 100% standardised code, does indeed only exist in a perfect world. Maybe 80% or so is a more realistic aim.
An interesting article, you clearly know the topic of testing very well, more so than the great majority of developers.
I wouldn't be so sure though the principles of unit testing are well understood in our industry. In my experience most organisations have a very haphazard approach to testing, and this makes testing more difficult than it should be and seemingly of less value.
I think the main point is producing well designed code and proving it works is hard, and requires a lot of work. This is regardless of your testing strategy, which in my opinion needs to contain a good mix of low level and high level tests.
Great post! The most of what you have said sounds reasonable but I would say that business logic still benefits from unit test and should be 100% unit test covered
I agree to an extent ... and as always, "it depends".
If your system/app is heavy on business logic, then unit tests (where you test pure functions, no side effects) may be useful.
It may then also pay off to rigorously separate the business logic ("pure functions") from the code that's exerting side effects, for instance using a 'functional core, imperative shell' architecture - unit tests then become easy to implement, without mocking and whatever (especially if you favor a more FP heavy style for that part).
However, in many apps/systems the business logic is pretty trivial, and the side effects are where it's at - in that case I think you should go for integration tests.
My experience with the "highest level" (e2e) tests is that they're often slow and brittle, repetitive, and tend to be not very precise and specific about WHICH piece of functionality they're testing. Could be me but I've had a lot of frustration with e2e tests.
So I'm not a huge fan of e2e, but I am of integration tests. Bottom line (for me at least): I think that in MANY cases integration tests are the sweet spot.
I think we're more in agreement than it seems actually.
I definitely agree with testing business logic directly and you can mix those tests in with the rest of your functional suite. In the example (2nd last part of the article) I actually show what you described, i.e. flattening the hierarchy by separating pure from impure concerns and avoiding mocks. Unfortunately, that's also not always possible, but that's another story.
I'm also not advocating to "always write e2e tests" (the article highlights this) but instead aim as high as you can while keeping the drawbacks at an acceptable level. As you pointed out, that sweet spot can often be sometimes in the middle of the spectrum.
You are right, we agree more than we disagree :-)
Thank you for this. I recently wrote a web server in golang that handles Auth request from dovecot checkpasswd plugin. I started out writing only unit tests but I began to question myself as the complexity of tests and code grew due to unnecessary mocks and dependency injection. I ended up writing integration tests by using docker to spin up a container that contains dependencies I needed for my tests. Then automate this via bash scripts to make it runnable on most CI tools.
This paid off and the value gain was immediately obvious.
I'm normally an SRE, so I can force docker and bash to do anything. This was a big advantage for me. I suspect some Devs might have trouble navigating docker etc to create integration environment.
But yes, I 100% agree with you.
For sure, I know too many devs who avoid anything that sounds remotely devops-y because it's "not their job".
I'm like 10 days late. But uh "further perpetuated" is what you're looking for. Not "further perpetrated"
And for the fun of it and my inane pickiness
Perpetrated: carry out or commit (a harmful, illegal, or immoral action).
Perpetuated: make (something, typically an undesirable situation or an unfounded belief) continue indefinitely.
Granted the two definitely sound similar. And in hindsight IDEs are perpetrators of perpetuating bad practices.
That's my ted talk thanks for listening.
Thanks. As a non-native speaker I'm always confused between the two.
You mention in a comment that these problems are largely with mocks and that mocks are often necessary.
That's where this all falls down. Mocks are only as necessary as your application design makes them. I can't remember the last time I had to mock something in a codebase I've had reasonable influence over.
If you embrace referential transparency and push side effects to modules at the edge of your application and use interfaces to test them, you just don't need mocks. The only thing you need then is a few integration tests to ensure that the effectful code at the edges interacts with the real world correctly.
This was shown in the article. Unfortunately, separating pure from impure code will be able to get you so far and you will still have to mock quite a few things. For example, think of a case where you need to query a small portion of a very big dataset, then perform some transformation on it, then use the result to query another portion, transform that one, and finally post the resulting data to some web service. Your pure code is interleaved with impure code and your best option is to test those parts separately, but that breaks the flow in which the code is executed and you won't have confidence that you tested the pure parts exhaustively, or in the fact that the side-effects are executed correctly. This approach works out for simple transformations that follow the [data in] -> [data out] principle, but unfortunately that's not always the case.
Wow. Look, I don't doubt that this has been true for you, but you can't speak in absolutes like that and not expect opposition.
You're speaking from an experience informed by the codebases you've worked in. I assure you that there are other codebases out there for which your statements are categorically untrue.
Great post. Although I do find test-driven development helpful as a guiding technique (when it seems appropriate to use TDD -- sometimes the cost in mocking/etc is simply too much), I tend not to do it in a way that requires excessive modularity and (mentally) costly abstractions that don't provide any benefit beyond testing. I try not to introduce abstractions and configurability until there is a concrete need for them.
As an indicator of code correctness, time and experience has shown me that unit tests are not great. They tend to only prove that a certain part of the codebase behaves correctly for a very restricted set of inputs. Often, we add unit tests only after observing an error, and the new test helps us to verify the error exists and, later, that we've solved it. The payoff for adding units tests in this way is not very high, and given how long it can take to specify unit tests for complex behaviour, it's not always worth that time. The large volume of tests also increases the cost of changing things (although it's fair to argue that it helps us make those changes with more confidence that we didn't break everything).
This is why I'm very skeptical of having fixed code coverage standards within teams. I find that they're often enthusiastically championed by junior developers who overestimate their value.
At the moment, I'm more interested in two tools that don't seem to have gained very widespread traction: property-based tests, and proof systems that allow you to specify invariants that are validated for all possible inputs by the compiler, rather than informally tested for a restricted set of inputs with unit tests.
TL;DR?
There's a summary at the bottom.
At the end there's a summary
The takeaway points are good (well, except maybe for #4), and worth the read.
But I would argue that your initial thesis is largely a "straw-man" logical fallacy. You point at ways that people do unit-testing poorly (e.g. excessive mocking), and then conclude that unit-testing is "not worth it". Slavish adherence to a rule, instead of understanding what's behind the rule, will always produce crap. Doesn't mean the rule is wrong.
"Don't sacrifice design for testability"? Snort. I've been writing software since 1970, and IMHO unit-tests are the best damned thing that ever happened to design.
Very detailed and well-written article!