Read Time: 2 mins
Intro
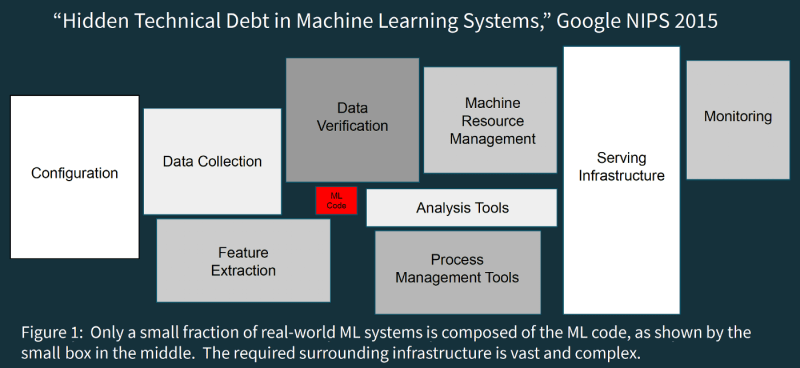
One of the constant theme that was observed in last couple of months whilst reviewing design and conversation with peers was with tech debt. So last weekend spend sometime going through some literature on machine learning tech debt. I have do my best to provide key themes of how the debt builds up with machine learning project and would recommend the read through the links provided
Key Concept highlighted

Data Drift
ML Models are built on quality labelled data. Over time the dynamics around which the model was initially built might change. Having a view on the data Drift in production environment is necessary to understand when to consider retraining the model built. Lack of robust framework to automate data capture and data control could result in Data Poisoning. This could degrade the model over time
Code Quality
With easy of access to abundance of Open source libraries and algorithms for ML enthusiastic, building a ML model with small amount of data in a notebook is picnic. ML code quality is no different to traditional programming code quality challenges. Some examples might be dead code, Lack of automated pipeline, maintainable code (e.g., documenting code, avoiding code clones, using abstraction) are generally compromised. What this does is increase effort if debugging / enhancement are needed. A dead code might not been triggered with older dataset and we might have missed until the model breaks
Complexity
Lack of feature engineering might and design thinking might end up building complex models which are intertwined. This would result in high risk of the system to provide a desired recommendation and increase the complexity with regards to observability.
Feedback Loops
Couple of giant Automobile manufacturing entities were creating headline due to their failed experiment of autonomous vehicle on the road. The safety of the environment entities in which model should work was never factored and it increased the risk towards the safety of the model. Careful requirements analysis can help to detect potential feedback loops and design interventions as part of the system design, before they become harmful; skipping such analysis may lead to feedback loops manifesting in production that cause damage and are harder to fix later
Operational Debt:
Observability for a model is cliché that should be factored early in design. Enabling an infrastructure to have a control panel view would need significant effort. Forgoing to build a robust monitoring infrastructure can cause high costs later when it is not noticed how the model quality degrades or how it serves certain populations poorly. If something goes wrong in production then reproducibility is another challenge which the team might face due to lack of operational design in the project. It makes makes code refactoring a bit hard.
Conclusion
Finding the right balance between speed and scalability is critical if we need to land Machine learning projects to end customers. ML engineers / Data science enthusiastic should look beyond jus notebooks but also think about version control, feature stores, model registries etc..
Further Reads
1) https://services.google.com/fh/files/misc/practitioners_guide_to_mlops_whitepaper.pdf
2) https://papers.nips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
3) https://dev.to/balagmadhu/software-credit-crunch-technical-debt-2a9g
4) https://becominghuman.ai/no-you-dont-need-mlops-5e1ce9fdaa4b




Top comments (0)