Welcome to the second article on this series "Writing an init with Go".
As mentioned on first article, we're making an init with a decoupled service-launcher. This way we keep the PID 1 small on features (just added a handler for SIGUSR2 to reboot with kexec today).
Something being argued against decoupling service management form PID 1 (systemd has this coupled) is the service manager won't be able to track processes if they fork(2) away. That's almost true and is a caveat on the current code.
Hands on
The first thing that comes to our head is "we have to initialize all services" and that's true, but there is a prerequisite on that: filesystems are not mounted at this moment (or we don't expect anything but / to be mounted).
Buut, first we need to watch signals so we exit properly when killed.
Signals
A very basic thing here: we watch for SIGINT (PID 1 will kill us with that signal when a reboot(2) is needed) in order to do the teardown. And SIGCHLD is needed to notify process watchers to check if their process is alive (we call this the deadChildrenChannel and will take over this on services section)
Filesystems
So here we start the real work, we mount some needed tmpfs filesystems (/dev and others are already mounted at the time init is run). Our current approach is to exec mount -a and done, everything in fstab is mounted now. This is too lazy, to be fair filesystems don't get too much love here. This is truly a point to improve.
Call to unmount is deferred so it gets executed on main() exit (maybe a panic).
Services
Here is where the fun begins. All this work is done on the services package, in case you want to give it a look first.
Each service is a yaml file because, who doesn't like yaml?
Description of units is very basic and near of the underlying
cmd/exec.Cmd struct (e.g. arguments are an array of strings and are separated from the exec line, which will be looked on $PATH).
A service looks like this 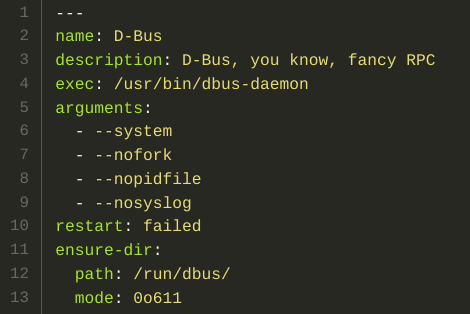
After all units are read, their names are mapped so it's easier to lookup dependencies by their name. (We'll talk about them on the Dependencies section).
After units are read they are checked as they must have a valid config (no empty name, no empty exec line and valid restart value). Dependencies whose yaml cannot be parsed or config is invalid are skipped (not included on the dependencies slice) and reported to stderr.
Then we move on...
Launching services
Each service may have dependencies, so we start first the services w/o dependencies. Those are launched in parallel with a max goroutine count of runtime.NumCPU().
Then the rest of services which are not started yet are launched. Their dependencies are looked on the services map and cached on a field of the Service struct. If there are dependencies not found or a basic cyclic dependency chain is detected, dependency will be skipped with an error.
Each Service struct has an Start function that gets called. Note that we call all this functions in parallel w/o any concurrency control (I mean, the number of goroutines being launched) because most of them will be sleeping while their dependencies get started.
We're starting to talk about dependencies, so let's address them.
Dependency management
This is the most complex thing on this service launcher.

Dependencies have a lot of theory but copying from the systemd devs (given a service A that depends on B):
- Service A has to be started, we ensure B is running (This is working)
- When service B is stopped, all services depending on it have to be stopped (including A). This is not working (you just shot your feet IMO). Anyway it would be cool but challenging to do this type of traceback finding dependents (we only look for dependencies ATM).
So basic dependency management is done. I came across 3 ways of handling dependencies before settling with the "launch every service with dependencies concurrently and wait for dependencies to be started (or errored) before we really start (or error on dependency failed) each service".
After all dependencies are settled the service is started (call exec) but if one of them has an error (bad config or failed to start), service will exit with error w/o trying to start it.
Tracking children
Why do we need tracking?
Well, you may not like agetty being killed after you log out. You may want it to be restarted so you can login again. We need to watch the agetty process to achieve this.
After a service is started, we have it's main process PID on the os.Process type so we can track it. Tracking processes isn't free, the current approach is to have a goroutine for each service.
This goroutine is almost always sleeping and waked up on demand, meaning that unless a process attached to service-launcher is dead (we get SIGCHLD), no one will move a finger.
Also tracker goroutines have a context. If a context exits, goroutine will return immediately.
This goroutine has a given design due to some limitations on the exec.Process type. That struct has a Wait function, but it doesn't allow context cancellation and as such, we can't use it. Instead we use the syscall.Wait4 with WNOHANG on flags. This way we can probe our process aliveness w/o locking until it exits and wait for another dead child to be reported from channel to check it again.
It isn't the best approach but it seems simple.
Who notifies of a "dead child"? The signal watcher receives from kernel a SIGCHLD (but don't say the exact PID hah!) so we notify all Services so they can see if the dead children is theirs. Note that kernel won't be repareting dead children to our PID so one of the services must match. Then the watcher can start doing the needed actions.
Needed actions are basic, but I think it's enough. You can specify a policy to restart the process, "always" (main process exists and we start it again. You may not like to do this on forking processes), "failed" (only restarted if main process exit!=0) or "never" (process is waited and it does nothing even on errors).
As said, when a process fork(2)s we're not notified and can't follow it. See the article by Lennart Poettering "Rethinking PID 1", it has a lot of interesting things. He talked about using cgroups so we're able to control child processes of our current service.
This project has not implemented cgroups still, but may do it.
Killing processes
The time has arrived. On teardown (or stop command received from socket, we'll be over the socket in a minute) we have to kill all services processes.
Again, the current approach is to kill the main process. The expected behavior of a process when it starts another is to kill all of them and don't leave those processes floating as they won't be notified of the shutdown and may lose information or block an unmount operation.
Cgroups may help (and systemd has a good approach at killing all processes in the cgroup).
So we're done with services. We parsed files, started them and also stopped them. Restarting services is simple. We stop the watcher (so we don't have to think on what will that goroutine do), call Stop function and then the Start function again.
The socket
We're not using dbus nor anything fancy. Just an unix socket.
Socket is exposed with mode 600 (owner is root OFC) on /run/service-launcher.sock (see socket/socket.go)
You can connect to the socket using openbsd-netcat and writing things or using the slc included tool (<30 lines of Go) to send commands like slc reboot.
Commands are very basic:
- Power management: Kill PID 1 with needed signal to achieve this.
-
reboot: SIGINT -
poweroff: SIGUSR1 -
kexec: SIGUSR2
-
- Service management
-
stop,start,restart: With service name as argument, do that action over a service. -
list: list all services and their brief status -
status: get current status report for a given service (as argument).
-
- Journal (we'll be over this on a sec)
-
journal: with the service as argument, get journal for that service (ordered by date asc)
-
Those are the available commands at the moment. On a near future we need more control over journal and some other things (see the planned steps on the next article).
Journal
All service managers need a journal to store the stdout/err of the started services,  try debugging without logs heh!.
try debugging without logs heh!.
Journal here is in-memory, so it's volatile and won't retain anything between reboots (it does between service restarts).
It's implementation is very basic and can be found at journal/journal.go.
What did we (at least I did) learn?
Making a service-launcher is fun and full of challenges. We may think at first it only launches processes, but the logic under it is huge and requires a lot of things.
To be honest, side logic didn't receive too much love, so you may notice some bugs and sure, limitations.
What's next?
Talk is cheap. Show me the code
~ Linus Torvalds
That's true, we left a lot of theory above. The repository is on mrvik/go-pid1 so you may want to take a look (and maybe try) this thing on a VM.
On the next article we'll be trying it and seeing how it works (could we start systemd as just another service?) we'll be over it.
I hope you liked this travel over what should we expect from a PID 1. Please, don't get me wrong, I'm not aiming to replace anything nor being just another competing standard but a proof of concept of something new, decoupled from PID 1.
See you next time!





Top comments (0)