
Introduction
Welcome to Part 2 of our series on the Java Collections Framework! In this continuation, we'll explore more advanced aspects of this essential framework, diving into key interfaces and classes that make data management in Java both efficient and powerful. Get ready to level up your Java skills and expand your toolkit for handling collections and data structures.
We have discussed there List and Queue Interfaces and if you haven't read first part then you read it here.
Set Interface
The Set interface represents an unordered collection of unique elements. Unlike lists, sets do not allow duplicate values, making them ideal for scenarios where you need to ensure distinct elements. The Set interface includes several methods for adding, removing, and checking the presence of elements. Popular implementations of the Set interface are HashSet, LinkedHashSet, and TreeSet, each with its own characteristics and use cases. By using Set, you can efficiently manage collections of elements without worrying about duplicates, making it a valuable tool in Java programming.

HashSet
HashSet provides a collection of unique elements without any specific order. This means that you can store elements in a HashSet, and it will automatically ensure that duplicates are not allowed. It is highly efficient for checking the presence of elements and adding or removing elements from the set. While elements are not stored in a particular sequence, this data structure is particularly useful when you need to maintain a collection of items where uniqueness is a priority, and the order of elements doesn't matter.

Here's an example of how to use a HashSet:
import java.util.HashSet;
public class HashSetExample {
public static void main(String[] args) {
HashSet<String> fruits = new HashSet<>();
// Adding elements
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Cherry");
// Attempting to add a duplicate element (it won't be added)
fruits.add("Apple");
// Iterating through the set
for (String fruit : fruits) {
System.out.println(fruit);
}
}
}
In this example, "Apple" is added only once, demonstrating HashSet's uniqueness property. When you iterate through the HashSet, the order of elements may not be the same as they were added, highlighting its unordered nature.
LinkedHashSet
LinkedHashSet combines the features of both HashSet and LinkedHashMap, offering a collection of unique elements with predictable iteration order. Unlike HashSet, LinkedHashSet maintains the order in which elements were inserted into the set. This means that when you iterate over a LinkedHashSet, the elements will be returned in the order they were added. This can be useful in situations where you need both uniqueness and a specific order for your elements.
Let's consider a library catalog system. In this scenario, you want to maintain a list of books in a way that allows you to keep track of unique titles while preserving the order in which the books were added to the catalog. You decide to use a LinkedHashSet to store the book titles. As new books arrive at the library, you add their titles to the LinkedHashSet. Because LinkedHashSet maintains the insertion order, you can easily browse the catalog in the order the books were acquired, making it convenient for library staff to locate and manage the collection efficiently.
Here's a simple Java program that demonstrates the usage of a LinkedHashSet:
import java.util.LinkedHashSet;
public class LinkedHashSetExample {
public static void main(String[] args) {
// Create a LinkedHashSet to store unique elements while preserving insertion order
LinkedHashSet<String> fruitsSet = new LinkedHashSet<>();
// Adding elements to the LinkedHashSet
fruitsSet.add("Apple");
fruitsSet.add("Banana");
fruitsSet.add("Cherry");
fruitsSet.add("Banana"); // Adding a duplicate element
// Display the elements of the LinkedHashSet
System.out.println("Fruits in the LinkedHashSet:");
for (String fruit : fruitsSet) {
System.out.println(fruit);
}
// Check if a specific element exists in the LinkedHashSet
String searchFruit = "Cherry";
if (fruitsSet.contains(searchFruit)) {
System.out.println(searchFruit + " is in the LinkedHashSet.");
} else {
System.out.println(searchFruit + " is not in the LinkedHashSet.");
}
// Remove an element from the LinkedHashSet
String removedFruit = "Banana";
boolean isRemoved = fruitsSet.remove(removedFruit);
if (isRemoved) {
System.out.println(removedFruit + " has been removed from the LinkedHashSet.");
} else {
System.out.println(removedFruit + " was not found in the LinkedHashSet.");
}
}
}
This program creates a LinkedHashSet named fruitsSet, adds several fruits (including a duplicate), displays the elements while preserving insertion order, checks for the existence of a specific fruit, and removes an element from the LinkedHashSet. It illustrates the key features of LinkedHashSet, including uniqueness and order preservation.
TreeSet
A TreeSet is a sorted collection in Java that implements the Set interface. Unlike a HashSet, which does not guarantee any specific order of elements, a TreeSet maintains elements in sorted order. This sorting is typically in ascending order, but you can customize it by providing a comparator during TreeSet creation. TreeSet uses a Red-Black Tree data structure internally for efficient sorting and retrieval operations.
Here's a brief example to demonstrate the usage of a TreeSet:
import java.util.TreeSet;
public class TreeSetExample {
public static void main(String[] args) {
// Create a TreeSet to store integers in sorted order
TreeSet<Integer> numbers = new TreeSet<>();
// Add elements to the TreeSet
numbers.add(5);
numbers.add(2);
numbers.add(8);
numbers.add(1);
// Display the elements in sorted order
System.out.println("Numbers in ascending order:");
for (int num : numbers) {
System.out.println(num);
}
// Remove an element from the TreeSet
int removedNumber = 2;
boolean isRemoved = numbers.remove(removedNumber);
if (isRemoved) {
System.out.println(removedNumber + " has been removed.");
} else {
System.out.println(removedNumber + " was not found.");
}
}
}
In this example, a TreeSet named numbers is created to store integers. When elements are added, the TreeSet automatically sorts them in ascending order. The program also demonstrates the removal of an element from the TreeSet. TreeSet is useful when you need a sorted collection of unique elements in your Java application.
Map Interface
The Map interface in Java represents a collection of key-value pairs, where each key is unique and maps to a specific value. It allows for efficient data retrieval based on keys, making it useful for tasks like looking up values by identifiers. Java provides various implementations of the Map interface, such as HashMap, TreeMap, and LinkedHashMap, each suited for different use cases. Maps are commonly used to store and manage data where the relationship between keys and values is critical. They enable quick and direct access to values based on their associated keys, enhancing the efficiency of data retrieval and manipulation in Java programs.
Imagine you're managing a restaurant. You can use a Map to represent your menu. Each item on the menu has a unique identifier (like an item code or name), and the Map associates this identifier with the item's details, such as its name, description, price, and availability. When customers place orders, you can efficiently look up menu items and calculate the total bill by referencing the Map. This application of the Map interface simplifies order processing and enhances customer service in the restaurant business.
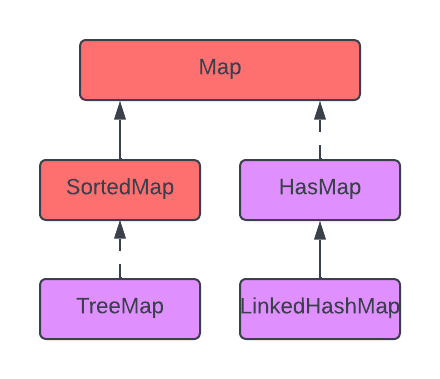
Map doesn't allow duplicate keys, but you can have duplicate values. HashMap and LinkedHashMap allow null keys and values, but TreeMap doesn't allow any null key or value.
Here are the common methods of the Map interface with their descriptions:
| Method | Description |
|---|---|
| put(K key, V value) | Associates the specified value with the specified key in this map. |
| get(Object key) | Returns the value to which the specified key is mapped, or null if this map contains no mapping for the key. |
| remove(Object key) | Removes the mapping for the specified key from this map if present. |
| containsKey(Object key) | Returns true if this map contains a mapping for the specified key. |
| containsValue(Object value) | Returns true if this map maps one or more keys to the specified value. |
| size() | Returns the number of key-value mappings in this map. |
| isEmpty() | Returns true if this map contains no key-value mappings. |
| clear() | Removes all of the mappings from this map. |
| keySet() | Returns a Set view of the keys contained in this map. |
| values() | Returns a Collection view of the values contained in this map. |
| entrySet() | Returns a Set view of the mappings contained in this map. |
HashMap
A HashMap in Java is a fundamental data structure that facilitates the storage and retrieval of data using key-value pairs. It is a part of the Java Collections Framework and provides efficient access to values based on their associated keys. HashMaps use a hash function to compute an index into an array where the values are stored, making retrieval swift even for large datasets. They do not allow duplicate keys and permit one null key along with multiple null values. Java developers frequently use HashMaps to implement data structures like dictionaries and associative arrays, where data is organized and accessed by unique keys, enabling efficient and fast data retrieval in various applications.

Here's a simple example of how to use a HashMap in Java:
import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
// Create a HashMap
HashMap<String, Integer> ageMap = new HashMap<>();
// Add key-value pairs
ageMap.put("Alice", 25);
ageMap.put("Bob", 30);
ageMap.put("Charlie", 22);
// Retrieve values by key
int aliceAge = ageMap.get("Alice"); // Returns 25
// Check if a key exists
boolean containsKey = ageMap.containsKey("David"); // Returns false
// Iterate over key-value pairs
for (String name : ageMap.keySet()) {
int age = ageMap.get(name);
System.out.println(name + "'s age is " + age);
}
}
}
In this example, we create a HashMap called ageMap, add key-value pairs, retrieve values by keys, check for the existence of keys, and iterate over the entries. HashMap is a versatile and widely used data structure in Java for various applications where you need to associate keys with values efficiently.
HashTable
A HashTable is similar to a HashMap but has several differences. A HashTable is a synchronized collection, which means it is thread-safe and can be used in multi-threaded applications without the need for external synchronization. It uses a hash function to map keys to values, allowing for efficient key-value retrieval. However, HashTable has become somewhat outdated, and it is recommended to use HashMap in most cases, as it offers similar functionality but is not synchronized, making it more efficient for single-threaded applications. Additionally, HashTable does not allow null keys or values, whereas HashMap permits one null key and multiple null values.
Imagine you have a magical book, and you want to keep a record of famous landmarks in different countries. This book has pages for each country, and you can write down the famous place in that country on its respective page.Whenever you want to know the famous landmark for a particular country, you simply open your magical book to the corresponding page, and there it is, just like how a HashTable lets you quickly retrieve values (landmarks) associated with specific keys (countries).

Here's a simplified representation:
import java.util.Hashtable;
public class LandmarksExample {
public static void main(String[] args) {
// Create a HashTable to store country-landmark pairs
Hashtable<String, String> landmarks = new Hashtable<>();
// Add country-landmark pairs
landmarks.put("India", "Taj Mahal");
landmarks.put("France", "Eiffel Tower");
landmarks.put("China", "Great Wall of China");
landmarks.put("USA", "Statue of Liberty");
// Retrieve and print landmarks
String landmarkIndia = landmarks.get("India");
String landmarkFrance = landmarks.get("France");
String landmarkChina = landmarks.get("China");
String landmarkUSA = landmarks.get("USA");
System.out.println("Famous Landmarks:");
System.out.println("India: " + landmarkIndia);
System.out.println("France: " + landmarkFrance);
System.out.println("China: " + landmarkChina);
System.out.println("USA: " + landmarkUSA);
}
}
In this example, the HashTable stores country-landmark pairs, allowing you to retrieve the famous landmark for each country.
LinkedHashMap
A LinkedHashMap in Java is a class that combines the features of a hash table and a linked list to store key-value pairs. It maintains the order of elements based on the insertion sequence, allowing predictable iteration. This means that when you iterate through a LinkedHashMap, the elements are returned in the order in which they were added. It provides efficient access to elements via hashing and preserves the order of insertion, making it useful for scenarios where you need both quick access to elements and a predictable iteration order.
A LinkedHashMap in Java can be compared to a numbered list of tasks you need to accomplish in a day. Each task (an entry) is associated with a unique number (the order of insertion), and you want to maintain the order of tasks as you complete them. As you go about your day, you keep track of your tasks in this list. If you finish one task, you cross it off, and if you add a new one, you simply append it to the end of the list. This way, your tasks are not only organized but also executed in the order you added them. Similarly, a LinkedHashMap maintains the order of key-value pairs based on the insertion sequence, allowing you to access and manipulate them in a predictable order.
Here's a simple Java program that demonstrates how to use a LinkedHashMap to store and retrieve country-capital pairs:
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapExample {
public static void main(String[] args) {
// Create a LinkedHashMap to store country-capital pairs
LinkedHashMap<String, String> countryCapitalMap = new LinkedHashMap<>();
// Add country-capital pairs
countryCapitalMap.put("India", "New Delhi");
countryCapitalMap.put("USA", "Washington, D.C.");
countryCapitalMap.put("China", "Beijing");
countryCapitalMap.put("France", "Paris");
// Retrieve and print the capitals of selected countries
String capitalOfIndia = countryCapitalMap.get("India");
String capitalOfUSA = countryCapitalMap.get("USA");
System.out.println("Capital of India: " + capitalOfIndia);
System.out.println("Capital of USA: " + capitalOfUSA);
// Iterate through the LinkedHashMap and print all country-capital pairs
System.out.println("All Country-Capital Pairs:");
for (Map.Entry<String, String> entry : countryCapitalMap.entrySet()) {
String country = entry.getKey();
String capital = entry.getValue();
System.out.println(country + " - " + capital);
}
}
}
TreeMap
A TreeMap is a class in Java that implements the Map interface and extends the AbstractMap class. It is part of the Java Collections Framework and provides a Red-Black tree-based implementation of the Map interface. TreeMap stores its elements in a sorted and balanced tree structure, which allows for efficient operations like insertion, deletion, and retrieval of elements.

A TreeMap in Java is like an organized library catalog where books (values) are sorted and arranged by their genres (keys). This data structure automatically keeps genres in alphabetical order, making it easy to find and manage books within each category efficiently. When you add a new book to the library, you simply place it in the correct genre's section in the TreeMap. This sorting and organization make TreeMap a valuable tool for tasks requiring ordered data, ensuring quick and effective access to information.
Here's a simple example of how a TreeMap can be used to store and retrieve key-value pairs:
import java.util.*;
public class TreeMapExample {
public static void main(String[] args) {
// Create a TreeMap to store age-name pairs
TreeMap<Integer, String> ageNameMap = new TreeMap<>();
// Add age-name pairs to the TreeMap
ageNameMap.put(25, "John");
ageNameMap.put(30, "Alice");
ageNameMap.put(22, "Bob");
ageNameMap.put(28, "Eve");
// Retrieve and print the names of people by their ages
System.out.println("Name of person with age 25: " + ageNameMap.get(25));
System.out.println("Name of person with age 30: " + ageNameMap.get(30));
// Iterate through the TreeMap and print all age-name pairs in ascending order of age
System.out.println("All Age-Name Pairs:");
for (Map.Entry<Integer, String> entry : ageNameMap.entrySet()) {
int age = entry.getKey();
String name = entry.getValue();
System.out.println("Age: " + age + ", Name: " + name);
}
}
}
In this example, we create a TreeMap named ageNameMap to store age-name pairs. The keys are ages (integers), and the values are names (strings). We add pairs using the put method and retrieve the names of people by their ages using the get method. When we iterate through the TreeMap, it automatically returns the age-name pairs in ascending order of age due to its sorting mechanism.
We've seen how Set implementations like HashSet, LinkedHashSet, and TreeSet cater to different needs, from unsorted uniqueness to sorted order. Similarly, Map implementations like HashMap, LinkedHashMap, and TreeMap offer varying approaches to key-value mapping, with differences in performance and ordering.
Stay tuned for the next installment as we continue this exciting journey through the world of Java collections!
Thanks for reading blog post.
If you have any queries or doubts, feel free to connect with me on Instagram. I'm here to help you with any questions you may have regarding Java or any other topic. Keep learning and exploring, and don't hesitate to reach out whenever you need assistance or clarification. Happy coding!





Top comments (1)
Great work..