
I hardly ever find myself reaching for third party monitoring services these days. I rather use the AWS native observability, monitoring and alerting services. The primary reasons being that I can use my favorite Infrastructure as Code (IaC) tool to define the infrastructure as well as the monitoring, observability and dashboards for every project in one place. I also only pay for what I use; there are no monthly subscriptions.
This blog is also available as a presentation. Reach out if you would like me to present it at an event. It consists of about 30% slides and 70% live demo.
In this two-part series, we’ll first build a bad microservice system and add observability, monitoring and alerting. The second part will focus on refactoring the code and go into more details on the decisions made.
Like most of my blogs, this one is also accompanied by code. I decided to create three microservices, each in their own repositories, with the fourth one used to reference all of them. The code is available on github: https://github.com/rehanvdm/MicroService. These microservices were designed poorly for demo purposes and to explain the importance of certain points, like structured logging. Below are all three services:
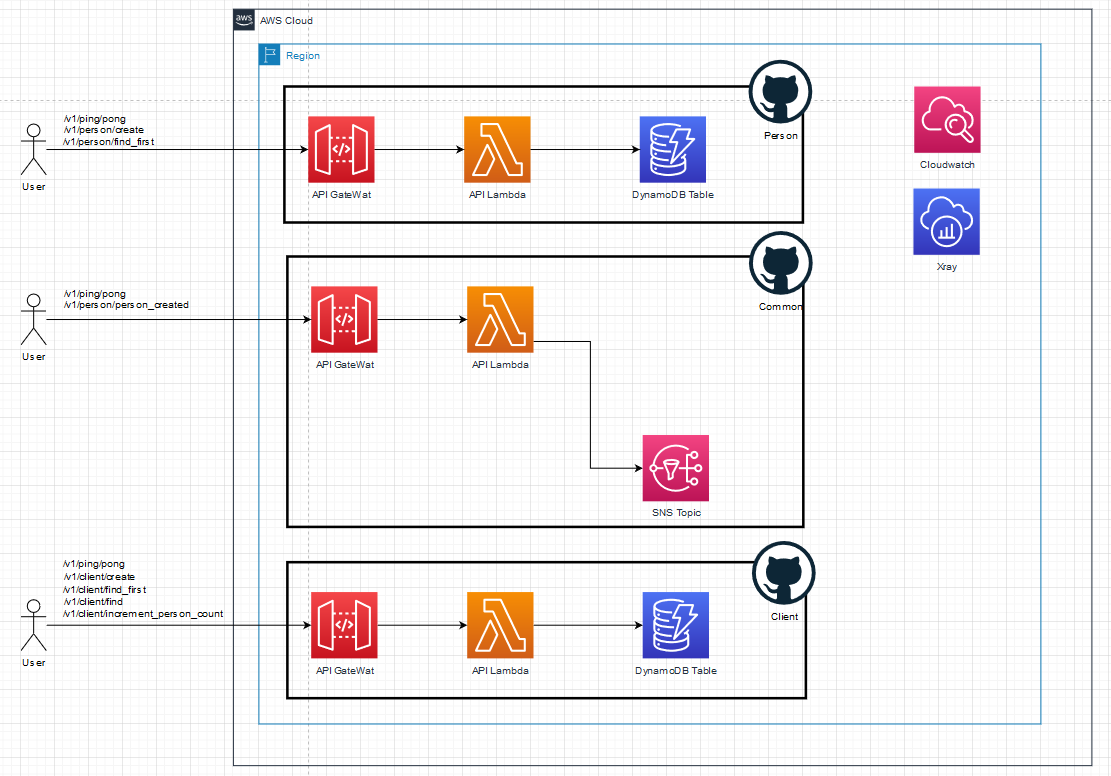
Within each project you can find an OpenAPI (part1/src/lambda/api/api-definition.yaml) file that defines the API definition for each service. AWS CDK is used and they all follow the similar stock standard CDK project layout: Typescript for the CDK and ES6 JS for the application code. NPM commands have been written to do deployments and it also contains end-to-end tests using Mocha and Chai. In addition, each service contains a detailed README inside the /part1 path. Note that I only have a single Lambda for the API endpoint and do internal routing. Yes, I believe in a Lambalith for the API!😊and also prefer JSON POST over REST (more about this later).
The client service stores clients and has basic create-client and find-client functionalities as well as an endpoint to increment the person count for a specific client. The person service also has basic create-person and find-person endpoints. When a person is created, it calls the common service which notifies me by email about the new person that was added using an SNS subscription. The common service first needs to do a lookup on the client service so that it can enrich the email. It also increments the counter on the client. Click on the image below to see the step-by-step path for creating a person:
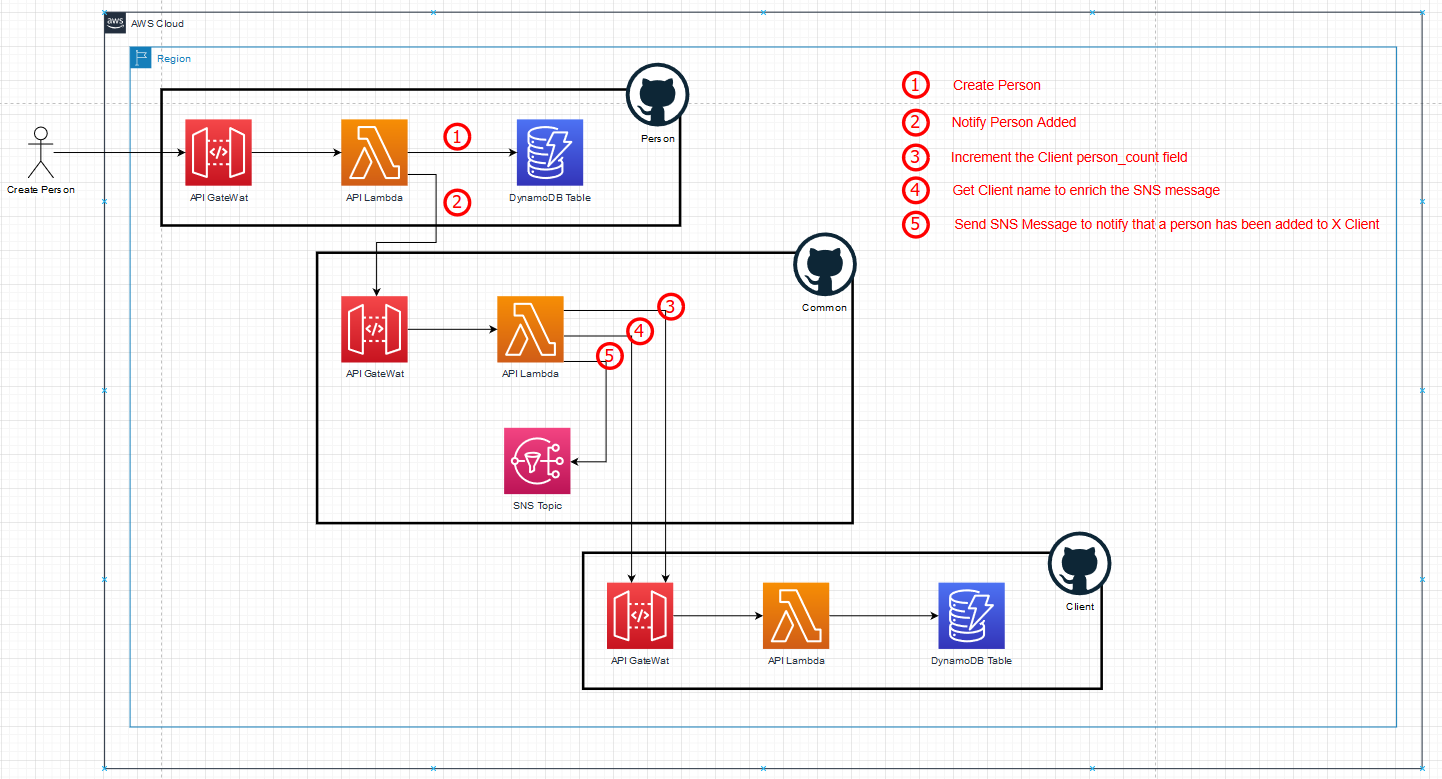
In Part 2 we will focus on refactoring and decoupling this system. That brings me to the reason why the current system is poorly designed. I purposefully created a distributed monolith.
The create-person call is highly dependent on the commonservice and does not even know that the common service is dependent on theclient service. As a result, the person service is also dragged down if eitherthe common or the client service is down. Not to mention that it now has towait for the completion of every step in the synchronous chain. This wastes moneyand increases the probability of hitting the API Gateway timeout of 29 seconds.
Let’s first look at a few generic concepts that are referenced throughout the post. Then we will look at the AWS native services.
Structured logging, types of errors and metrics
Errors
Hard Errors are infrastructure and runtime errors. You should always have alerts on these. Ex. time out, unexpected error and runtime errors not caught by try-catch blocks.
Soft Errors are completely software-defined. This is when your infrastructure and services are working but the result was undesired. An example would be that your API returned an HTTP status code 200 with a validation error message in the body.
Metrics
Business Metrics – Key performance indicators (KPIs) that you use to measure your application performance against. Ex. orders placed.
Customer Experience Metrics – Percentiles and perceived latencies that the user is experiencing. A typical scenario would be page load times. Another would be that even though your API is fast, the front-end needs to make 10 concurrent API calls when the application starts. The browsers then queues these concurrent requests and the user waits at least two or three times longer.
System Metrics – Application level metrics that indicate system health. Ex. number of API requests, queue length, etc.
Structured logging
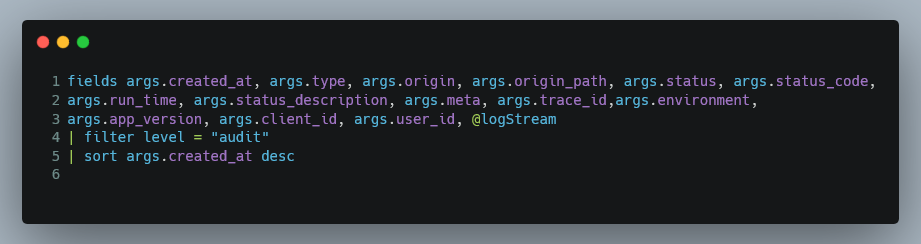
All microservices write logs in the format below. This is done by wrapping around the console class and writing in JSON format. Levels will include all your basics, like info, log, debug, error, warning, with the only new one being audit.

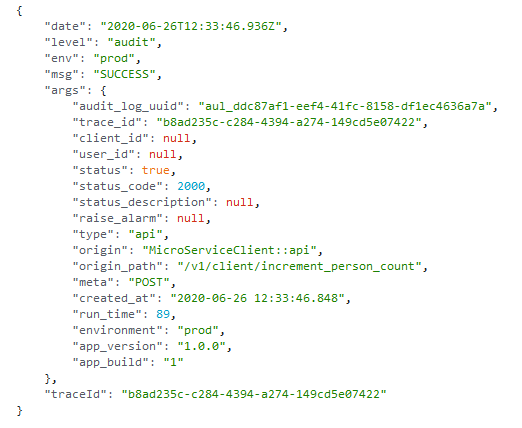
A single audit record is written per Lambda execution and gives a summary for the result of that execution. The image below shows an audit record that contains the API path, run time, status code, reason and many more fields used in the Log Insight queries later on.
The image below shows an unsuccessful execution:
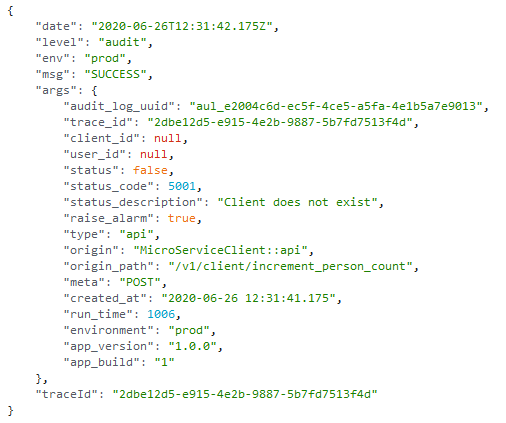
Note that the runtime is not the one reported by Lambda.There is an environment variable on the Lambda itself that indicates what thefunction timeout value is. We then subtract the _context.getRemainingTimeInMillis()_to get a close estimate to the actual reported runtime.
Let’s take a closer look at the AWS Native services that we will use.
AWS CloudWatch Logs
Logs are crucial to any application. CloudWatch stores logs in the format of log groups and log streams. Each log group can be considered a Lambda function and a stream is the executions of that Lambda function. The real magic happens when you do log insights over your structured logs.
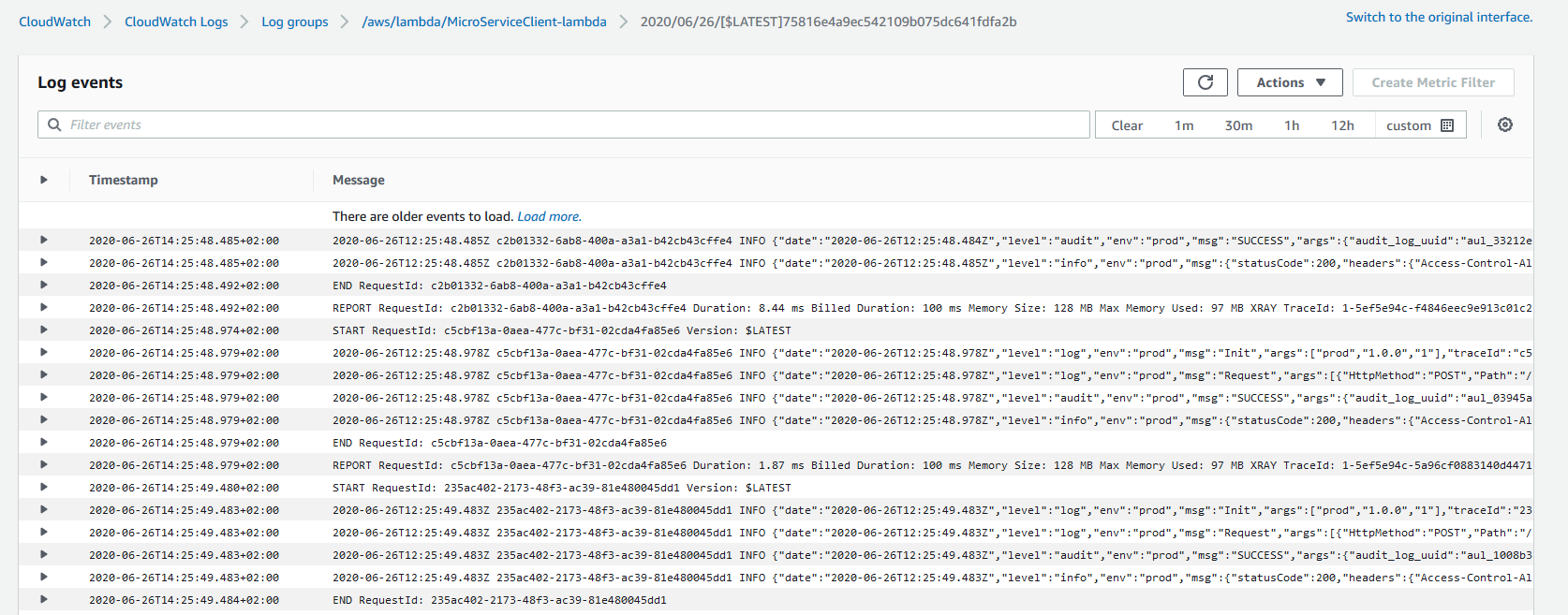
AWS CloudWatch Metrics
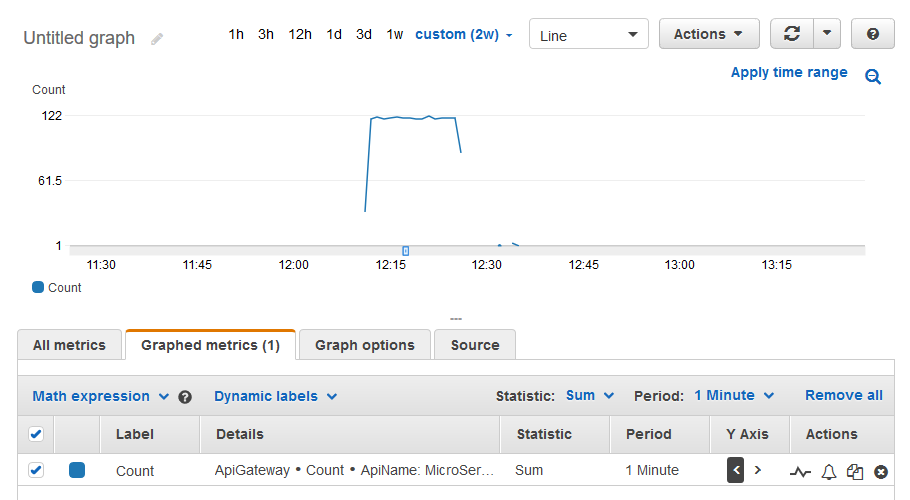
Metrics are best described as the logging of discrete data points for a system against time. These metrics can then be displayed on graphs, like; database CPU versus time or the types of API response over time. They are at the heart of many services, like dashboards, alerts and auto scaling. If you write a log line in a specific format, called the Embedded Metric Format, it automatically transforms it into a metric. Find the client libraries that help write this format here.
Below shows the amount of API calls summed by 1-minute intervals for the client API after the artillery.io load test was run.
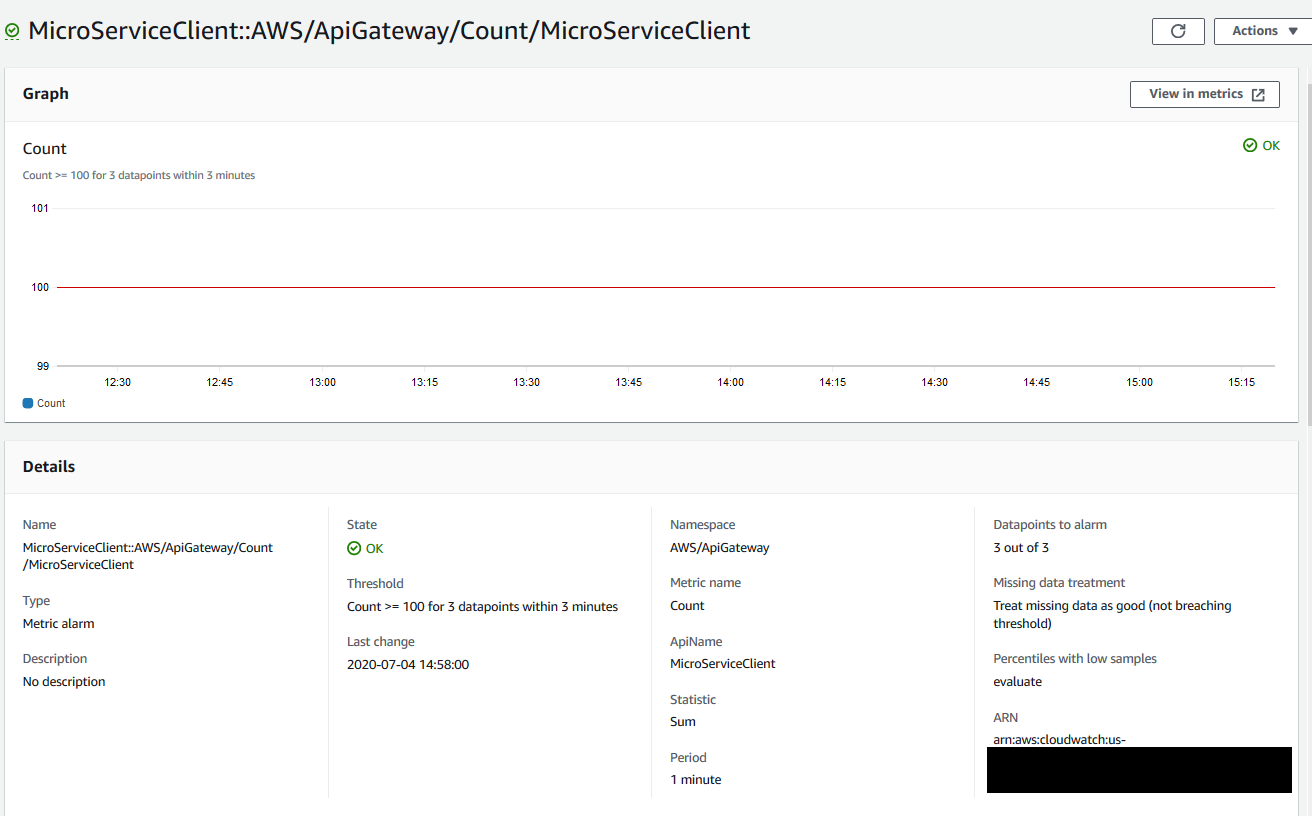
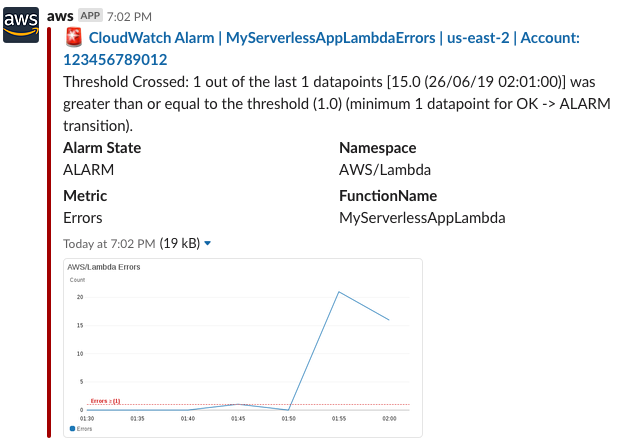
AWS CloudWatch Alarms
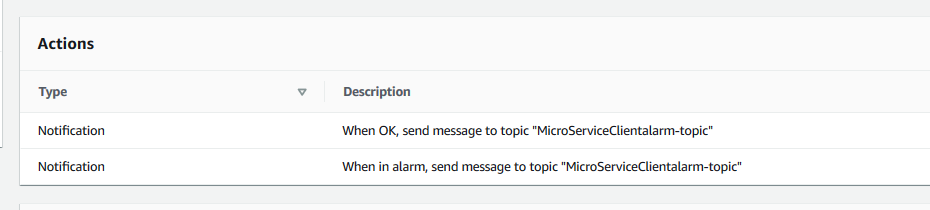
Alarms perform an action when certain conditions on Metrics are met. For example, CPU more than 50% for 3 minutes. Actions include emailing a person or sending the message to an SNS topic. This topic can then be subscribed to by other services. We subscribe to this topic with AWS Chatbot to deliver the notifications to a Slack channel.
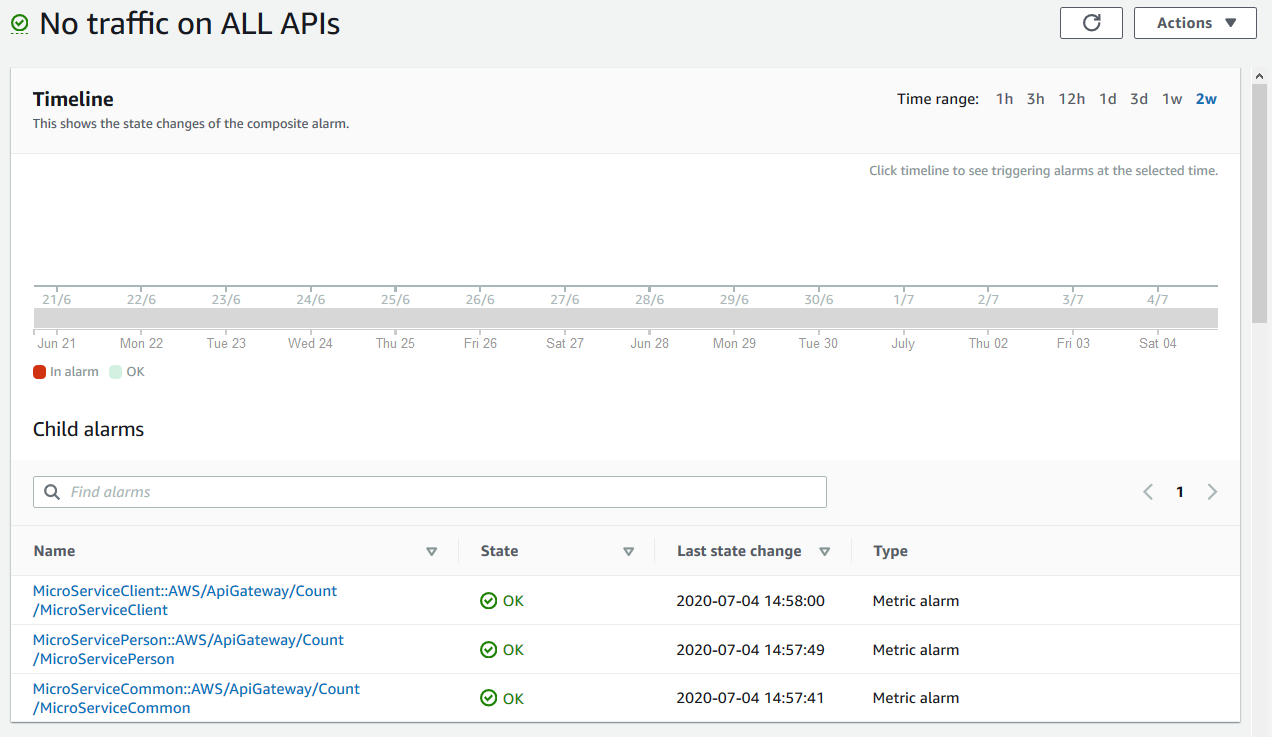
It is important to subscribe to both the ALERT and the OKAY actions. Otherwise you will never know if your system stabilized after an alert unless you log into the console and inspect the system.
Composite Alarms are great when you want to string together some sort of logic to give a higher order of alarm/event. For example, you can create an alarm if the database CPU is more than 50% and the API hit count is less than 1000 requests per minute. This will set off an event/alarm informing you that your database might be crunching away at a difficult query and that it might be a result of a person executing a heavy analytical query rather than your application.
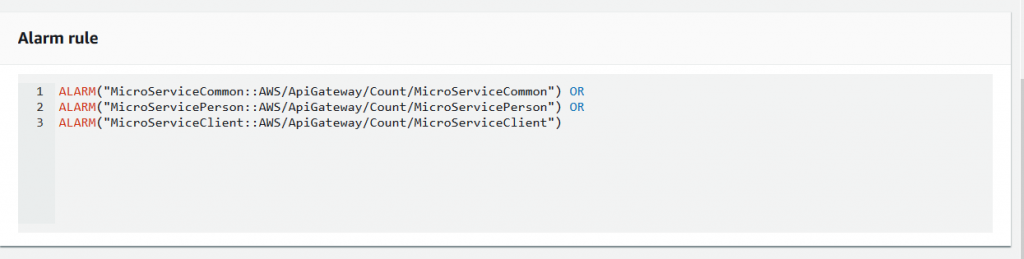
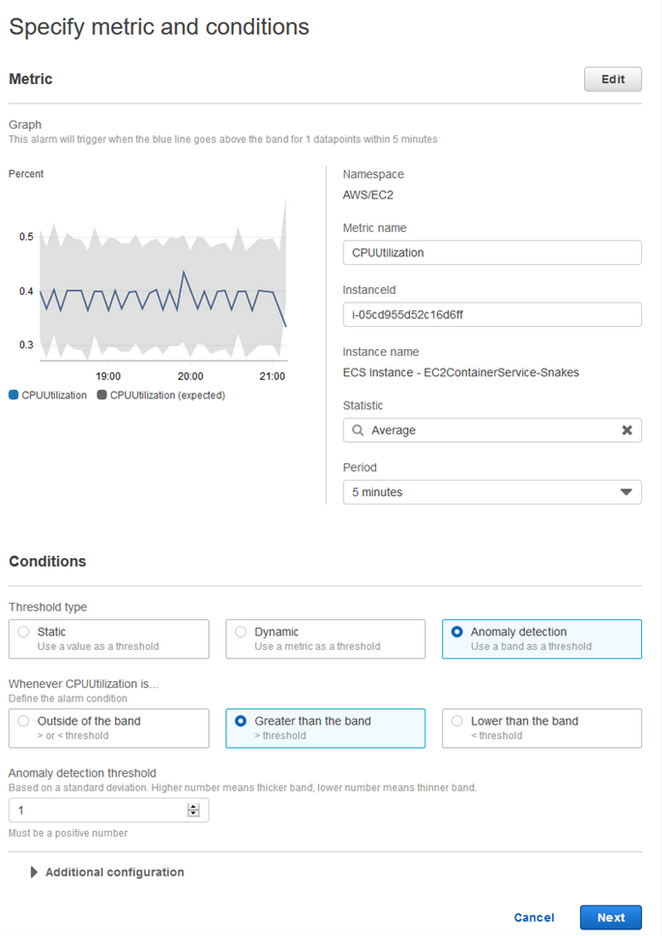
Anomaly detection uses machine learning (random cut forest) to train on up to two weeks of metric data. This creates upper and lower bands around your metric which are defined by standard deviations. Alerts can then be created whenever your metric is outside or within these bands. They are great at monitoring predictable periodic metrics, like API traffic.
AWS CloudWatch Metric filters
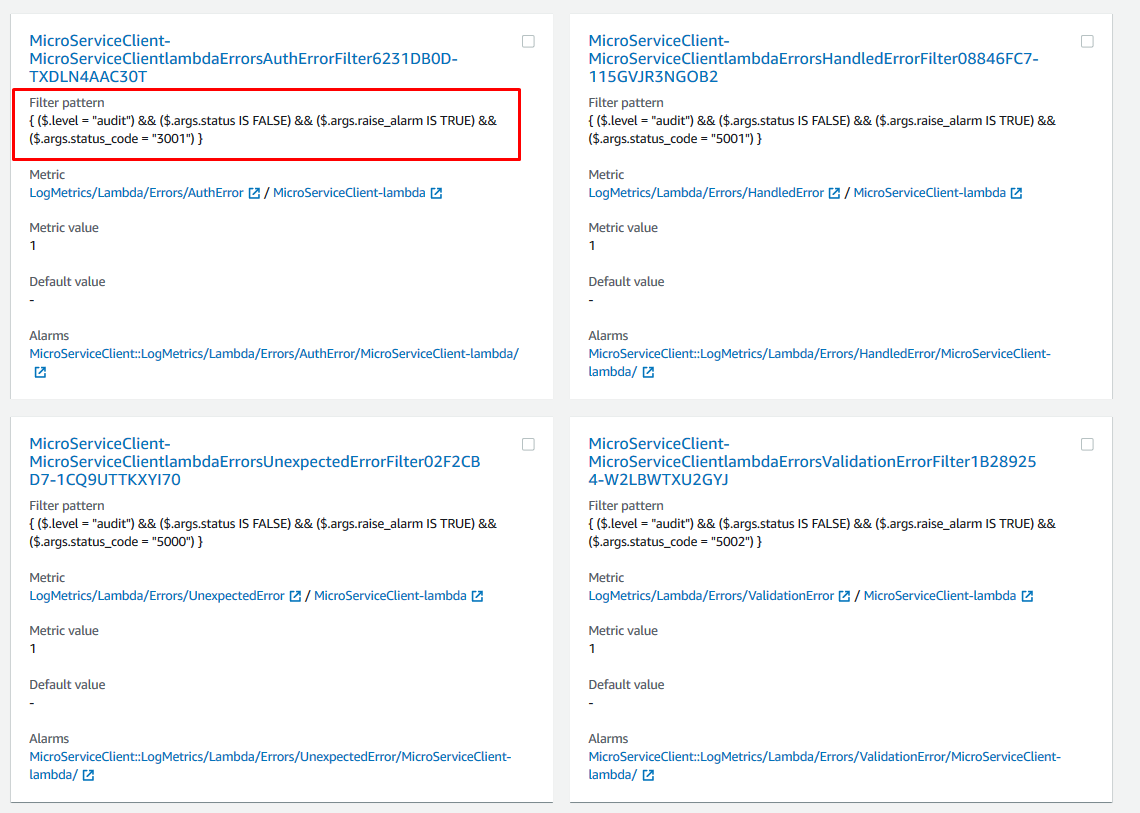
CloudWatch Metric filter will search the Logs for patterns and publish the search results as Metrics. For example, we can search for the word ‘retry’ in the logs and then publish it as a metric that we can view on a dashboard or create an alarm from.
This is how we count soft errors , which are errors that don’t crash the Lambda but return an undesired result to the caller. In our example, all the API Lambdas always return HTTP Status code 200. Within the body of the response is our request status code: 2000 – Success, 5000 – Unexpected, 5001 – Handled, 5002 – Validation, 3001 – Auth. Structured logging always writes the audit record in a specific format. We use this to create metrics and then alarms based on those metrics.
AWS CloudWatch Dashboards
Dashboards are great to get an overview of the operational status of your system. In the example services, each one also deploys their own dashboard to monitor basic metrics of the Lambda, API Gateway and DynamoDB table. Everything is defined as IaC using the AWS CDK.

A manual dashboard can also be created to combine all the services onto one dashboard. I usually tend to make it less granular by just displaying the overall status of each microservice and other useful information.
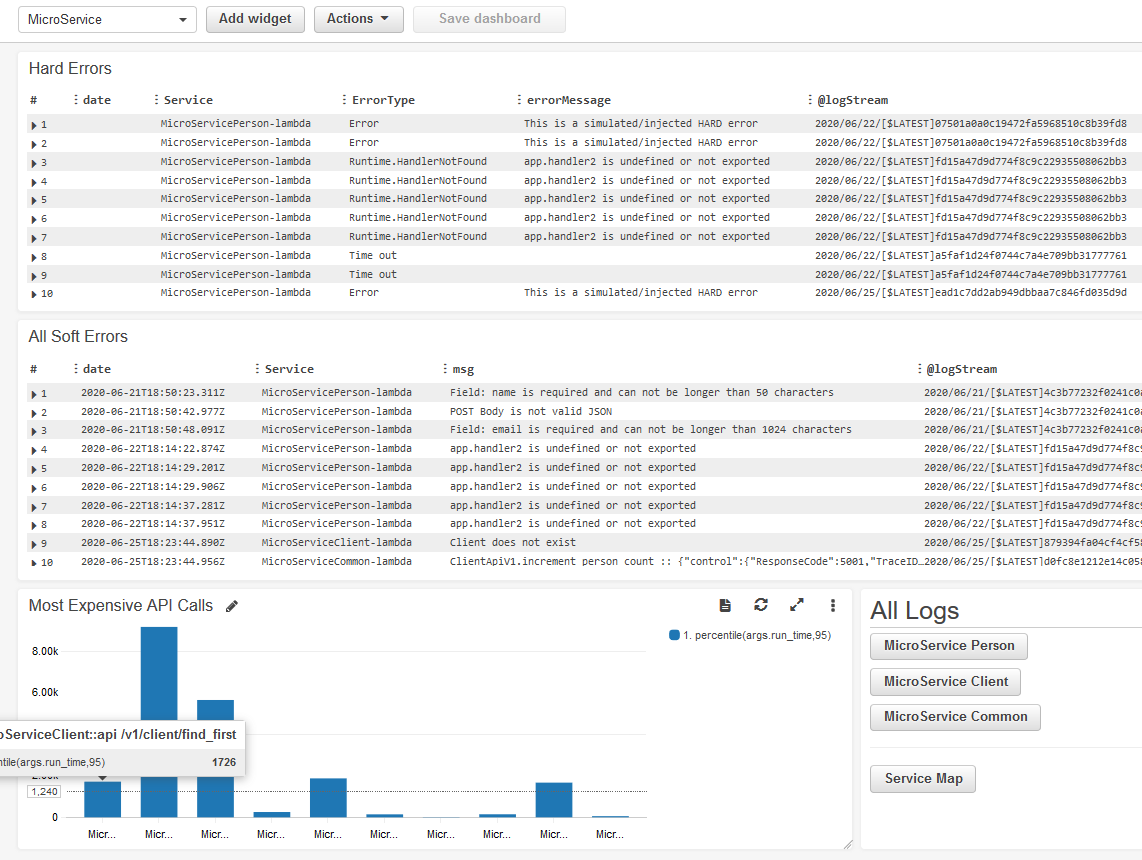
The dashboard above contains three CloudWatch Log Insight query widgets. We can even write basic markup to create links/buttons, as seen in the bottom right corner.
AWS CloudWatch Log Insights
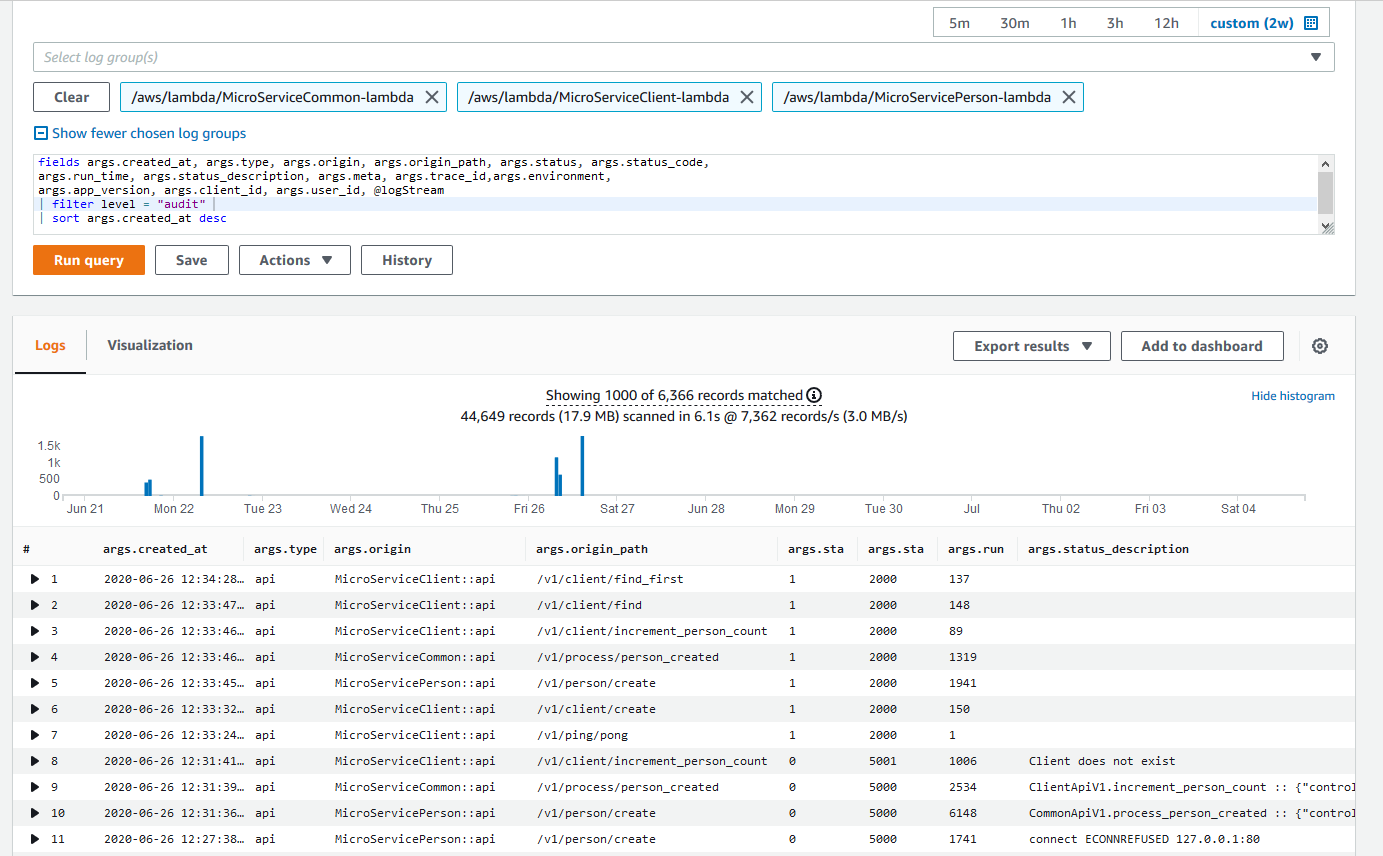
Log Insights enable us to do SQL-like querying over one or more Log Groups. This tool is extremely powerful to get insights out of your structured logs. It also has basic grouping functionality that can graph results. For example, we use a single query to query the audit records of all three microservices over the last 2 weeks (see below).
We can also compare the latencies of all the microservice API calls and visually graph it in a bar chart.
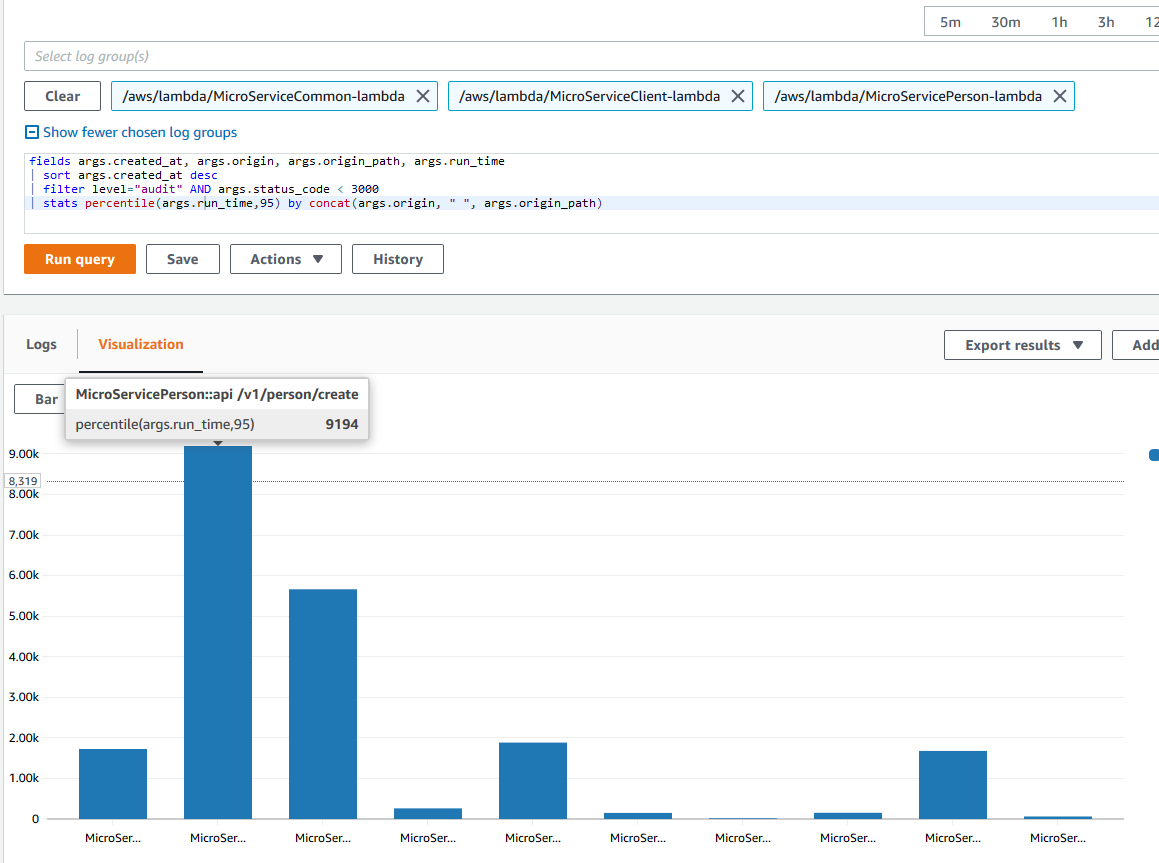
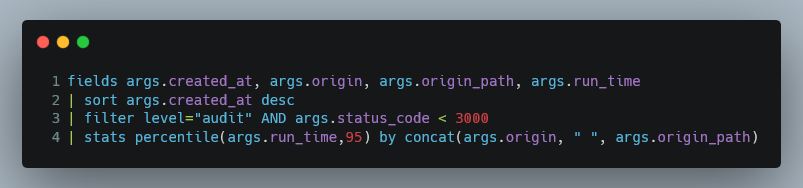
Lastly, I want to highlight the most impactful API calls. This is taking the amount of calls and multiplying it by the 95-percentile latency. This gives us a quick indication of which API calls, if optimized, will have the biggest impact on the client calling the API.

There are many more queries such as these that you can do to help identify if caching will work on a specific API endpoint and also which type, client or server side, will work best. Other queries are documented in the GitHub README file here: https://github.com/rehanvdm/MicroService. A quick summary of what we can find:
- All Audit Records
- All Audit Records for a specific TraceID
- All Audit Records for a specific User
- All Hard errors
- All Soft errors
- All log lines for TraceID
- Most expensive API calls
- Most impactful API calls
These queries would not be possible without structured logging. When APIs call each other, they also send the TraceID/CorrelationID downstream. This ID is then used in the logs by the service receiving the request. It enables us to query a single TraceID and find the complete execution path over all three services and their logs , saving a ton of time when you’re debugging.
AWS X-Ray
Distributed Tracing is not something new, but it is a must-have for any distributed and micro service application. X-Ray allows you to easily see interactions between services and identify problems at a glance. Segments are represented by circles with the colour indicating the status of that segment.
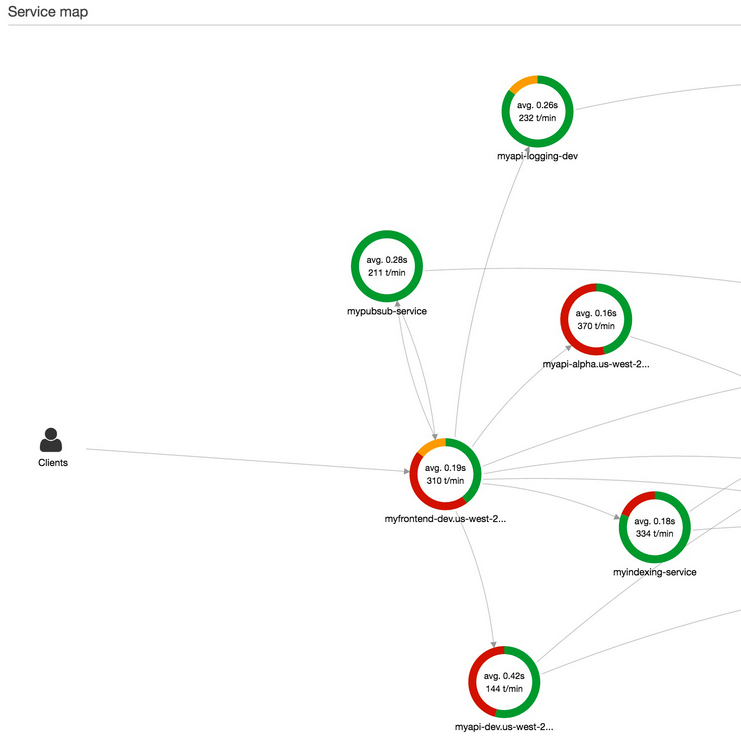
Each service that runs the X-Ray agent sends trace data to the X-Ray service. This agent is already installed on the container that runs the Lambda function and uses less than 3% of your memory or 16MB, whichever is greater. Tracing is made possible by passing a TraceID downstream to all the services it calls. Each service that has X-Ray enabled uses the received TraceID and continues to attach segments to the trace. The X-Ray service collects and orders all these traces. The traces can be viewed in the Service Map (image above) or as Traces (image below).
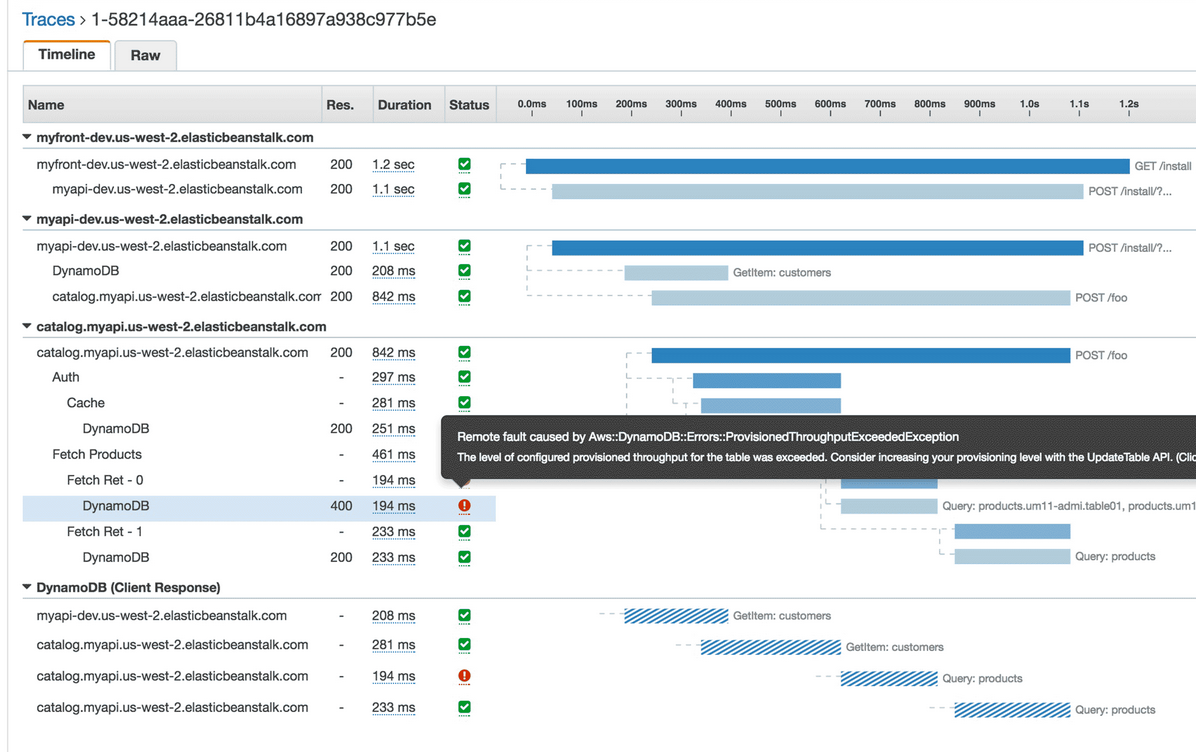
The X-Ray service isn’t perfect. For some services it requires manual wrapping and passing of the TraceID in order to get a fully traced execution. One of these services is SQS and it is documented here.
X-Ray also has sampling options to not trace every request. This is helpful if you have high throughput applications and tracing every request would just be too expensive. By default, the X-Ray SDK records the first request each second, and five percent of any additional requests. This sampling rate can be adjusted by creating rules on the console.
AWS Chatbot
AWS Chatbot is an interactive bot that makes it easy to monitor and interact with your AWS resources from within your Slack channels and Amazon Chime chatrooms.
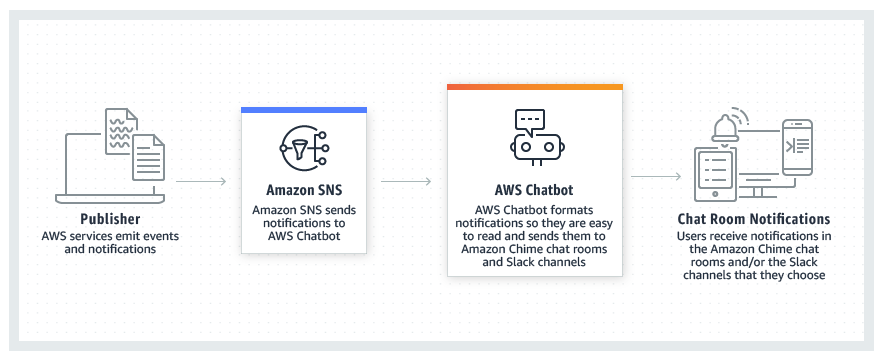
We only use it for sending alarms to a Slack channel because it is such an eyesore to look at the alarm emails. AWS Chatbot can do a lot more though; you can directly run a Lambda function or log a support ticket when interacting with the bot.
Quick word about the
As mentioned before, the API function is a Lambdalith. Just to summarize the reasoning behind this madness:
- By having 1 Lambda, I save $$ by setting provisioned capacity on 1 Lambda as opposed to setting it on each endpoint.
- Less downstream calls are made, like fetching secrets.
- Less cold starts occur.
A fewpoints about the overall structure:
- All API calls are proxied to a single Lambda function. Then the Lambda ‘routes’ to a certain file within its code base for that endpoint logic.
- The common directory has the data_schemas which are 1-to-1 mappings of how data is stored in DynamoDB. The v1 directory that handles the endpoints does all the business logic.
- There is an OpenAPI 3 doc to describe the API.
- There is structured logging done by a basic helper class that wraps the console.log function.
- Consistent error handling is forced.
- There is one audit record for every execution.
Part 2 – coming soon
Asmentioned above, Part 2 will fix the coupling between the micro services. Wewill look at:
- Creating BASE ( B asic A vailability, S oft state, E ventual Consistency) consistency over the whole system.
- Decoupling the service with Event Bridge.
- Adding a Queue between the Common and Client API to increment the counter.
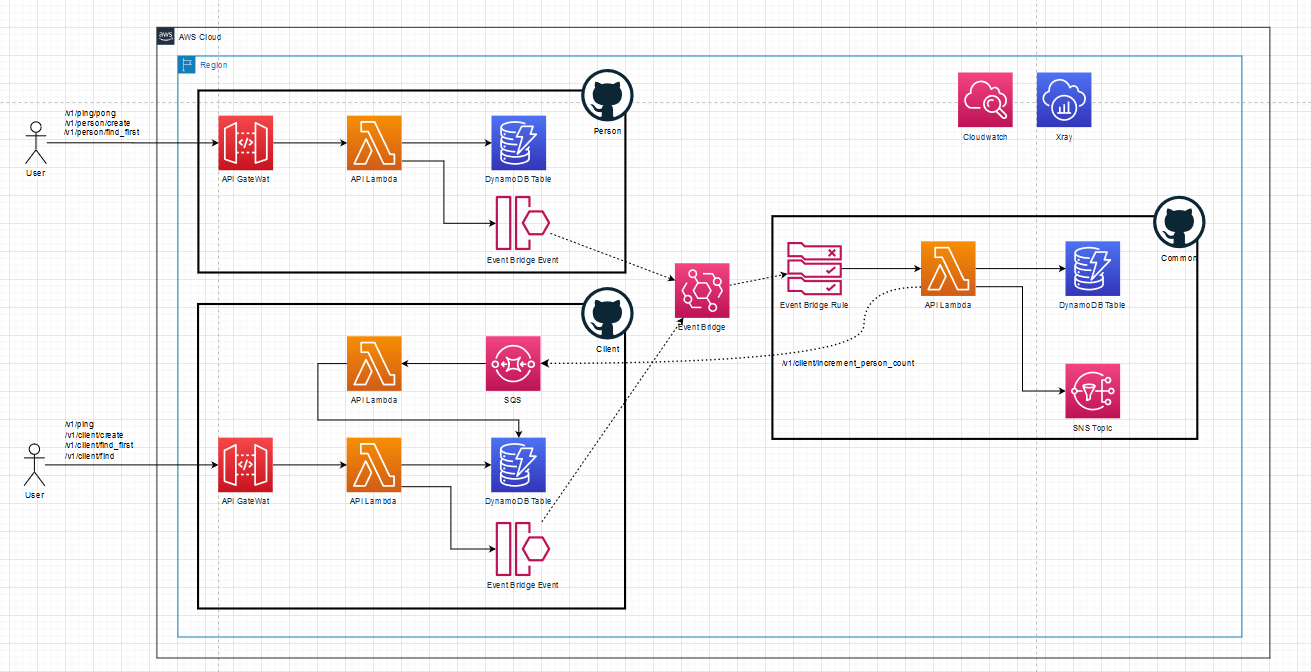
Basically,the common service will be listening to the client and person create events.When a client is created, the common service stores a local copy of that clientin its own database so that it does not have to do the lookup on an externalservice but can rather go to its own service data. The write from the commonservice to the client to increment the person count can also be decoupled usinga queue.
This changes our distributed monolith to microservice-based architecture, it looks something like this:
Conclusion (TL;DR)
In this post, we focus on the strengths and capabilities of using AWS Native service to monitor distributed applications. In this first instalment of the series, we create a distributed monolith consisting of three services using the AWS CDK. The code can be found here: https://github.com/rehanvdm/MicroService. The second part will focus on refactoring the monolith to a decoupled microservice.
This post has been edited by Nuance Editing & Writing. Check them out for all your editing and writing needs.





Top comments (5)
These are valid points. But I think people pay third-party monitoring for convenience and productivity more than need.
In reality, most dev teams don't have time (or prefer not to spend time) configuring all monitoring rules & metrics. For most apps, what needs to be monitored doesn't really change much.
A big issue with CloudWatch Logs is debugging. It's a pain. Especially if you have a high-throughput and high-concurrency Lambda. Logs are scattered across various streams, which are linked to each Lambda microVM lifecycle (start/end independently). Inside each Stream, it's visually hard to spot where an invocation starts and ends. X-Ray traces and CW Logs aren't visually integrated as well. The lack of a good developer experience is what drives people to pay for a well-crafted UI and more integrated (data-wise) environment.
Apologies for the late reply. All true, there is a target market for both native and third party monitoring. I get what you are saying about CW Logs, I have been using it for years now and have probably grown accustomed to it. I do see new developers in the space struggle for a while before also accepting how CW Logs work.
CW Log Insights on the other hand provides a lot of functionality and helpful queries, some that aren't available in third party monitoring last I checked.
CW Logs Insights has lots of functional limitations (ie. what it CAN do, not considering DX issues like the query syntax being too verbose for searching string fragments) and is not sufficient for a lot of people's needs, e.g.
The same goes to all the other services, in general, they're good enough when you're starting out but most people grow out of them and need something more capable. X-Ray for example, has poor support for async event sources (only SNS is supported right now), so if you have an event-driven architecture it's of very limited use.
These limits are indeed a pain. It would be relatively simple to deploy a Lambda with logic to overcome the Log Group and Region limitations. But then the team would start deviating from the core business. In most enterprise projects it will make more sense to pay someone that can do it well.
AWS is focused on providing infrastructure. CW handles the infra really well for collecting and storing logs. Swifting through and analyzing them is another business, from my point of view...
Insights is indeed very powerful, it was a great feature added by the CW Logs team.