
Introduction 👋
In the previous blog post of this series, I introduced the concept of the serverless mindset, and how adopting serverless could best suit you and your company's needs. In this blog post, I'm going to dive a little deeper into AWS Lambda, which is at the core of AWS Serverless.
What is AWS Lambda?
AWS Lambda is a compute service. You can use it to run code without provisioning or managing servers. Lambda runs your code on a high-availability compute infrastructure. It operates and maintains all of the compute resources, including server and operating system maintenance, capacity provisioning and automatic scaling, code monitoring, and logging. With Lambda, you can run code for almost any type of application or backend service.
Some benefits of using Lambda include the following:
- You can run code without provisioning or maintaining servers.
- It initiates functions for you in response to events.
- It scales automatically.
- It provides built-in code monitoring and logging via Amazon CloudWatch.
AWS Lambda Features
The following the six main features of AWS Lambda:
- You can write the code for Lambda using languages you already know and are comfortable using. Development in Lambda is not tightly coupled to AWS, so you can easily port code in and out of AWS.
- Within your Lambda function, you can do anything traditional applications can do, including calling an AWS SDK or invoking a third-party API, whether on AWS, in your datacenter, or on the internet.
- Instead of scaling by adding servers, Lambda scales in response to events. You configure memory settings and AWS handles details such as CPU, network, and I/O throughput.
- The lambda permission model uses AWS IAM (Identity & Access Management to securely grant access to the desired resources and provide fine-grained control to invoke your functions.
- Because Lambda is a fully managed service, high availability and fault tolerance are built into the service without needing to perform any additional configuration.
- Lambda functions only run when you initiate them. You pay only for the compute time that you consume. When the code is invoked, you are billed in 1-millisecond (ms) increments.
What is a Lambda Function?
The code you run on AWS Lambda is called a Lambda function. Think of a function as a small, self-contained application. After you create your Lambda function, it is ready to run as soon as it is initiated. Each function includes your code as well as some associated configuration information, including the function name and resource requirements. Lambda functions are stateless, with no affinity to the underlying infrastructure. Lambda can rapidly launch as many copies of the function as needed to scale to the rate of incoming events.
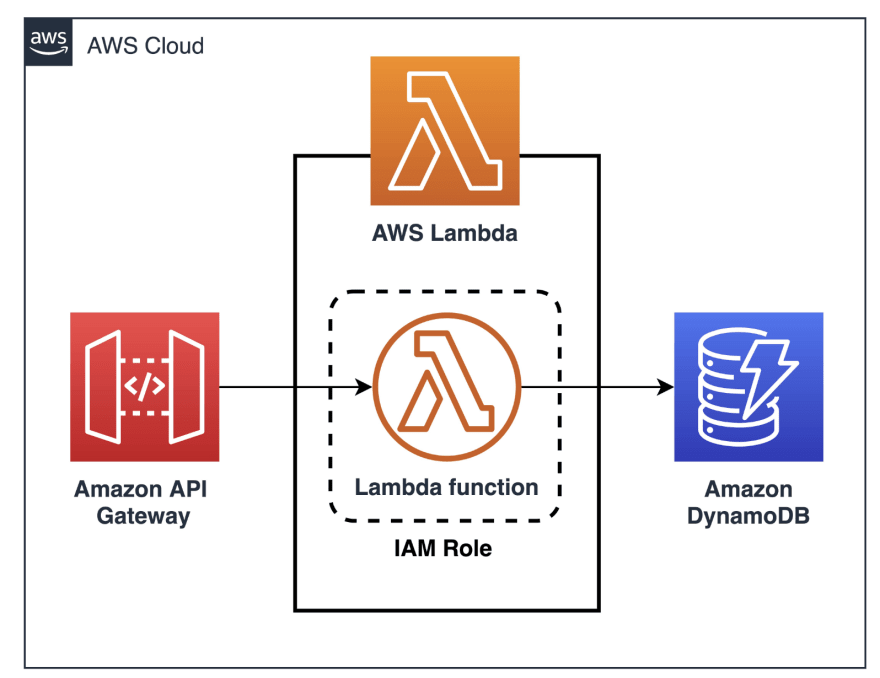
After you upload your code to AWS Lambda, you can configure an event source, such as an Amazon Simple Storage Service (Amazon S3) event, Amazon DynamoDB stream, Amazon Kinesis stream, or Amazon Simple Notification Service (Amazon SNS) notification. When the resource changes and an event is initiated, Lambda will run your function and manage the compute resources as needed to keep up with incoming requests.
How AWS Lambda Works
To understand event driven architectures like AWS Lambda, you need to understand the events themselves. This section dives in to how events initiate functions to invoke the code within.
Invocation models for running Lambda functions
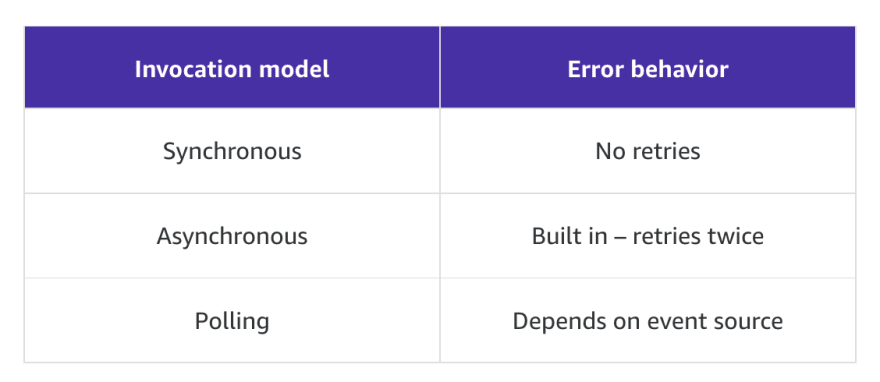
Event sources can invoke a Lambda function in three general patterns. These patterns are called invocation models. Each invocation model is unique and addresses a different application and developer needs. The invocation model you use for your Lambda function often depends on the event source you are using. It's important to understand how each invocation model initializes functions and handles errors and retries.
There are three different invocation models for AWS lambda functions:
- Synchronous invocation
- Asynchronous invocation
- Polling invocation
Synchronous invocation
When you invoke a function synchronously, Lambda runs the function and waits for a response. When the function completes, Lambda returns the response from the function's code with additional data, such as the version of the function that was invoked. Synchronous events expect an immediate response from the function invocation.
With this model, there are no built-in retries. You must manage your retry strategy within your application code.
The following diagram shows clients invoking a Lambda function synchronously. Lambda sends the events directly to the function and sends the function response directly back to the invoker.
Asynchronous invocation
When you invoke a function asynchronously, events are queued and the requestor doesn't wait for the function to complete. This model is appropriate when the client doesn't need an immediate response.
With the asynchronous model, you can make use of destinations. Use destinations to send records of asynchronous invocations to other services. (Select the Destinations tab for more information.)
The following diagram shows clients invoking a Lambda function asynchronously. Lambda queues events before sending them to the function.
Polling invocation
This invocation model is designed to integrate with AWS streaming and queuing based services with no code or server management. Lambda will poll (or watch) these services, retrieve any matching events, and invoke your functions. This invocation model supports the following services:
- Amazon Kinesis
- Amazon SQS
- Amazon DynamoDB Streams With this type of integration, AWS will manage the poller on your behalf and perform synchronous invocations of your function.
With this model, the retry behavior varies depending on the event source and its configuration.
Invocation model error behavior
When deciding how to build your functions, consider how each invocation method handles errors. The following chart provides a quick outline of the error handling behaviour of each invocation model.
Performance optimisation
Serverless applications can be extremely performant, thanks to the ease of parallelisation and concurrency. While the Lambda service manages scaling automatically, you can optimise the individual Lambda functions used in your application to reduce latency and increase throughput.
Cold and warm starts
A cold start occurs when a new execution environment is required to run a Lambda function. When the Lambda service receives a request to run a function, the service first prepares an execution environment. During this step, the service downloads the code for the function, then creates the execution environment with the specified memory, runtime, and configuration. Once complete, Lambda runs any initialisation code outside of the event handler before finally running the handler code.
In a warm start, the Lambda service retains the environment instead of destroying it immediately. This allows the function to run again within the same execution environment. This saves time by not needing to initialise the environment.
Reducing cold starts with Provisioned Concurrency
If you need predictable function start times for your workload, Provisioned Concurrency is the recommended solution to ensure the lowest possible latency. This feature keeps your functions initialsed and warm, ready to respond in double-digit milliseconds at the scale you provision. Unlike on-demand Lambda functions, this means that all setup activities happen ahead of invocation, including running the initialisation code.
Conclusion 💡
In this post we covered a lot of content on what AWS Lambda is, how it can be used, and some best practices when doing so.
Although there is a whole lot more to serverless than just lambda functions, it really is at the core of AWS Serverless and an understanding of how you can utilise lambdas in your architecture design is crucial to your adoption of the serverless-first mindset.
In further blog posts in this series, I will dive into some other AWS services that you can use in your serverless journey, as well as showing you just how easy it is to get set up and start building lambda functions for yourself!




Top comments (0)