
What will be scraped
Prerequisites
Basic knowledge scraping with CSS selectors
CSS selectors declare which part of the markup a style applies to thus allowing to extract of data from matching tags and attributes.
If you haven't scraped with CSS selectors, there's a dedicated blog post of mine about how to use CSS selectors when web-scraping that covers what it is, pros and cons, and why they're matter from a web-scraping perspective and show the most common approaches of using CSS selectors when web scraping.
Separate virtual environment
In short, it's a thing that creates an independent set of installed libraries including different Python versions that can coexist with each other in the same system thus preventing libraries or Python version conflicts.
If you didn't work with a virtual environment before, have a look at the dedicated Python virtual environments tutorial using Virtualenv and Poetry blog post of mine to get familiar.
📌Note: this is not a strict requirement for this blog post.
Install libraries:
pip install parsel playwright
Reduce the chance of being blocked
There's a chance that a request might be blocked. Have a look at how to reduce the chance of being blocked while web-scraping, there are eleven methods to bypass blocks from most websites.
Full Code
from parsel import Selector
from playwright.sync_api import sync_playwright
import re, json, time
def scrape_institution_members(institution: str):
with sync_playwright() as p:
institution_memebers = []
page_num = 1
members_is_present = True
while members_is_present:
browser = p.chromium.launch(headless=True, slow_mo=50)
page = browser.new_page()
page.goto(f"https://www.researchgate.net/institution/{institution}/members/{page_num}")
selector = Selector(text=page.content())
print(f"page number: {page_num}")
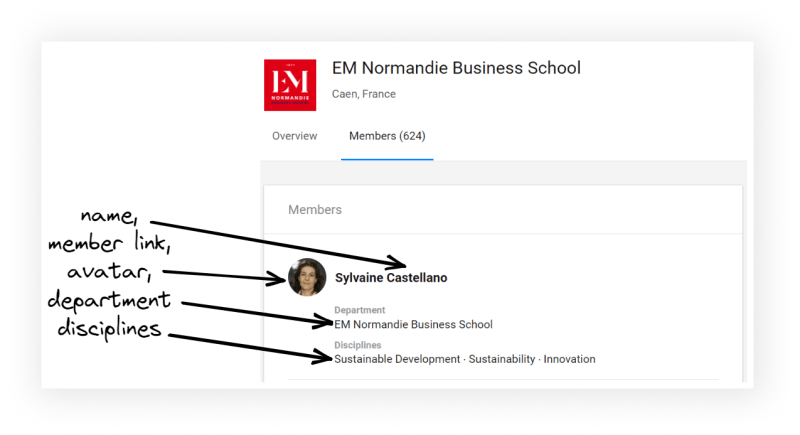
for member in selector.css(".nova-legacy-v-person-list-item"):
name = member.css(".nova-legacy-v-person-list-item__align-content a::text").get()
link = f'https://www.researchgate.net{member.css(".nova-legacy-v-person-list-item__align-content a::attr(href)").get()}'
profile_photo = member.css(".nova-legacy-l-flex__item img::attr(src)").get()
department = member.css(".nova-legacy-v-person-list-item__stack-item:nth-child(2) span::text").get()
desciplines = member.css("span .nova-legacy-e-link::text").getall()
institution_memebers.append({
"name": name,
"link": link,
"profile_photo": profile_photo,
"department": department,
"descipline": desciplines
})
# check for Page not found selector
if selector.css(".headline::text").get():
members_is_present = False
else:
time.sleep(2) # use proxies and captcha solver instead of this
page_num += 1 # increment a one. Pagination
print(json.dumps(institution_memebers, indent=2, ensure_ascii=False))
print(len(institution_memebers)) # 624 from a EM-Normandie-Business-School
browser.close()
"""
you can also render the page and extract data from the inline JSON string,
however, it's messy and from my perspective, it is easier to scrape the page directly.
"""
# https://regex101.com/r/8qjfnH/1
# extracted_data = re.findall(r"\s+RGCommons\.react\.mountWidgetTree\(({\"data\":{\"menu\".*:true})\);;",
# str(page.content()))[0]
# json_data = json.loads(extracted_data)
# print(json_data)
scrape_institution_members(institution="EM-Normandie-Business-School")
Code explanation
Import libraries:
from parsel import Selector
from playwright.sync_api import sync_playwright
import re, json, time
| Code | Explanation |
|---|---|
parsel |
to parse HTML/XML documents. Supports XPath. |
playwright |
to render the page with a browser instance. |
re |
to match parts of the data with regular expression. |
json |
to convert Python dictionary to JSON string. |
time |
is not a practical way to bypass request blocks. Use proxies/captcha solver instead. |
Define a function:
def scrape_institution_members(institution: str):
# ...
| Code | Explanation |
|---|---|
institution: str |
to tell Python that institution should be an str. |
Open a playwright with a context manager:
with sync_playwright() as p:
# ...
Lunch a browser instance, open and goto the page and pass response to HTML/XML parser:
browser = p.chromium.launch(headless=True, slow_mo=50)
page = browser.new_page()
page.goto(f"https://www.researchgate.net/institution/{institution}/members/{page_num}")
selector = Selector(text=page.content())
| Code | Explanation |
|---|---|
p.chromium.launch() |
to launch Chromium browser instance. |
headless |
to explicitly tell playwright to run in headless mode even though it's a defaut value. |
slow_mo |
to tell playwright to slow down execution. |
browser.new_page() |
to open new page. |
Add a temporary list, set up a page number, while loop, and check for an exception to exit the loop:
institution_memebers = []
page_num = 1
members_is_present = True
while members_is_present:
# extraction code
# check for Page not found selector
if selector.css(".headline::text").get():
members_is_present = False
else:
time.sleep(2) # use proxies and captcha solver instead of this
page_num += 1 # increment a one. Pagination
Iterate over member results on each page, extract the data and append to a temporary list:
for member in selector.css(".nova-legacy-v-person-list-item"):
name = member.css(".nova-legacy-v-person-list-item__align-content a::text").get()
link = f'https://www.researchgate.net{member.css(".nova-legacy-v-person-list-item__align-content a::attr(href)").get()}'
profile_photo = member.css(".nova-legacy-l-flex__item img::attr(src)").get()
department = member.css(".nova-legacy-v-person-list-item__stack-item:nth-child(2) span::text").get()
desciplines = member.css("span .nova-legacy-e-link::text").getall()
institution_memebers.append({
"name": name,
"link": link,
"profile_photo": profile_photo,
"department": department,
"descipline": desciplines
})
| Code | Explanation |
|---|---|
css() |
to parse data from the passed CSS selector(s). Every CSS query traslates to XPath using csselect package under the hood. |
::text/::attr(attribute)
|
to extract textual or attribute data from the node. |
get()/getall()
|
to get actual data from a matched node, or to get a list of matched data from nodes. |
Print extracted data, length of extracted members, and close browser instance:
print(json.dumps(institution_memebers, indent=2, ensure_ascii=False))
print(len(institution_memebers)) # 624 from a EM-Normandie-Business-School
browser.close()
Part of the JSON output (fist result is a first member, last is the latest member):
[
{
"name": "Sylvaine Castellano",
"link": "https://www.researchgate.netprofile/Sylvaine-Castellano",
"profile_photo": "https://i1.rgstatic.net/ii/profile.image/341867548954625-1458518983237_Q64/Sylvaine-Castellano.jpg",
"department": "EM Normandie Business School",
"descipline": [
"Sustainable Development",
"Sustainability",
"Innovation"
]
}, ... other results
{
"name": "Constance Biron",
"link": "https://www.researchgate.netprofile/Constance-Biron-3",
"profile_photo": "https://c5.rgstatic.net/m/4671872220764/images/template/default/profile/profile_default_m.jpg",
"department": "Marketing",
"descipline": []
}
]
Extracting data from the JSON string
You can scrape the data without using parsel by printing page content() data which will get the full HTML contents of the page, including the doctype, and parsing the data using regular expression.
I'm showing this option as well, just in case some of you prefer this approach over directly parsing the page.
# https://regex101.com/r/8qjfnH/1
extracted_data = re.findall(r"\s+RGCommons\.react\.mountWidgetTree\(({\"data\":{\"menu\".*:true})\);;",
str(page.content()))[0]
json_data = json.loads(extracted_data)
print(json_data)
Outputs:

Here's the thing, extracting data seems to be practically more convincing from the JSON string but let's look at the example of accessing the fullName key:
👇👇👇👇👇
initState.rigel.store.account(id:\\\"AC:2176142\\\").fullName
This way, we also got two additional steps: find and compare user ID to make sure that ID would match the user ID.
Links
Add a Feature Request💫 or a Bug🐞
🌼





Top comments (11)
Dmi, the code does not work? it says "Error: It looks like you are using Playwright Sync API inside the asyncio loop. Please use the Async API instead." Alsi, it would be extremely helful to extract data from each profile (Research Interest, Citations, and h-index).
Hi, @datum_geek :) The code works, most likely you got a captcha on your end. The provided code should be used in addition to proxies or at least a captcha solving service.
After
Xnumber of requests, ResearchGate throws a captcha that needs to be solved.Try to change
user-agentto yours. Check what's youruser-agentand replace it.Also, I'm not sure about the error as the code import
sync_apiand context manager also:GIF that shows the output. 624 results in total:

The follow up blog post will be about scraping whole profile page 💫
Yes, indeed. Notice that the code does not work in jupyter notebook/lab environmlent, but can write in vs code.
I don't work with notebooks too often :) Don't know such nuances that can make it work other than using async playwright API instead.
A possible workaround is to run the script in terminal, where data will be saved to the file and then load data inside the notebook.
Not very convenient though.
Let me know if you figure out it or not 🙂
It does, it works using the terminal (ps, the code inside VS code also does not work, the loop does not break at all :p ).
Dimi, tell me if you could manage to collect extra data on ResearchGate (inside of each profile page)
Awesome 👍 What do you mean that it doesn't work in vscode? The code has been written inside vscode. How do you run the code inside vscode? Using code runner extension or from the terminal?
I'm have planned a blog post about a scraping profiles data. I'll try to publish it next week.
@datum_geek, the blog post about scraping profile information is available: dev.to/dmitryzub/scrape-researchga...
Thank you for your suggestion :)
One small questions: how to save the output as a dataframe (pandas)?
If you need to save it: