
Photo por Priscilla Du Preez no Unsplash
Após a versão V8.5.9, a V8 mudou seu pipeline antigo (composto de Full-Codegen e Crankshaft) para um novo pipeline que usa dois compiladores novinhos em folha, o Ignition e o TurboFan. Esse novo pipeline é principalmente o motivo pelo qual o JS é muito rápido hoje em dia.
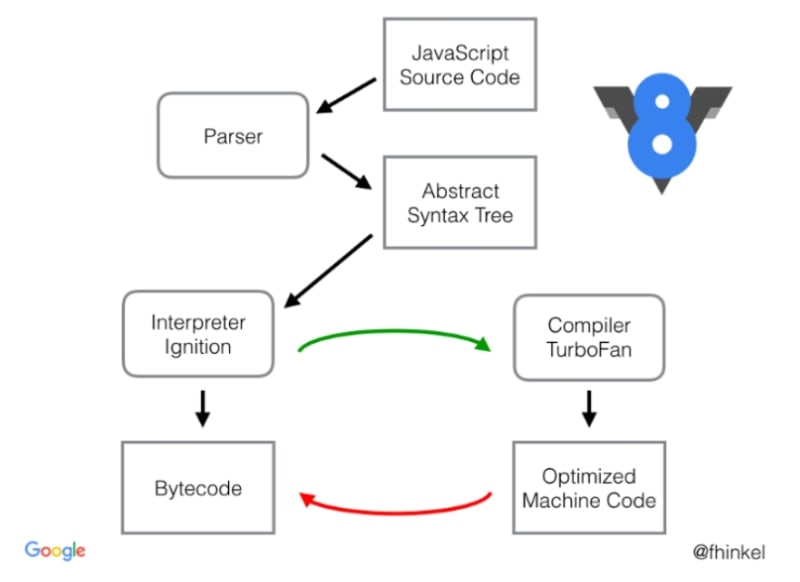
Basicamente, as etapas iniciais não foram alteradas, ainda precisamos gerar um AST e analisar todo o código JS; no entanto, o Full-Codegen foi substituído pelo Ignition e o Crankshaft foi substituído pelo TurboFan.
Ignition

Ignition é um interpretador de bytecode para o V8, mas por que precisamos de um interpretador? Compiladores são muito mais rápidos que um interpretador. O Ignition foi criado principalmente com o objetivo de reduzir o uso de memória. Como a V8 não possui um parser, a maioria dos códigos é analisada e compilada em tempo real; portanto, várias partes do código são realmente compiladas e recompiladas mais de uma vez. Isso bloqueia até 20% da memória no heap do V8 e é especialmente ruim para dispositivos com pouca capacidade de memória.
Uma coisa importante é que o Ignition não é um parser, ele é um interpretador de bytecode, o que significa que o código está sendo lido em bytecode e emitido em bytecode. Basicamente, o que o Ignition faz é pegar um fonte em bytecode e otimizá-lo para gerar um bytecode muito menor e remover o código não utilizado também. Isso significa que, em vez de compilar o JS em tempo real em lazy load, como antes, o Ignition apenas pega o script inteiro, analisa e compila tudo de uma vez, reduzindo o tempo de compilação e também gerando um footprint de bytecode muito menor.
No final das contas, essa era a pipeline antiga:

Veja que este é o passo que está entre a pipeline antiga e a nova, a seguir temos a nova pipeline.
Que se transformou nisso:

Isso significa que o AST, que era a fonte da verdade para os compiladores, agora é alimentado no Ignition, que percorre todos os nós e gera bytecodes que são a nova fonte para todos os compiladores.
Essencialmente, o que o Ignition faz é transformar código em bytecodes, fazendo coisas assim:
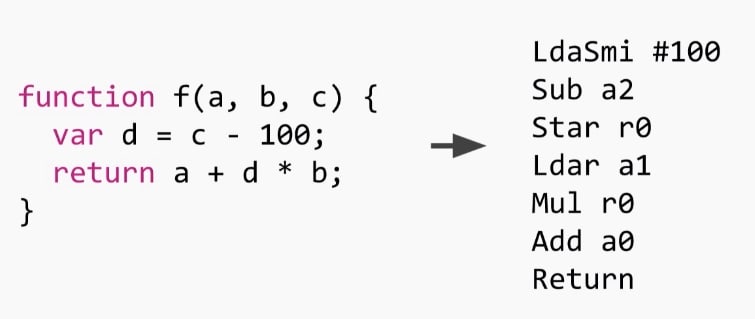
Como você pode ver, ele é um interpretador baseado em registro, você pode ver os registros sendo manipulados nas chamadas de cada função. r0 é a representação de uma variável local ou de uma expressão temporária que precisa ser armazenada na pilha. Imagine que você tem um arquivo de registradores infinito, pois esses não são registradores de máquina, eles são alocados no frame da pilha quando iniciamos. Nesta função específica, há apenas um registrador usado. Uma vez iniciada a função, r0 é alocado na pilha como undefined. Os outros registradores (a0 até a2) são os argumentos para essa função (a,b e c) que são passados pelo receptor, então eles também estão na pilha, isso significa nós podemos operá-los como registradores.
Há também outro registrador implícito chamado accumulator, que é armazenado nos registros da máquina, onde toda a entrada ou saída deve ir, inclusive os resultados das operações e alocações de variáveis.
Ao lermos o bytecode vamos ter as instruções a seguir:
LdaSmi #100 -> Carrega a constante 100 no acumulador (Smi é Small Integer)
Sub a2 -> Subtraímos da constante, o valor do argumento a2 (que é o c) e armazenamos o resultado no acumulador
Star r0 -> Pegamos o valor do acumulador e armazenamos em r0
Ldar a1 -> Lemos o valor do argumento a1 (b) e colocamos no acumulador
Mul r0 -> Multiplicamos r0 pelo acumulador e o resultado vai de volta para o acumulador
Add a0 -> Soma o primeiro parâmetro a0 (a) ao acumulador e armazenamos o resultado no acumulador
Return -> Retorna
Nós vamos falar mais sobre bytecodes no nosso próximo artigo
Depois de percorrer o AST, o bytecode gerado é alimentado um de cada vez para um pipeline de otimização. Portanto, antes que o Ignition possa interpretar qualquer coisa, algumas técnicas de otimização, como otimização de registro, otimizações peephole e remoção de código morto, são aplicadas pelo parser.

O pipeline de otimização é seqüencial, o que possibilita ao Ignition ler bytecodes menores e interpretar um código mais otimizado.
Portanto, este é o pipeline completo antes do parser para o Ignition:

O gerador de bytecode passa a ser outro compilador que compila no bytecode em vez do código de máquina, que pode ser executado pelo interpretador.
O Ignition não é escrito em C++, pois precisaria de trampolines entre as funções interpretadas e as funções que são JiT, pois as formas de chamada são diferentes.
Também não está escrito em assembly manual, como muitas coisas no V8, porque precisaria ser portado para 9 arquiteturas diferentes, o que não é prático.
Em vez de fazer essas coisas, o Ignition é basicamente escrito usando o back-end do compilador TurboFan, um macroassembler de gravação única e compilado para todas as arquiteturas. Além disso, podemos ter uma otimização de baixo nível que o TurboFan gera nativamente.
Turbofan

TurboFan é o compilador de otimização do JS que, agora, substituiu o CrankShaft como o compilador JIT oficial. Mas nem sempre foi assim. O TurboFan foi inicialmente projetado para ser um bom compilador webasm. a versão inicial do TurboFan era realmente muito inteligente, com muitas otimizações de tipo e código que teriam um desempenho muito bom no JavaScript geral.
O TurboFan usa o que é chamado de representação em Sea-of-Nodes que, por si só, aumentaram muito o desempenho geral de compilação do código JavaScript. A idéia do TurboFan é implementar tudo o que o Crankshaft já possuía, mas também possibilitar que o V8 compile um código ES6 mais rápido, com o qual o Crankshaft não sabia como lidar. Portanto, o TurboFan começou como um compilador secundário apenas para o código ES6:
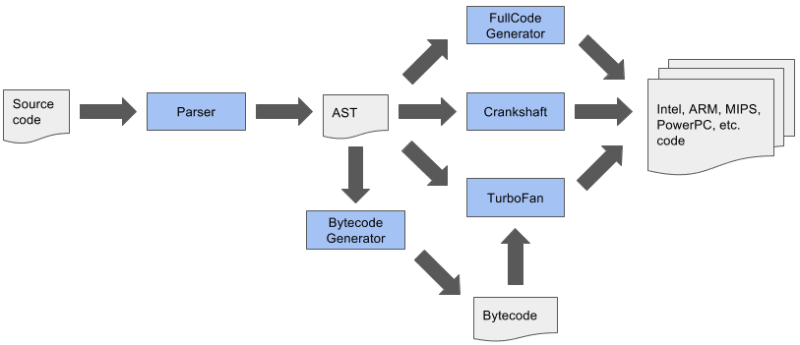
O problema disso, além da complexidade técnica, é que os recursos de linguagem devem ser implementados em diferentes partes do pipeline e todos esses pipelines devem ser compatíveis entre si, incluindo as otimizações de código que todos geraram. A V8 usou esse pipeline de compilação por um tempo quando o TurboFan não conseguiu lidar com todos os casos de uso, mas, eventualmente, esse pipeline foi substituído por outro:

Como vimos no capítulo anterior, o Ignition passou a interpretar o código JS para bytecode, que se tornou a nova fonte de verdade para todos os compiladores no pipeline, o AST não era mais a única fonte de verdade na qual todos os compiladores confiavam durante a compilação código. Essa simples alteração possibilitou várias técnicas de otimização diferentes, como a remoção mais rápida de código morto e também muito menor espaço de memória e inicialização.
Além disso, o TurboFan é claramente dividido em três camadas separadas: o front-end, a camada de otimização e o back-end.
A camada de front-end é responsável pela geração de bytecode, executada pelo interpretador Ignition, a camada de otimização é responsável apenas pela otimização do código usando o compilador de otimização do TurboFan. Todas as outras tarefas de nível mais baixo, como otimizações de baixo nível, agendamento e geração de código de máquina para arquiteturas suportadas, são tratadas pela camada de back-end - o Ignition também conta com a camada de back-end do TurboFan para gerar seu bytecode.
Somente a separação das camadas trouxe 29% menos código específico de máquina do que antes no fonte do V8.

Picos de Má-Otimização
Em suma, o TurboFan foi projetado e criado exclusivamente para lidar com uma linguagem em constante evolução como o JavaScript, algo que o Crankshaft não foi feito pra fazer.
Isso se deve ao fato de que, no passado, a equipe do V8 estava focada em escrever código otimizado e negligenciou o bytecode que o acompanhava. Isso gerou algumas falhas de desempenho, o que tornou a execução do runtime bastante imprevisível. Às vezes, um código que estava sendo executado rapidamente entrava em um caso em que o CrankShaft não era capaz de lidar e, em seguida, isso podia ser desoptimizado e executado até 100 vezes mais devagar que o anterior. Este é o que chamamos de picos de má-otimização.
E a pior parte é que, devido à execução imprevisível do código do runtime, não foi possível isolar, nem resolver esses problemas. Por isso, cabia aos desenvolvedores escrever um tipo de "CrankScript", que era um código JavaScript que foi criado para deixar o Crankshaft feliz.
Otimização prematura
As otimizações prematuras são a fonte de todo o mal. Isso é verdade mesmo para compiladores. Nos benchmarks, ficou comprovado que os compiladores de otimização não eram tão importantes quanto o interpretador, pelo menos para o V8. Como o código JavaScript precisa ser executado de maneira rápida, não há tempo para compilar, recompilar, analisar e otimizar o código antes da execução.
A solução para isso estava fora do escopo do TurboFan ou do Crankshaft, e foi resolvida com a criação do Ignition. A otimização do bytecode gerado pelo parser levou a uma AST muito menor, o que levou a um bytecode menor, que finalmente levou a um uso de memória muito menor, pois outras otimizações poderiam ser adiadas para serem feitas depois. E a execução do código por mais tempo levou a mais feedback de tipos para o compilador de otimização e, finalmente, isso levou a menos desoptimizações devido a informações incorretas de feedback de tipos.
Conclusão
Não deixe de acompanhar mais do meu conteúdo no meu blog e se inscreva na newsletter para receber notícias semanais!





Top comments (2)
Parabéns, muito bom e obrigado pela tradução, muito interessante conhecer essa plataforma por de baixo dos panos. Sensacional!
Sensacional acompanhar essa série de artigos e entender um pouco mais a plataforma por de baixo dos panos.