
In recent years, it has become apparent that almost no production system is complete without real-time data. This can also be observed through the rise of streaming platforms such as Apache Kafka, Apache Pulsar, Redpanda, and RabbitMQ.
This tutorial focuses on processing real-time movie ratings that are streamed through Redpanda, a Kafka-compatible event streaming platform. The data can be used to generate movie recommendations with the help of Memgraph and the Cypher query language.
Prerequisites
To follow this tutorial, you will need:
- Docker and Docker Compose (included in Docker Desktop for Windows and macOS)
- Memgraph Lab - an application that can visualize graphs and execute Cypher queries in Memgraph.
- A clone of the data-streams repository. This project contains the data stream, a Redpanda setup and Memgraph.
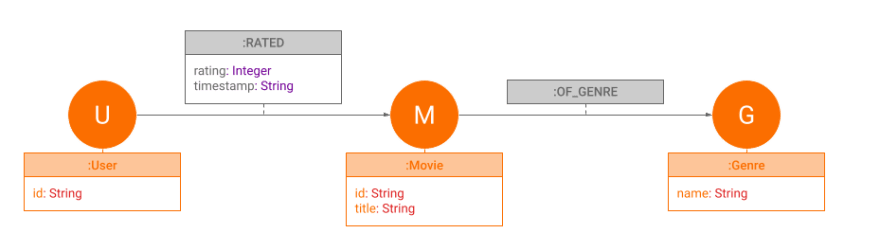
Data model
In this example, we will use the reduced MovieLens dataset streamed via Redpanda.
Each JSON message will be structured like the one below:
{
"userId": "112",
"movie": {
"movieId": "4993",
"title": "Lord of the Rings: The Fellowship of the Ring, The (2001)",
"genres": ["Adventure", "Fantasy"]
},
"rating": "5",
"timestamp": "1442535783"
}
So how are we going to store this data as a graph?
There are three different types of nodes: Movie, User, and Genre.

Each movie can be connected with an OF_GENRE edge to a different genre. A user can
rate movies, and these ratings will be modeled with the edge RATED. This edge contains the properties rating, which can range from 1.0 to 5.0, and timestamp.
Each Movie has the properties id and title while each User has the property id. A Genre only contains the property name.
1. Start the Redpanda stream
We created a Redpanda topic which you can connect to for the purpose of this tutorial. Clone the data-streams repository:
git clone https://github.com/memgraph/data-streams.git
Run the following command to start the Redpanda stream:
python start.py --platforms redpanda --dataset movielens
After the container starts, you should see messages being consumed in the console.
2. Start Memgraph
Usually, you would start Memgraph independently using Docker but this time we are going to use the data-streams project. Given that we need to access the data stream running in a separate Docker container, we need to run Memgraph on the same network.
1. Position yourself in the data-streams directory you cloned earlier.
2. Build the Memgraph image with:
docker-compose build memgraph-mage
3. Start the container:
docker-compose up memgraph-mage
Memgraph should be up and running. You can make sure by opening Memgraph Lab and connecting to the empty database.
3. Create the transformation module
Before we can connect to a data stream, we need to tell Memgraph how to transform the incoming messages, so they can be consumed correctly. This will be done through a simple Python transformation module:
import mgp
import json
@mgp.transformation
def rating(messages: mgp.Messages
) -> mgp.Record(query=str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message = messages.message_at(i)
movie_dict = json.loads(message.payload().decode('utf8'))
result_queries.append(
mgp.Record(
query=("MERGE (u:User {id: $userId}) "
"MERGE (m:Movie {id: $movieId, title: $title}) "
"WITH u, m "
"UNWIND $genres as genre "
"MERGE (m)-[:OF_GENRE]->(:Genre {name: genre}) "
"CREATE (u)-[:RATED {rating: ToFloat($rating), timestamp: $timestamp}]->(m)"),
parameters={
"userId": movie_dict["userId"],
"movieId": movie_dict["movie"]["movieId"],
"title": movie_dict["movie"]["title"],
"genres": movie_dict["movie"]["genres"],
"rating": movie_dict["rating"],
"timestamp": movie_dict["timestamp"]}))
return result_queries
Each time we receive a JSON message, we need to execute a Cypher query that will map it to a graph object:
MERGE (u:User {id: $userId})
MERGE (m:Movie {id: $movieId, title: $title})
WITH u, m
UNWIND $genres as genre
MERGE (m)-[:OF_GENRE]->(:Genre {name: genre})
CREATE (u)-[:RATED {rating: ToFloat($rating), timestamp: $timestamp}]->(m)
This Cypher query creates a User and Movie if they are missing from the database. Movies are also connected to the genres they belong to. In the end, an edge of the type RATED is created between the user and the movie, indicating a rating.
Now that we have created the transformation module, another question arises. How to load a transformation module into Memgraph?
1. First, find the id of the container (CONTAINER_ID) where Memgraph is running:
docker ps
Note the id of the memgraph-mage container.
2. Now, you can copy the movielens.py transformation module to the Memgraph container with the following command:
docker cp movielens.py CONTAINER_ID:/usr/lib/memgraph/query_modules/movielens.py
3. Load the module with the following Cypher query:
CALL mg.load("movielens");
If you don't receive an error, the module was loaded successfully.
4. Connect to the Redpanda stream from Memgraph
1. Open Memgraph Lab and select the Query tab from the left sidebar.
2. Execute the following query in order to create the stream:
CREATE KAFKA STREAM movielens_stream
TOPICS ratings
TRANSFORM movielens.rating
BOOTSTRAP_SERVERS "redpanda:29092";
3. Now, that we have created the stream, it needs to be started in order to consume messages:
START STREAM movielens_stream;
4. It's time to check if the stream was created and started correctly:
SHOW STREAMS;
That's it! You just connected to a real-time data source with Memgraph and can start exploring the dataset. If you open the Overview tab in Memgraph Lab, you should see that a number of nodes and edges has already been created.
Just to be sure, open the tab Graph Schema and click on the generate button to see if the graph follows the Data model we defined at the beginning of the article.
5. Analyze the streaming data
For data analysis, we will use Cypher, the most popular query language when it comes to graph databases. It provides an intuitive way to work with property graphs. Even if you are not familiar with it, the following queries shouldn't be too hard to understand if you have some knowledge of SQL.
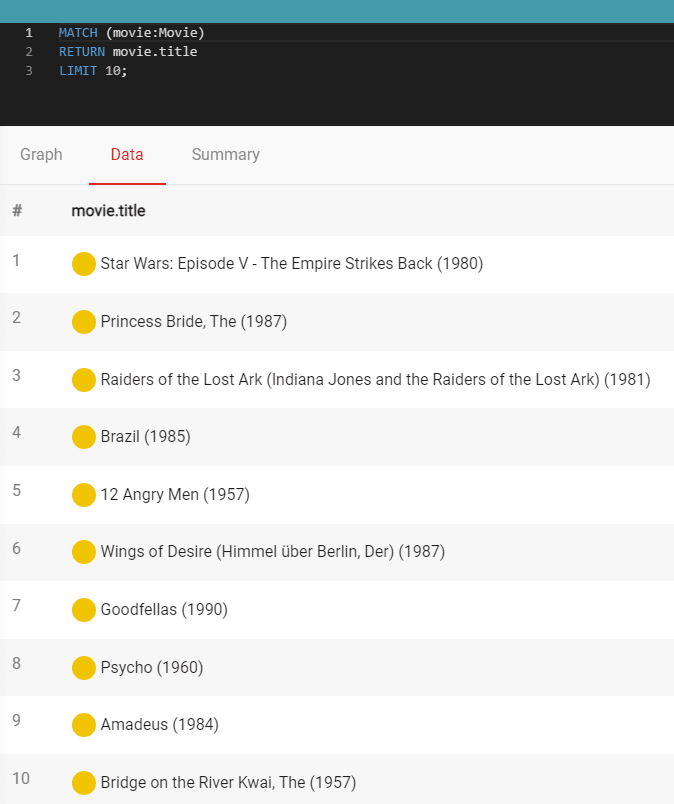
1. Let's return 10 movies from the database:
MATCH (movie:Movie)
RETURN movie.title
LIMIT 10;
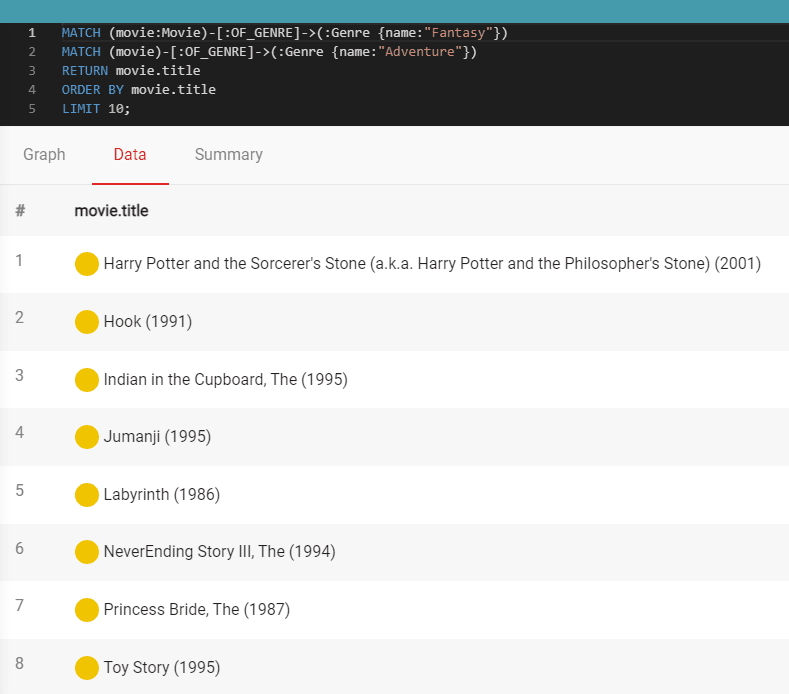
2. Find movies that are of genre Adventure and Fantasy:
MATCH (movie:Movie)-[:OF_GENRE]->(:Genre {name:"Fantasy"})
MATCH (movie)-[:OF_GENRE]->(:Genre {name:"Adventure"})
RETURN movie.title
ORDER BY movie.title
LIMIT 10;
3. Calculate the average rating score for the movie Matrix:
MATCH (:User)-[r:RATED]->(m:Movie)
WHERE m.title = "Matrix, The (1999)"
RETURN avg(r.rating)

4. It's time for a more serious query. Let's find a recommendation for a specific user, for example, with the id 6:
MATCH (u:User {id: "6"})-[r:RATED]-(p:Movie)
-[other_r:RATED]-(other:User)
WITH other.id AS other_id,
avg(r.rating-other_r.rating) AS similarity,
count(*) AS similar_user_count
ORDER BY similarity
LIMIT 10
WITH collect(other_id) AS similar_user_set
MATCH (some_movie: Movie)-[fellow_rate:RATED]-(fellow_user:User)
WHERE fellow_user.id IN similar_user_set
WITH some_movie, avg(fellow_rate.rating) AS prediction_score
RETURN some_movie.title AS Title, prediction_score
ORDER BY prediction_score DESC;

And that's it, you have generated recommendations based on the similarity of ratings between each user. If you want to find out more about this query, definitely check out our tutorial where we go more into detail.
Conclusion
Analyzing real-time data from streaming platforms has never been easier. This also applies to graph analytics, as we have demonstrated through the use of Redpanda and Memgraph. By applying network analytics and graph databases on streaming data, we can uncover hidden insights almost instantaneously while not sacrificing performance.
If you have any questions or comments, check out the Memgraph Discord server or leave a post on the forum.





Top comments (0)