
Introduction 👋
In chapter one of the AWS Serverless Learning Path, you will be introduced to the key concepts of the AWS Serverless Platform, as well as discussing a little bit about the differences between traditional infrastructure designs and serverless architectures.
The Familiar Architecture 👴🏻
Let us take a look at a very simple web service that most devs would be familiar with:
- a simple client
- an EC2 Instance to host the service
- a database to persist data
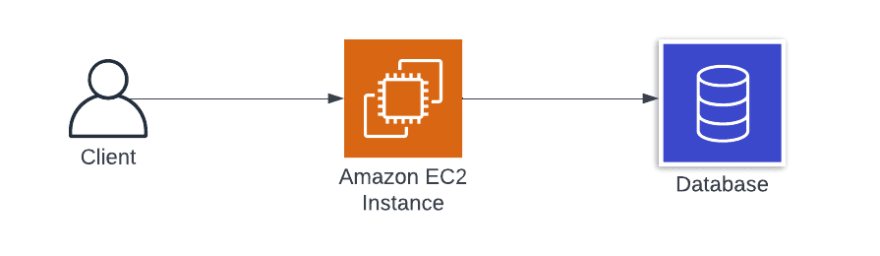
In a scenario where your service starts gaining traction, and you need to scale up to handle the traffic you are receiving, you would need to do something like the following:
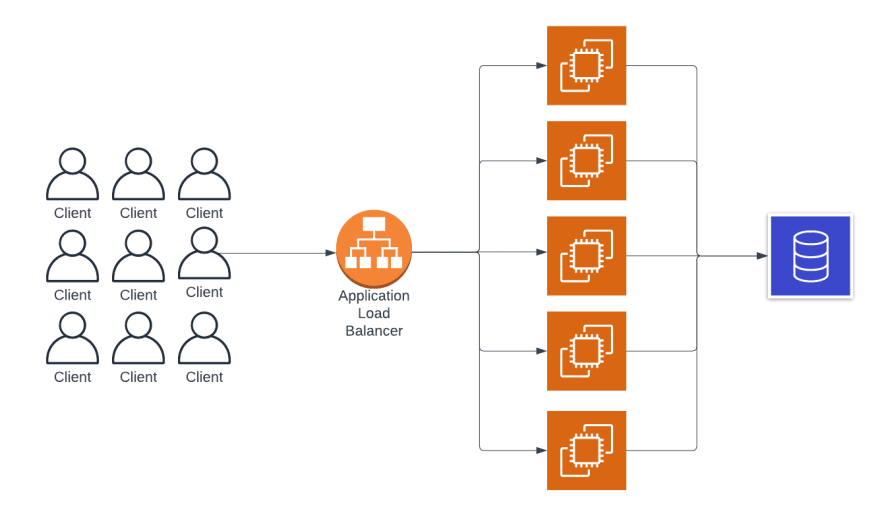
To handle the load in this traditional architecture, you would need to horizontally scale your EC2 instances to handle requests and use a load balancer to divert traffic.
This option will work fine, although you now have an issue with cost management. You might get more traffic midday during the week than you do in the middle of the night on a weekend for instance, and with the current architecture you have to provision for your peak load and continue to pay for those servers even when they are idle.
But in a cloud environment, this problem is easy enough to solve. You can simply add an Auto Scaling group to automatically provision and terminate instances based on your application’s traffic patterns.
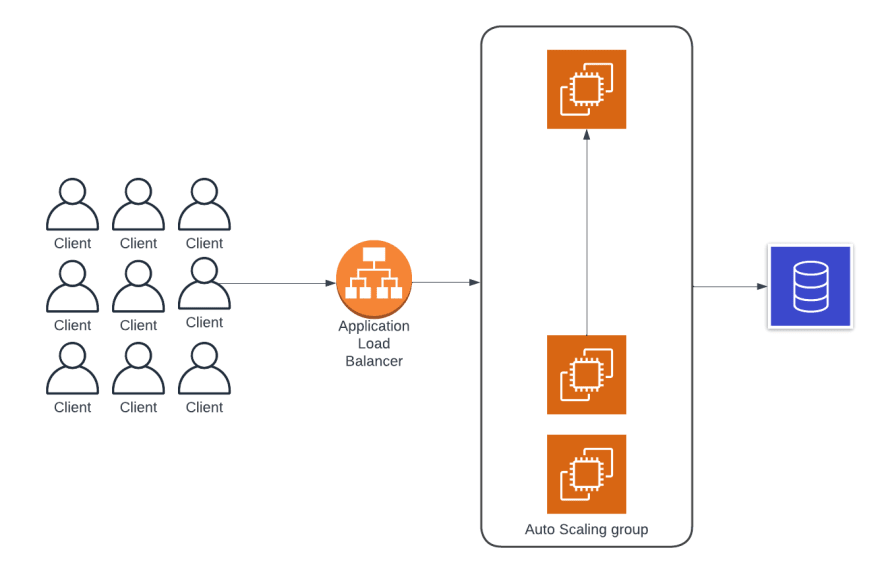
So now you can handle all the traffic when your service is under heavy load, but minimize your costs when it’s not getting as much traffic. Now, in addition to elastically scaling your app, you probably also want to ensure it’s highly available and fault tolerant.
You want to make sure that you’re spreading your instances across multiple availability zones in order to ensure that, even if there's a failure of a single data center, your users will still be able to access your service. This is also easy to implement. You just make sure the load balancer and auto scaling group are configured to spread your instances across availability zones.
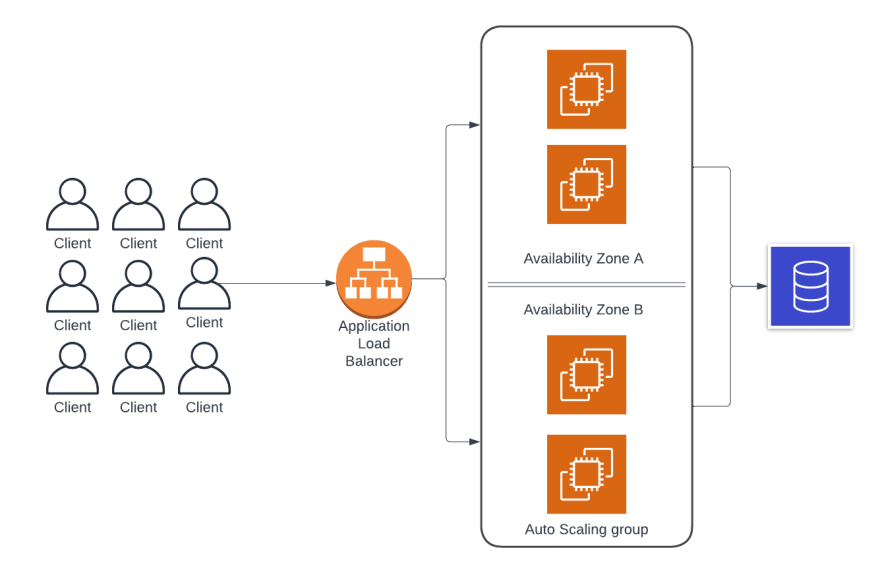
So now you’ve got a highly available architecture that elastically scales to handle your peak traffic load while still saving costs during off-peak hours. This is a very, very common architecture that's been successfully deployed thousands of times by many different companies.
However, there are multiple things that you as an application architect or developer need to be concerned with when you build and operate a system like this.
Introducing the Serverless Architecture 🙌🏽
If you take a look at the list below, I have outlined some of the concerns that a developer would have to consider when building out the architecture in the previous section:

What’s interesting about this list on the right is that the best practices for how to handle these are very, very similar across companies. There's very little that’s business specific about how you would approach most of these issues.
And this is exactly the kind of undifferentiated lifting that can be offloaded to AWS allowing you to focus more on the things that are unique to your particular business.
This is really the driving force behind the AWS serverless platform.
Lets take a look at how you could rearchitect this service using the serverless mindset. Looking at the image below it can be broken down into three simple phases
- a client invocation
- some form of business logic being applied to that request
- a data store to persist information from the request
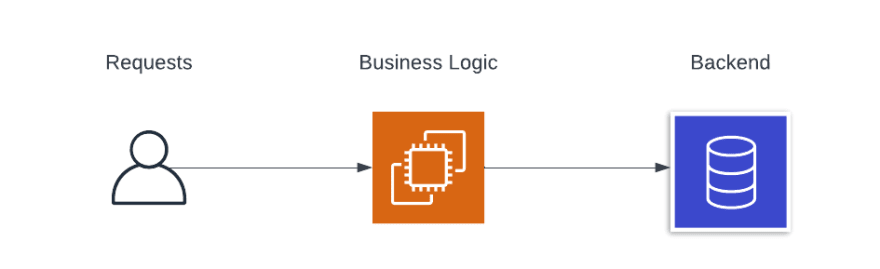
To look at this through a serverless lens, it could look something like this:
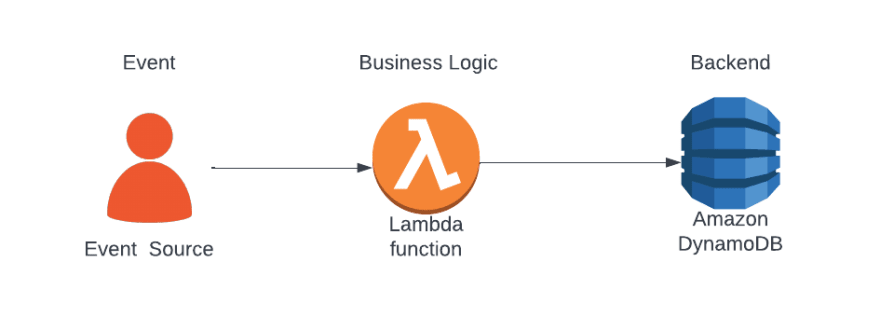
- the the source of the event (in our case, a HTTP request from a client)
- a lambda function which we will use to execute our business logic
- a dynamodb which we will use to persist request data (this could also be replaced with a call to another API or service)
In this architecture, all of the concerns around cost, scalability, and availability are offloaded to AWS through the use of their serverless services. We as developers can focus on what matters, the application code and core business logic. Both the lambda and dynamodb will automatically scale to handle load during peak hours, as well as being fault tolerant across availability zone (spread across different AWS data centres that are separately geographical). As well as this, lambda uses a pay-per-execution pricing model which means we do not pay for idle-server time during off-peak hours.
This is just one of many examples of where we can use AWS Serverless services to offload undifferentiated heavy lifting to AWS, some of which I will discuss as part of further bog posts in this series.
Conclusion 💡
In this post we briefly introduced some of the core concepts of serverless, and why it might be beneficial to consider rearchitecting your systems to make use of its many advantages. Some of these include:
- No need to provision or manage servers
- Automatic scaling
- Pay-per-execution pricing model
- Reduced operational costs
- High availability and fault tolerance
- Easy integration with other AWS services
- Shortened development and deployment cycles
- Improved security
- Increased developer productivity
- Flexibility in building and deploying applications
Although I have only discussed a couple of these benefits in this post, I plan to dive deeper into why Serverless-First is the way forward in 2023, stay tuned!




Top comments (0)