This post shows you how to construct the forward propagation and backpropagation algorithms for a simple neural network. It may be helpful to you if you've just started to learn about neural networks and want to check your logic regarding the maths.
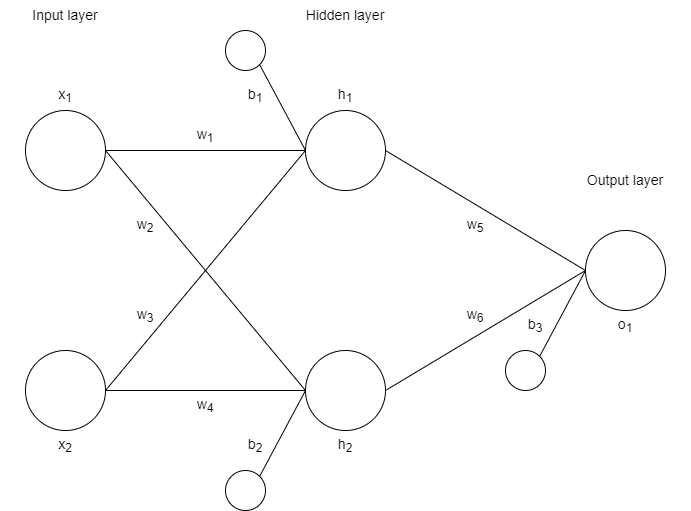
Consider the neural network below. It has two inputs (x1 and x2), two hidden neurons (h1 and h2), one output neuron (o1) and a series of weights and biases.
We want to use this neural network to predict outputs and have four training examples which show the expected output y for different combinations of x1 and x2.
x1
x2
y
0
0
0
0
1
1
1
0
1
1
1
1
Our neural network starts with a random set of weights between 0 and 1, and biases set to 0. In this initial configuration, as you might expect, our neural network will predict outputs which bear no relation to the expected outputs.
To improve the prediction accuracy, we need to optimise the weights and biases so that they work together to predict outputs that are as close as possible to the expected outputs.
This optimisation process is called training and it involves two stages: forward propagation and backpropagation.
Forward propagation
The forward pass stage moves through the neural network from left to right.
Each neuron is configured to sum its weighted inputs with its bias and to then pass that value z through an activation function
σ
to produce an output a.
We can express the sum z and output a for each neuron as:
The activation function
σ
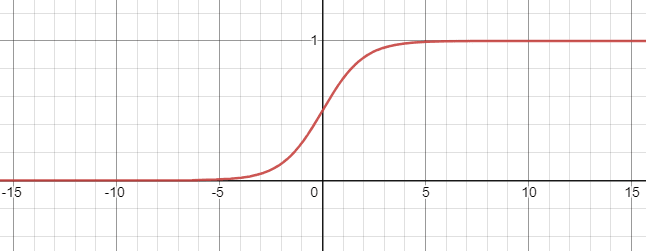
is used to transform a continuous input into an output between 0 and 1, with 0 for large negative inputs and 1 for large positive inputs.
Here we'll apply the commonly-used Sigmoid function for activation:
σ(z)=1+e−z1
With these equations, we can use the x1 and x2 from each of the training examples to predict an output (ao1).
To measure the prediction accuracy of our neural network across all of the training examples, we can the Mean Squared Error function to find the total loss J:
Total loss, J=2m1i=1∑m(ao1−y)2
where m is the total number of training examples; in our case, m = 4.
To begin, the total loss J is almost certain to be greater than zero unless we have been particularly fortunate with our random weights and biases.
More likely we will need to optimise the weights and biases and to do that, we use backpropagation.
Backpropagation
Backpropagation moves backwards through the neural network, from right to left.
Using equation from above for the total loss J, if we consider just a single training example with m = 1, we can define a loss L:
Loss, L=21(ao1−y)2
The loss L is dependent on ao1 which itself is dependent on all of the weights and biases. It follows that optimising these weights and biases will reduce the loss L.
Using an iterative process, we can optimise each weight and bias using the principle of gradient descent and a suitable learning rate
α
:
wsbt=ws−αdwsdL where s = 1, 2, ..., 6=bt−αdbtdL where t = 1, 2, 3
To use these equations, we first need expressions for the derivative of the loss L with respect to each weight and bias. These expressions are partial derivatives which we can derive using the chain rule.
Before we start, there are two derivatives that we will come in handy. The first is the derivative of the Sigmoid activation function:
σ(z)dzdσ(z)=1+e−z1=σ(z)(1−σ(z))
The second is the derivative of the loss L with respect to ao1:
Ldao1dL=21(ao1−y)2=(ao1−y)
Let's now start with weight w6 and find the derivative of loss L with respect to w6:
With expressions for the derivative of the loss L with respect to each weight and bias, we can now train our neural network using the gradient descent equations that we saw earlier:
wsbt=ws−αdwsdL where s = 1, 2, ..., 6=bt−αdbtdL where t = 1, 2, 3
Here's the step-by-step process for training:
Step 1. Take the first training example
Calculate the current outputs from each neuron using the forward propagation equations
Update the weights and biases using the gradient descent equations
Step 2. Repeat step 1 with each of the remaining training examples
Step 3. Repeat the entire process another 10,000 epochs
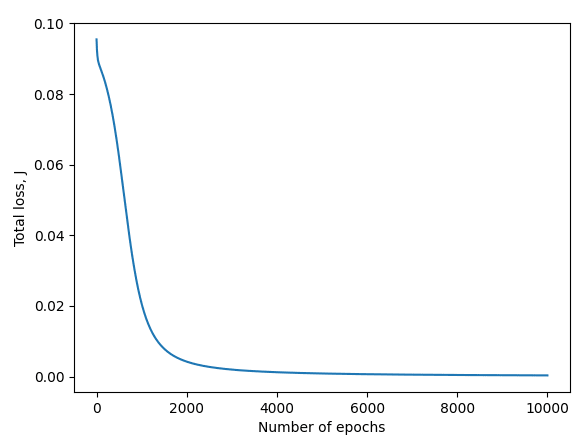
After 10,000 epochs, the total loss J of our neural network should reduce, leading to an improvement in prediction accuracy.
In a perfect scenario, plotting the total loss J against the number of iterations performed will reveal something like this:
With this sort of outcome, our trained neural network should do pretty well at predicting outputs that are very close to the expected outputs. For example:
x1
x2
y
ao1
0
0
0
0.04
0
1
1
0.98
1
0
1
0.98
1
1
1
1.00
If we find the total loss J has not reduced at all or sufficiently after training, further optimisation may be achieved by experimenting with different learning ratesα
(e.g. 0.1, 0.01, 0.001). That's another topic in its own right...
Summary
Congratulations if you made it to the end and thanks for reading!
Here's what we covered, some in more detail than others:
Forward propagation
Sigmoid activation function
Concept of loss L and total loss J
Backpropagation using partial derivatives and the chain rule
Training to minimise the total loss J
Please comment below if you found this post useful or if you've spotted an error.
Top comments (0)
Subscribe
For further actions, you may consider blocking this person and/or reporting abuse






Top comments (0)