
Linear regression is a statistical technique that helps us understand and predict relationships between variables. It is widely used in data science and machine learning.
At its core, linear regression involves finding the best-fitting line through a set of data points, allowing us to make predictions about future values based on past observations.
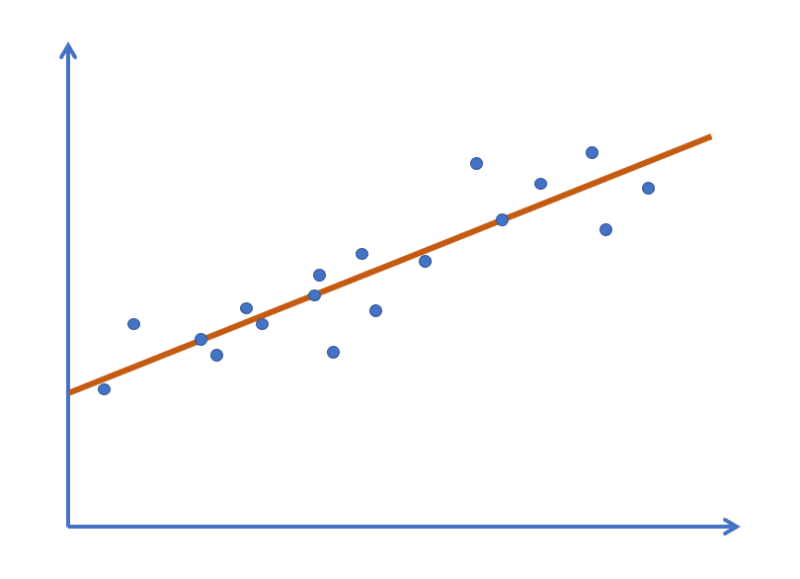
Finding the line can be a complex and computationally-intensive task, especially when dealing with large datasets.
Enter gradient descent... an optimisation algorithm that we can use to find the best-fitting line by iteratively adjusting its parameters.
It's worth noting that linear regression is a form of supervised learning where our algorithm is trained on "labelled" data. This simply reflects the fact that, within the available data, the inputs have corresponding outputs or labels.
In this blog, we will look at the maths, specifically the partial derivatives, involved in applying gradient descent to linear regression.
Model
Given a training set, our aim is to model the relationship so that our hypothesis is a good predicator for the corresponding value of .
For simple or univariate linear regression, our model can be expressed as:
And for multivariate linear regression:
Loss function
We can measure the accuracy of our hypothesis by calculating the mean squared error - including a to simplify the derivatives that follow later.

Gradient descent
We need to minimise the loss to ensure that is a good predicator of .
Gradient descent is well described elsewhere but the principle is that we adjust the parameters until the loss is at the very bottom of the curve.
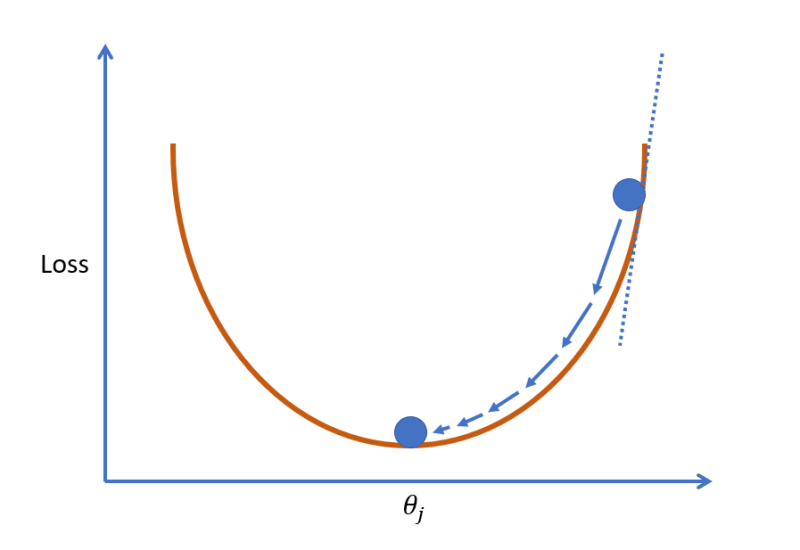
The adjustment is achieved by repeatedly taking the derivative of the loss function (the tangent line) to infer a movement to the right (gradient is negative) or the left (gradient is positive).
The size of each step is relative to a fixed hyper parameter which is called the learning rate. Typical values for are 0.1, 0.01 and 0.001.
This approach can be articulated as:
There are three types of gradient descent:
- Batch gradient descent: Update the parameters using the entire training set; slow but guaranteed to converge to the global minimum
- Stochastic gradient descent: Update the parameters using each training example; faster but may not converge to the global minimum due to randomness
- Mini batch gradient descent: Update the parameters using a small batch of training examples; compromise between efficiency and convergence
Gradient descent derivatives
Imagine we have the following training data:
| x1 | x2 | y |
|---|---|---|
| 5 | 6 | 31.7 |
| 10 | 12 | 63.2 |
| 15 | 18 | 94.7 |
| 20 | 24 | 126.2 |
| ... | ... | ... |
| ... | ... | ... |
| 35 | 42 | 220.7 |
Our model will be:
Let's say we want to apply stochastic gradient descent.
Here are the steps we need to follow:
- Set to 0.001 (say) and , and to random values between -1 and 1
- Take the first training example and use gradient descent to update , and
- Repeat step 2 for each of the remaining training examples
- Repeat the process from step 2 another 1000 times
Let's look at the expressions and derivatives needed, starting with the loss.
When we consider just one training example at a time, as with stochastic gradient descent, .
As such, the loss between our hypothesis and can be described as:
Our gradient descent equation is:
To apply it, we need to determine:
Using the chain rule, we can say that:
One of the linearity rules of derivatives tells us that when differentiating the addition or subtraction of two functions, we can differentiate the functions individually and then add or subtract them.
This means we can say:
Since does not change with respect to :
Therefore:
Let's now consider the two parts to this derivative, starting with the first:
We can reduce this down:
Now let's consider the second part of the derivative:
We can this simplify this for , and as follows:
Let's now combine what we've worked out.
We found that:
Where:
And:
Therefore we can say:
We now have all of the expressions needed to apply gradient descent. Over 1000 iterations, we might expect to see the total loss per iteration decrease like this.

In this post, we looked at the maths, specifically the partial derivatives, involved in applying gradient descent to linear regression.
For more information, check out Andrew Ng's Stanford CS229 lecture on Linear Regression and Gradient Descent.





Top comments (0)