Originally published at my personal blog on 30/03/2020.
Hi,
Hope all are doing well, in this COVID-19 Outbreak and the lockdown, let us take a minute sometime to pray for the people who did pass away and who are under diagnosis with Corona,
So, this blog post aims to provide some technical overview of how introduction of v-frame, migration to v-frames for av-metrics and also integration of av-metrics into rav1e will help for rapid analysis. Rapid analysis like measurement of encoder’s complexity with metrics like PSNR, SSIM, A-PSNR, PSNR-HVS, MS-SSIM, CIEDE2000 etc.
These are based on IETF NETVC testing draft.
So if you are new to AV1 or rav1e or these things, In 2018, the Alliance for Open Media released its next-generation Video Codec AV1. AV1 is so far the most efficient royalty-free Video Codec Standard with respect to VP9, x264. Considering currently available AV1 Open-Source encoders libaom, SVT-AV1 and rav1e.
The Rust AV1 Encoder(rav1e) project by Mozilla, Xiph Organisation is a cleanroom AV1 Implementation having lower memory footprint making it a good starting point while others are either too slow or resource-intensive.
With the help of AreWeCompressedYet runs and analysis on personal high-performance servers and machines, the post also aims to provide some minor analysis and other insights overtime.
Some notable things from the experimentation are as follows:
-
rav1e is always having low complexity compared to SVT-AV1 and libaom since rav1e is having a lean implementation.
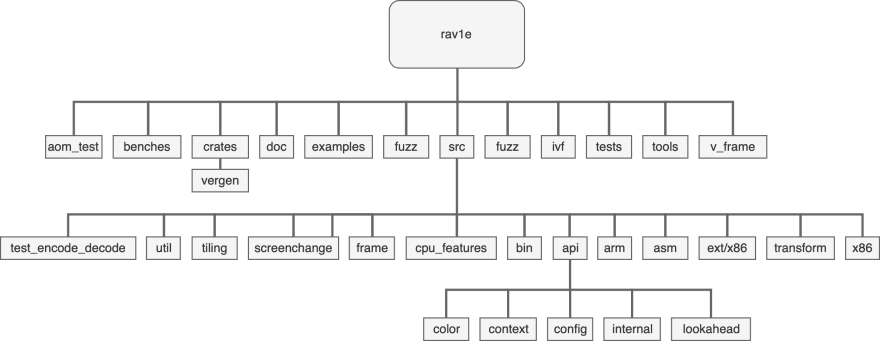
Figure 1: General overview of rav1e File-structure With the project's initial phase of support ARM(AArch64) Architecture, which made rav1e more optimised with more than 35\% Percent improved Encoding Time and in Frames Per Second(FPS), which is a great boost for having rav1e on multiple platforms, which is first time happening in AV1.
Currently, rav1e is fastest AV1 Encoder on an ARM Devices when it was tested. The test was carried on Raspberry Pi 3 B+ which houses 1.4GHz Cortex-A53 with 1GB RAM as a baseline for CPU power so when running on powerful AArch64 devices like a mobile, it gives enhanced results.
Low-latency mode makes the encoding very fast compared to normal encoding at default speed levels, where the trade-off between speed and quality is being compromised. The time between the video frame entering the encoder and the packet containing it is the latency.
-
The optimisation is an iterative process. The below diagram explains the general approach of Analysis and optimisation workflow.
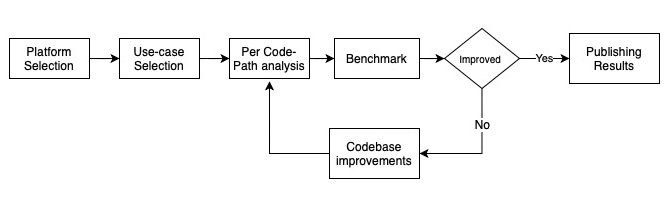
Figure 2: Overall Optimisation Process -
Usually, optimisation is done for a specific target like
- Speed, which targets Single execution time and latency.
- Memory Usage, which targets Maximum resident set and allocation count.
- Throughput, which is the number of results per unit of time and number of results per resource spend.
- Quality, which is Application and use-case dependent.
This analysis targets Speed and Memory Usage since those are the fundamental things which should make any encoder production-ready and impact will be very high.
-
There is no need to encode full videos which are having 1000 Frames to do benchmarking and per code-path analysis.
- One thing which is to be taken care is when the encoding preset is being tuned is, it should encode more than RDO Look Ahead like around 100 Frames for fair testing and good results of different types of the clip.
-
The Complexity of an encoder also depends on how large the functions and code blocks are there, see the below table for a quick comparison between rav1e and SVT-AV1.
Language files blank comment code Assembly 44 4405 3371 71208 Rust 117 4494 5455 48370 YAML 6 49 3 669 Markdown 7 157 0 376 TOML 8 37 10 232 Bourne Shell 6 38 20 151 Python 3 39 17 144 Jupyter Notebook 1 0 478 129 SUM: 192 9219 9354 121279 Table 1: Lines of Code Distrubution of rav1e Language files blank comment code Assembly 44 4419 3364 74276 C 81 2934 3180 30232 C/C++ Header 71 816 2406 3578 NAnt script 27 210 0 2506 YAML 2 46 0 486 JSON 1 0 0 427 Markdown 4 88 0 146 Python 1 12 28 35 SUM: 231 8506 8978 111686 Table 2: Lines of Code Distrubution of dav1d Language files blank comment code C 245 29282 19765 229148 C/C++ Header 289 9646 16714 64523 C++ 149 8223 11165 44228 make 25 3504 1925 7009 Markdown 20 1429 0 4438 Python 30 1396 2616 4436 Assembly 12 606 494 4291 CMake 100 579 657 3618 XML 14 0 0 1510 diff 2 4 102 1124 YAML 8 31 26 708 m4 3 52 60 393 Bourne Shell 3 35 86 382 DOS Batch 1 5 0 119 NAnt script 1 7 0 47 SUM: 902 54799 53610 365974 Table 3: Lines of Code Distrubution of SVT-AV1
One thing which is to be noted is that SVT-AV1 is having both encoder and decoder while rav1e is encoder alone if the decoder is also added to rav1e, dav1d, AV1 Decoder also, still it will be having half of SVT-AV1 and 1/3 of libaom in terms of lines of code, which makes a good starting point.
The code-coverage is another important factor, having more than 50\% code-coverage is always good to have for any software, while rav1e is having around 77\% code-coverage.
For testing based on IETF NETVC testing draft, Objective-1 Tests are being focused primarily. The Videos should be YUV 4:2:0 Y4M Uncompressed Video which does not have Audio in it for better bitrate and faster encodes.
-
For having better analysis, the encoder should have a better dynamic analysis for faster research and development, for that, the following changes are being introduced,
- Introduction of rav1e and dav1d to RTC Video Quality tool for rapid analysis between encoders.
- Introduction of new Library called v-frame for having Video configuration, definition and its missionary.
- Migration of AV-Metrics, the Library which calculates video metrics like PSNR, SSIM, A-PSNR, SSIM, CIEDE2000, PSNR-HVS etc to use v-frame as standard configuration.
- Integrate AV-Metrics to rav1e for rapid encoding analysis
The above-mentioned things will be explained in the further sections.
Into Depths of Analysis and its tools
RTC Video Quality Tool
RTC Video Quality Tool(rtc_tool) is a project started by Google which is used for quick analysis between various encoders by generating graphs based on quality metrics.
The main use-case which the tool is targetting to cover is improved rapid analysis of rav1e with other industrial encoders like VP8, VP9, libaom-av1, OpenH264 which are being used to get the clear trade-offs and hotspots between encoders.
For rapid analysis of any encoder, an equally good or better decoder is required, in AV1 dav1d(Dav1d is a AV1 Decoder) is the best choice.
AreWeCompressedYet is always a better choice, the fundamental issue here is faster and rapid analysis, there would be a trade-off on more accurate results which is done on AWCY but for research and development purpose, this works better.
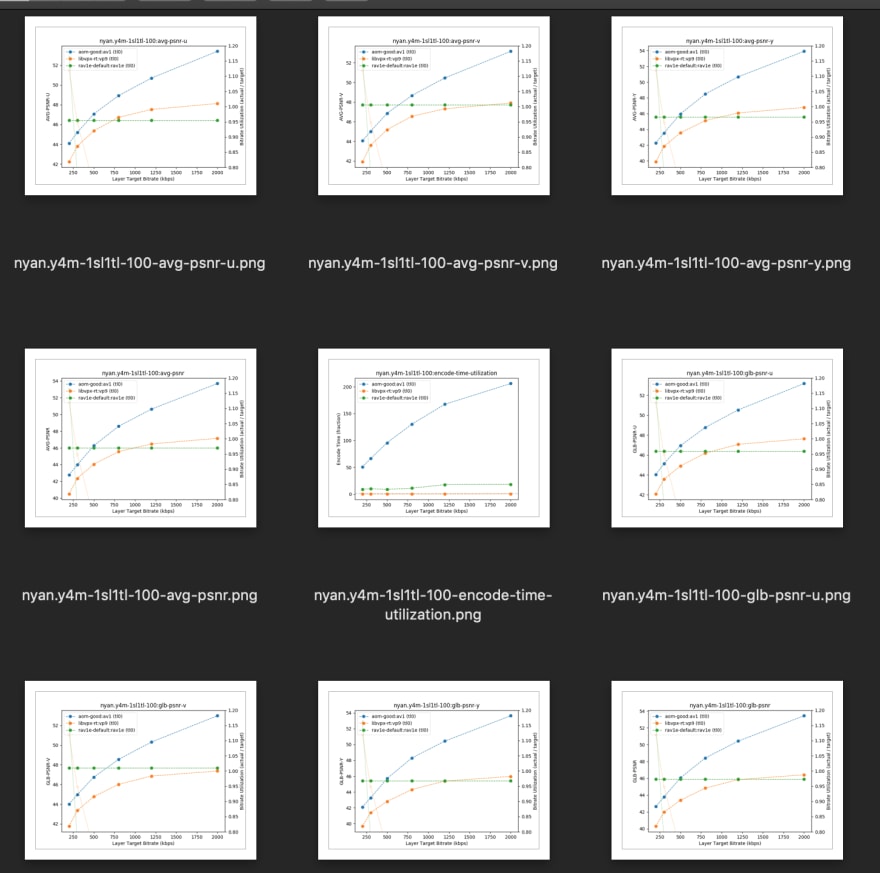
The figures depict the variation of different encoders by producing more than 80 different graphs using this tool which also includes frame data with varying bitrates.
Command which is used to do encoding comparison between multiple encoders including rav1e:
$ wget https://mf4.xiph.org/~ltrudeau/videos/nyan.y4m
$ ./generate_data.py --out=lib-rav1e.txt --encoders=aom-good:av1,
libvpx-rt:vp9,rav1e-default:rav1e nyan.y4m
$ python generate_graphs.py --out-dir rav1e_graphs lib-rav1e.txt
V-Frame
v-frame is a library released by Team rav1e in March 2020, v-frame is library extracted from rav1e to have Video Configurations structures and it's missionary.
v-frame have moved the following to a separate library:
Pixel: The pixel is located in
v_frame/src/pixel.rswhere there are several methods viz, Trait for casting between Primitive Types (CastFromPrimitive) like u8,u16, i16, i32. Types of Pixel that can be used, in v-frame is U8, used for 8-bit pixels, and U16 used for higher bitrate (HBDs) like 10 or 12 bits per pixel. The main trait of Pixel which is a type that can be used as a pixel type. v-frame's pixel is traits is similar to what the pixel is in rav1e.Math: The Plane abstraction is using different maths functions like the floor, the ceiling of log2, aligning with the power of 2 and also then shifting values, finding Most Significant Bits, and rounding. These are just changed location form rav1e's util to
v_frame(src/util/math.rs->v_frame/src/math.rs)-
Plane: Plane in
v_frameis again similar to what is being found in rav1e. In the Plane implementation wrap function is being modified or changed tofrom_slicewhere the input arguments are also changed to Address of an Array of Type Pixel(&[T]) instead of Vector of type(Vec<T>) so a better representation of data which is easier refutable rather than an enclosing in a vector, and replacing the subsequent function of wrap withfrom_slice. For example:Plane:::wrap(data, width)->
Plane::from_slice(&data, width) Chroma Sampling: Moving the ChromaSampling to v-frame so the Frame structure can use this. There are few things which are modified for cross-compatibility. Firstly, there is serialize feature which is being used by chromaSampling API which is using serde library with
derivefeature as a dependency. This is added as a feature among main Cargo definition as it is an optional dependency and sharing dependency is clean in rust.Frame: Moving of Frame is not a straightforward method among the v-frame as it was having a lot of dependencies, function calls. The changes should be minimal so it will be easier to adapt an external Frame Structure in upstream.
-
Earlier padding constant was present inside frame implementation. Now, it is moved outside the implementation.
const LUMA_PADDING: usize = SB_SIZE + FRAME_MARGIN;(L23) Luma padding is required for new frame allocation, while it is not available in the initialisation of new frame outside rav1e. Now it is required to initialise frames with padding constant as an additional argument for calculation of chroma padding.
-
In favour of minimal changes to upstream, a new trait FrameAlloc for Frame Structure is defined in upstream(rav1e), which defines new function without padding constant and returns the value.
{ /// Public Trait Interface for Frame Allocation pub trait FrameAlloc { /// Initialise new frame default type fn new(width: usize, height: usize, chrop_sampling: ChromaSampling) -> Self; } impl<T: Pixel> FrameAlloc for Frame<T> { /// Creates a new frame with the given parameters. /// new function calls new_with_padding function which takes /// luma_padding as parameter fn new( width: usize, height: usize, chroma_sampling: ChromaSampling, ) -> Self { v_frame::frame::Frame::new_with_padding( width, height, chroma_sampling, LUMA_PADDING ) } }For more details check src/frame/mod.rs
Likewise, there are new simple trait functions for Calculating Padding (FramePad), for the new tile of a frame(AsTile) which has functions for tiles and mutable tiles(as_tile, as_tile_mut) for Frame because these functions are written inside Frame implementation. These are encoder specific ones which can be isolated from the v-frame.
AV-Metrics
AV-Metrics is a library introduced by Rust Audio-Video(Rust-AV) organisation which is targeted to measure the quality of compressed video comparing with uncompressed video and gives an output which consists of
-
PSNR: Peak Signal to Noise Ratio or formally known as PSNR, is a traditional signal quality metrics measured in decibels. It is directly derived from mean square error(MSE) or its square root (RMSE). The formula being used to calculate is,
20 * log10 { (MAX / RSE)}or
10 * log10 ( MAX^2 / MSE )This metric is being applied to both Luma(Y) and Chroma Planes (Cb/Cr). Also to be added that the error is computed over all the pixels in the video.
-
APSNR: Aligned PSNR is a metrics which is used to improve the accuracy of conventional PSNR. In APSNR there defines a dynamic window size as\
w = sumFL + 1Where,
w= window size,sumFL= total of frame loss,APSNR and PSNR are related but it is not possible to calculate full-video APSNR from whole-video PSNR, APSNR comes from a different method of averaging together the per-frame PSNRs.
PSNR-HVS: The Peak Signal-to-Noise Ratio for the Human Visual System (PSNR-HVS) metric performs a DCT(Discrete Cosine Transformation) of 8x8 blocks of the image, weights the coefficient and calculates the PSNR of those coefficients. In AV-Metrics, weights are taken by Daala Tools. The normalized inverse quantisation matrix for 8x8 DCT is not the JPEG based matrix and better correlation to Mean Observer Score(MOS) than PSNR.
-
SSIM: Structural Similarity Image Metrics(SSIM) is a still image quality metric introduced which computes a score for each individual pixel, using a window of neighbouring pixels after which the scores are averaged to produce a global score for the entire image. Original Paper produces a score between 0 and 1. In other words, the measurement or prediction of image quality is based on an initial uncompressed or distortion-free image as a reference. SSIM is designed to improve over traditional methods such as PSNR, MSE. For making it more linear in accordance with BD-Rate computation for videos.
10 * log10(1-SSIM) MSSIM: Multi-Scale SSIM(MSSIM is a variant of SSIM computed over subsampled versions of an image. It is designed to be a more accurate metric than SSIM. The multi-Scale method is a convenient way to incorporate image details at different resolutions. Inputs are a reference and distorted image signals, the system iteratively applies a low-pass filter and downsamples the filtered image by a factor of 2.
CIEDE2000: CIEDE200 is a metric based on CIEDE color distances. It generates a single score taking all three(Y, Cb, Cr) Chroma Planes. Like other metrics, CIEDE200 does not consider Structural similarity. Implementation of CIEDE2000 in AV-Metrics includes lookup tables, binomial series and multiple conversions of different colour metrics.
These are very much required for Objective Video Quality Assessment. Objective Assessments are done in place of subjective Video Quality Assessment for easy and iterative experiments. Most of the above metrics apply to luma planes, and individually to planes in frames.
Integration of v-frame in AV-Metrics
Migrating to v-frame type in AV-Metrics is very much required because common definitions and structures so it can be integrated easily into encoders and will be faster.
Introduction of v-frame as a crate: The v-frame is being added as a dependency in the Cargo.toml of the AV-Metrics.
Using v-frame's Plane instead of PlaneData: Earlier the FrameInfo Structure had planes of type PlaneData which is having a width, height and data of type Vec as elements. But all the data are present in the Plane struct itself which is found in v-frame. The PlaneConfig from Plane Structure for getting the video Width, Height will be used.
Improvising preliminary checks of input video: Earlier the PlaneData Implementation has checks for width, the height of both input videos to find any mismatch, now the EncoderConfig from v-frame can be used to validate both, thus giving strict check because PlaneConfig has more than width and height like Data stride, Allocated height in Pixels, Width, Height, Decimator along the X and Y axis, Number of padding pixels on right and bottom, and also X and y where the data starts. This is made plausible by having a trait PlaneCompare for Plane.
-
Addition of ChromaWeight Trait: The chroma weight function from chroma sampling implementation is introduced as a trait. The weight is defined as follows, these are nothing but the relative impact of the chroma planes compared to luma.
ChromaSampling::Cs420 => 0.25 ChromaSampling::Cs422 => 0.5 ChromaSampling::Cs444 => 1.0 ChromaSampling::Cs400 => 0.0 Using Pixel from v-frame
Having Stride for calculation: Currently, the assertion in the calculation of PSNR-HVS checks plane's length "=" with the product of width and height which is replaced with ">=" product of stride value and height, so more strict check gives better results. During the initial tests of integration to encode, it was noticed that without this strict, encoder crashes and panics.
- assert!(plane1.data.len() == width * height);
+ assert!(plane1.data.len() >= stride * height);
A large chunk of it has been scrapped from this post as it not able to render the markdown here,
Please hop to my personal blog for reading it
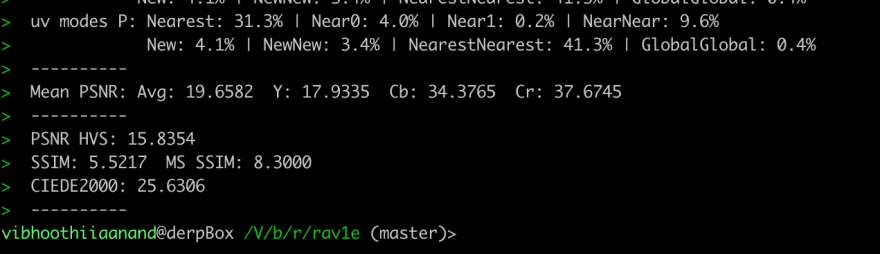
How it looks now!!
Thanks
I would like to thank to Luca Barbato(lu_zero), Josh Holmer(soichiro), David Micheal Barr(barrbrain), Nathan Egge(unlord), Christopher Montgomery(xiphmont) and also all others from Team rav1e for the continous help and debugging, reviewing of the whole research work.
Freely,
~mindfreeze





Top comments (0)