
This week we're going to talk about S3. S3 is the service that the majority of developers are the most familiar with. Yet it is a service that can go really deep and has some crazy features that are not that known to the public. For that reason, I have split it in 2 parts.
In the first one we're going to talk about the basics, along with terminology and some concepts like CORS and more. Let's get started.
S3 Overview
Time for AWS S3 (Simple Storage Service)
- A service to store objects (files) in buckets (directories)
- Each bucket is created on a region level and its name needs to be globally unique
S3 Objects
Let's talk about AWS S3 Objects (files)
- Everything after the bucket name is called a key
- It is composed by a prefix and the object name
- The UI will trick you that S3 has a concept of directories within buckets but it doesn't
- Each object is max 5GB, otherwise multi-part upload
S3 Versioning
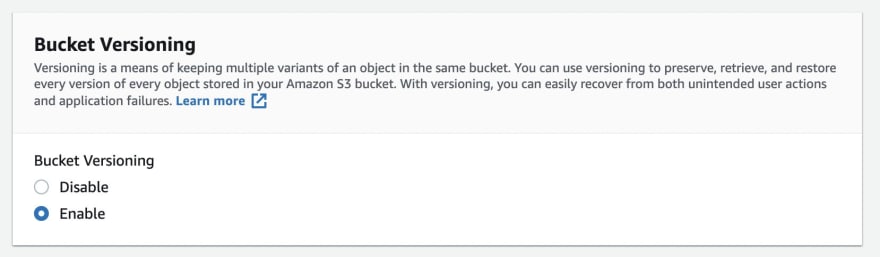
Let's talk about versioning in AWS S3
- It can be enabled on a bucket level and same key will increment its version by 1,2,3
- It is a good practice that can protect against accidental deletes and we can easily rollback
- Files without prior version will have version set to null
S3 Object Encryption
SSE-S3. It encrypts S3 objects using keys handled and managed by AWS.
- It is a server side encryption with the AES-256 algorithm and requires the header
"x-amz-server-side-encryption": "AES256"
SSE-KMS which is managed by KMS (Key management Service).
- Here we can manage access and also create an audit trail with access history.
- It is also a server side encryption and requests the header
"x-amz-server-side-encryption": "aws:kms"
SSE-C which is for managing your own keys. S3 doesn't store the key you provide.
- It is HTTPS only and the encryption key is required in the header in every request
Finally we have the Client Side Encryption which requires the a library to manually be configured on the client side.
- Such library can be Amazon S3 Encryption Client.
- For that encryption type, the client needs to encrypt their data before upload and decrypt them after download
S3 Security
Today let's talk about AWS S3 Security.
We can have
👤 User based.
IAM policies for API calls allowed per user from the IAM console
🪣 Resource based.
Bucket policies that allow cross account access
Object ACL (Access control list) for finer grain
Bucket ACL less common
An IAM principal can access an S3 object if
The user IAM permissions allow it
or the resource policy allows it
and there is no explicit deny
We can enable MFA delete.
This needs the bucket to be version and will ask the user to add an MFA code in order to delete an object.
This can only be enabled from the AWS CLI
Finally we have pre-signed URLs.
These are URLs that give the same permissions as the user generating them and are valid for limited time.
These can also only be generated from the AWS CLI
An common use case is websites that offer premium video service for logged in users
S3 bucket policies
Let's talk a bit more about AWS S3 bucket policies
They are JSON based policies for
- Resources like buckets and objects
- Actions like set of API to allow or deny
- Principal where the account or user to apply the policy to
The AWS recommended way for creating policies is via the policy generator
Examples of policies.
- Grant public access to the bucket
- Force upload encryption for objects
- Grant access to another account (cross account)
CORS
Let's talk about the CORS concept and how is it applied in AWS S3
CORS stands for Cross-Origin Resource sharing and is a web browser based mechanism to allow requests to other to other origins while visiting the main origin
CORS has 3 components.
Protocol which in this case is HTTPS
Host which is http://example.com
Port which is 443 due to HTTPS (80 for HTTP)
Websites on the same domain and subdomain are same origin
Like https://example.com/hello or https://example.com/about
Different origins are all the rest like https://client.example.com and https://api.example.com
For S3 CORS
If a client does a cross-origin request on our S3 buckets, we need to enable the correct CORS headers
We can add * to allow all origins or specify the one we want
S3 Consistency model
Let's talk about the AWS S3 consistency model.
That problem is due to data replication after we add new objects.
Sometimes if we query that object straight away instead of a 200, we may get a 404.
This is called "eventually consistent"
Eventual consistency can also happen when updating or deleting objects.
For updates we might get the old version of the object and for deletes we might still get a 200.
Here's how to enable "strong consistency" https://aws.amazon.com/s3/consistency/
MFA Delete
We can now go a bit deeper and talk about some more advanced AWS S3 concepts and more specifically MFA Delete.
- This is a security setting which requires the user to put their MFA code in order to delete an object
- It can only be enabled or disabled via the CLI of the AWS root account and requires bucket versioning to be enabled.
- MFA code will be required only for permanently deleting an object version or suspending versioning on the bucket.
S3 Access Logs
Let's talk about AWS S3 access logs
For audit purposes, we can log all access to S3 buckets
Any request to S3 from any account authorised or denied will be logged into another S3 bucket
We can then use Amazon Athena (or other data analysis tools) to analyse these data
A huge warning here is to not enable the same bucket for monitoring and logging
That is because we can end up in an infinite loop and wake up to a gigantic bill due to the exponential growth of the bucket size
Summary
I really enjoyed learning more about S3. I now feel comfortable that I can do some more advanced configuration with S3 and feel confident using it. Where there any facts out of the ones I posted today you would like to add to? Next week is getting deeper into S3 and we will also talk about Glacier and Athena.





Top comments (0)