Formalising the SLI definition
In a previous post I shared the learning that the SLI should be expressed as a ratio between two numbers. That of good events over valid events

Working that way it allows us to ensure that SLI's fall as a percentage between 0% and 100%.
- 0% nothing is working
- 100% nothing is broken
This means it is intuitive and directly translates to SLO targets and the concept of error budgets.
Also because of the consistent percentage format it means that building tooling to track your SLI's is made easier. Alerting, SLO reporting etc can all be written to expect that same structure. Good events, valid events and your SLO threshold(s).
Valid Events
It might be tempting to consider ALL events. However the phrasing of valid is important as it allows for explicit declarations of events that would not be considered.
EG. You might receive some level of bots accessing your site impacting performance of their requests. As you learn about SLI performance then you can choose to exclude those from valid events. Another example might be that you have hundreds of possible HTTPS API calls but you decrease the scope of SLI monitoring down to specific request paths. So all valid paths are the ones within that scope.
Working example for request/response interaction
Availability
To utilise an SLI for availability then there are two choices to make:
- Which requests are to be tracked as valid
- What makes a response successful
Using terms already covered then it can be expressed as the proportion of valid requests served successfully.
You might be required to write complex logic to identify how available a system might be such as whether or not a user completed a full user journey, discounting where they might have voluntarily exited the process.
For example an e-commerce application might have a journey of:
Search => View => Add to basket => Checkout => Purchase => Confirmation
However people can "drop out" at any stages (irrespective of how available the system is) so measuring the SLI should only consider full user journeys.
Latency
For a web application, much like availability we can define it as the proportion of valid requests served faster than the threshold.
So yet again there are two choices:
- Which requests are to be tracked as valid
- When the timer should start and stop for those valid requests
Setting a threshold for fast enough is dependent on how accurately measured latency translates to the user experience and is more closely related to the SLO target. For example you can engineer a system to give a perception of speed with techniques like pre-fetching or caching.
Commonly you might set a threshold of 95% of all requests will respond faster than the threshold. However it is likely that people will still be happy if a lower percentage is present and generally the results would be long tail. EG. Some individuals will get a very slow experience but small percentages. So it might be worth setting thresholds that target 75% to 90% of requests.
Latency isn't just request/response. There might be scenarios such as data pipeline processing where latency comes in to play.
EG. If you have a batch processing pipeline that executes daily then it should not take more than 24 hours to complete.
A note on tracking latency of jobs is when alerts are triggered. If you only report when a batch job has completed and missed the latency target then you window between the threshold and job completion becomes a problem.
Let us assume a threshold of 60 minutes for a batch job but you job takes 90 minutes and triggers the SLO alert. There was a 30 minute window where we were operationally unaware of something having broken the SLO.
Quality
Back to our percentages, quality can be expressed by understanding two values. The proportion of valid requests served without degrading quality. This leaves our choices as:
- Which requests are to be tracked as valid
- How to determine whether the response was served with degrading quality
Similar to latency it might be worthwhile to set SLO targets across a spectrum because of their interaction with an availability target SLO.
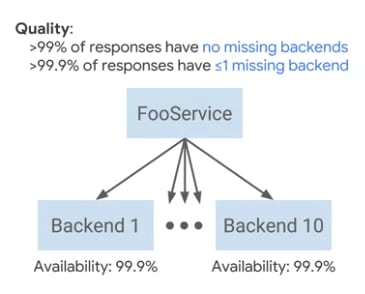
The programme I am studying provides an example of a web application that fans out requests across 10 servers each of which have 99.9% availability SLO and each backend has an ability to reject requests when they are overloaded.
So you might say something like 99% of service responses have no missing backend responses. Further, that 99.9% have less than 1 missing backend response. Illustrated below:




Top comments (0)