
In this post I want to introduce you to Tree structures. What they are, how you can use them, and in which situation they can be helpful.
Please note that this is a basic introduction, and by no means the entire story. I might even be wrong somewhere, and if you believe I've screwed up: let me know in the comments or send me a DM.
🌳 What is a Tree?
To answer this question, we first have to look at Graphs. In Graph theory a Graph is a (visual) structure of data points (or Nodes) that are in some way related to each other. This relation can, for example, be a parent with a child or siblings. The relation between these Nodes is shown by a line / vertex (or edge). Within a "normal" Graph these relationships can be all over the place. Every node can be connected to another or even multiple nodes. Edges can zigzag everywhere.
So what is a Tree? It is a subset of a Graph that only allows any two nodes to be connected by one path, rather than unlimited paths.
Graph vs. Tree
For example; If we have a Parent node with 2 child nodes: Child 1 and Child 2, a Graph would allow these relations:
Parent <-> Child 1Parent <-> Child 2Child 1 <-> Child 2
This is also called a cyclic graph because it has a cycle in it (multiple nodes are connected to the same nodes creating cycles in the representation).
Note: Graphs don't have to be cyclic, but they can be.
A Tree on the other hand would only allow something like these relations:
Parent <-> Child 1Parent <-> Child 2
or:
Parent <-> Child 1Child 1 <-> Child 2
Because a picture is worth a thousand words; lets look a (simple) Graph vs. a Tree.

Notice that in the Tree each pair of nodes is only connected by one edge, Therefore there can never be any cycles. That's why Trees are acyclic graphs.
What elements make up a tree?
As we can see in the image above, a Tree always has a single Node at the top. This called the Root Node.
A Node can have a value, but is not forced to. It also may or may not have any child nodes. If a node does not have any children it is called a Leaf 🍃 .
Any node can have multiple children, but some Trees only allow a maximum amount of children per node. These are called N-ary Trees, in which N stands for the maximum amount of children per node. Probably the most famous of these Tree types is the Binary Tree which allows only 2 child nodes; left and right.
There is a lot more to tell about a Tree structures, but for a basic understanding; this should be enough. Let's move on to some action!
🚶 Traversing a Tree
Trees are nice as a visual representation, but you can also walk the complete structure of a Tree and use the data of every node. When we Traverse a Tree we visit every node in the Tree once. And visiting is just a fancy word for: "preforming an action on". This action can be anything you want: print it, save it or change it. Whatever you want to do to a node, you get one visit per node per traversal.
There are lots of ways to traverse a Tree. You can Zig-zag, pick a random order; but there are 2 broad spectrum types of Tree Traversal: Depth-First & Breadth-First.
↙️ Depth-First Tree Traversal
A Depth-First Tree Traversal is an algorithm of traversing a Tree, by picking a specific branch; and keep moving downward into that branch until it reaches the end. Only then will It go back up to find another branch.
Within the realm of Depth-First Tree Traversal there are several types of traversal; three of wich are the most common: PreOrder, InOrder and PostOrder.
These algorithms are recursive; meaning they will start again on the child nodes, and their child nodes, and so on.
In every upcoming example we will be returning the value of every node from the following Binary Tree.

A PHP representation of this tree can look like this:
$root = [
'value' => 4,
'children' => [
[
'value' => 2,
'children' => [
['value' => 1],
['value' => 3],
],
],
[
'value' => 6,
'children' => [
['value' => 5],
['value' => 7],
],
],
],
];
// Helper function to visualize the visiting of a node.
function visit(array $node): int
{
return $node['value'];
}
PreOrder Traversal (node, left (to), right)
When traversing a Tree we start at the Root Node and then apply the algorithm.
In the PreOrder algorithm a node will be visited first, and then it's children from left to right. This process is recursive; meaning it will start again on its children, and so on.
The output of this Traversal will therefore be: 4, 2, 1, 3, 6, 5, 7.
First we visit 4, and then move on to its first (left) child, and apply the same algorithm again. So from that point we first visit 2, and then go to its first (left) child, and apply the algorithm again. When we reach 1 we hit a Leaf. It has no children, and therefore no output for a left or a right node. We've hit the maximum depth of this branch.
So now we backtrack to previous node 2 and finish its algorithm. We go right: 3. This node is also a Leaf. So we backtrack to the previous node: 2. This is now finished; so we backtrack even further to 4. We go right and visit: 6 and the algorithm repeats: Go left: 5; backtrack and go right: 7.
Example code
A PHP implementation of the PreOrder traversal can look like this:
function preOrder(array $node)
{
// First we visit the node itself.
$output[] = visit($node);
// Then apply the algorithm to every child from left -> right.
foreach ($node['children'] ?? [] as $child) {
$output[] = preOrder($child);
}
return implode(', ', $output);
}
echo preOrder($root); // 4, 2, 1, 3, 6, 5, 7
InOrder Traversal (left, node, right)
The algorithm for an InOrder Traversal makes most sense on a Binary tree. This is because we first go left, then visit the node itself and then go right. If we had 3 children we'd need to make a choice what to do with the middle node; befóre or áfter the node itself.
Running this algorithm would produce the following output: 1,2,3,4,5,6,7.
Because this algorithm first visits the left node, we traverse all the way down until we hit the lowest left node 1. Because it has no children, we can't go left anymore. Therefore, we visit the node itself. We can't go right either; so we backtrack to the previous node: 2. This has now exhausted its complete left branch, so we visit the node itself. Then we go to the right node and repeat the algorithm..., etc.
Example code
A PHP implementation of the InOrder traversal can look like this:
function inOrder(array $node)
{
// We extract a possible left and right node for clarity.
$left = $node['children'][0] ?? null;
$right = $node['children'][1] ?? null;
// We'll apply the algorithm on the left node first.
if ($left) {
$output[] = inOrder($left);
}
// Now we visit the node itself.
$output[] = visit($node);
// And apply the algorithm on the right node.
if ($right) {
$output[] = inOrder($right);
}
return implode(', ', $output);
}
echo inOrder($root); // 1, 2, 3, 4, 5, 6, 7
The name InOrder is (most likely) based on the fact that it visits every node in ascending order. But this only works for a so-called Sorted Binary Tree. In this type of tree, every left child is less than the node itself, and the right side is more than the node itself. Just like in our example tree.
PostOrder Traversal (left (to), right, node)
In the PostOrder Traversal we visit the children from a node first (from left to right) and then the node itself. Because of the recursion of this algorithm the output will be: 1,3,2,5,7,6,4.
Since we already had two (exhausting) walk-throughs of the other algorithms, and this one is almost the same process as **PreOrder, I'll let you try this one out on your own.
Example code
A PHP implementation of the PostOrder traversal can look like this:
function postOrder(array $node)
{
// First we'll apply the algorithm on every child from left -> right.
foreach ($node['children'] ?? [] as $child) {
$output[] = postOrder($child);
}
// Then we visit the node itself.
$output[] = visit($node);
return implode(', ', $output);
}
echo postOrder($root); // 1, 3, 2, 5, 7, 6, 4
↔️ Breadth-First Tree Traversal
In a Breadth-First Tree Traversal we start at the Root Node, and then visit the children. But unlike the Depth-First approach, this algorithm is not applied recursively; but more linear. It goes level by level, and therefore it's also called LevelOrder. This algorithm is usually used when the depth of a Tree is unknown or even dynamic.
LevelOrder Tree Traversal
The algorithm for LevelOrder is pretty much the same as PreOrder, but because it is Breadth-First we actually visit the child nodes before visiting the next level of child nodes. So first it will visit the root 4, then its children: 2 and 6, then the children of 2 and 6, etc.
To put this into perspective, the output of a LevelOrder traversal would be: 4,2,6,1,3,5,7. Every level is visited before moving on to the next level.
To implement this behavior you can use a Queue. This is a simple list or array that we append every child node to when a node is visited. You start by adding the Root Node to the queue, and then start a recursive function on the queue which visits the first Node of the queue; adds its children to the queue and then starts over; until the entire queue is empty.
Example code
A PHP implementation of LevelOrder traversal can look like this:
function levelOrder(array $queue, array $output = [])
{
// If the queue is empty, return the output.
if (count($queue) === 0) {
return implode(', ', $output);
}
// Take the first item from the queue and visit it.
$node = array_shift($queue);
$output[] = visit($node);
// Add any children to the queue.
foreach ($node['children'] ?? [] as $child) {
$queue[] = $child;
}
// Repeat the algorithm with the rest of the queue.
return levelOrder($queue, $output);
}
// Put the root on the queue.
$queue = [$root];
echo levelOrder($queue); // 4, 2, 6, 1, 3, 5, 7
🤔 What can Tree Traversal be used for?
If you're anything like me, you like learning stuff like this; but also want / need a practical reason to use it. So let's explore that a bit further.
Note: You absolutely do not NEED a tree for this example. Just like most things in life, you can choose to use it; if you feel like it.
Example: Building a document
Let's say we have a Content Management System (CMS) to create a hierarchy of chapters for a document (or book). It has the following parts:
- A cover page (C)
- A table of contents (TOC)
- Chapters 1 - 3 with various (nested) sub-chapters
Since there is nesting and a hierarchy, your CMS probably already has a tree-like structure. So let's embrace that and put it all in a Tree like this:
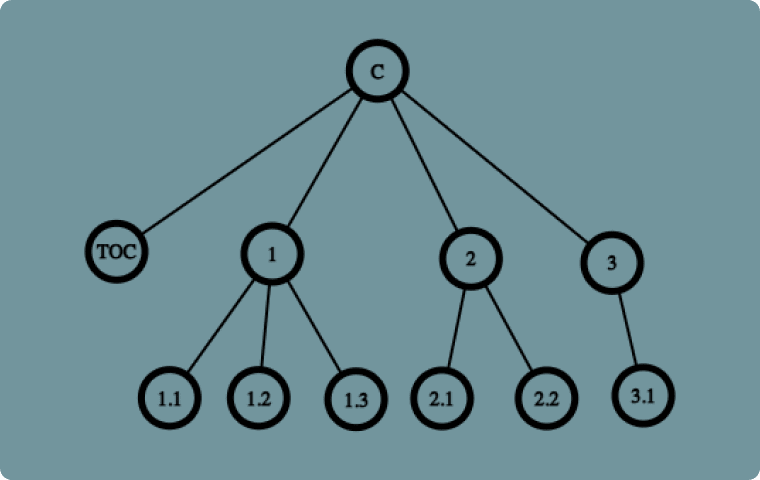
Since a Tree needs a Root Node we'll pick the cover page. Its child nodes will be the Table of contents, and every main chapter. The main chapters all have child sub-chapters.
Rendering the complete document (PreOrder)
If we want to combine every part into a single logical flowing document we can visit the nodes using the PreOrder Traversal. Why? Because we first visit the node itself, and then visit its children from left to right with a Depth-First algorithm. This means the output will be C, TOC, 1, 1.1, 1.2, 1.3, 2, 2.1, 2.2, 3, 3.1.
Another common task to use PreOrder for is cloning a tree. Since we visit every node in the correct order you can completely clone every node, and set the correct parent (because it already exists).
Removing a page from the Tree (PostOrder)
Let's say we don't need the main chapter 2, but we do need its children 2.1 and 2.2 (and their possible (grand-) children). If we were to use the PreOrder traversal, we would visit the main node first. If we were to remove that node; you'd lose al the sub-children as well. To prevent this we can use the PostOrder Traversal. Since this essentially works bottom-up we can move 2.1 and 2.2 up a level (by updating the parent), and then safely remove chapter 2.
Example: Indexing a website (LevelOrder)
For this example we are going to index a website. Our Root Node is the homepage of the website. Because we don't know how many links we are going to encounter, we also can't know what the depth of the Tree is going to be. In these cases it's better to use a Breadth-First traversal. Because this traverses a Tree level-by-level; we can stop the process if it goes to deep. We can set a maximum depth. A Depth-First approach can possibly send you down a very deep branch before it ever comes up again. Not ideal.
When we start at the Root Node, we visit (aka index) it. Then we find every (internal) link on the page and add those pages to the queue; and repeat the process, until the queue is empty.
To prevent a possible infinite loop, because a link can be on multiple pages & linked back to those pages, you need to keep track of every node that has been visited, and only add it to the queue if it hasn't been visited yet.
🔗 Useful links
- 📺 If you want to learn more about Graphs and Tree Traversal I can recommend Back to Back SWE on YouTube.
- 📤 PHP has some helper classes working with Data Structures. For example this SplQueue you can use to implement Breadth-First Traversal.
Thanks for reading
While this article isn't very PHP related; I think it's good to have a basic understanding of the tree principe and the traversal algorithms. You never know in what situation you end up needing this.
I hope you enjoyed reading this article! If so, please leave a ❤️ or a 🦄 and consider subscribing! I write posts on PHP almost every week. You can also follow me on twitter for more content and the occasional tip. If you want to be the first to read my next blog; consider subscribing to my newsletter.





Top comments (0)