
GraphQL has now been around for over 5 years, and has been adopted across companies as varied as GitHub, Airbnb, New York Times, Philips, government organisations and some of today’s fastest growing startups. GraphQL is an API specification created at Facebook that took the developer world by storm. The core of GraphQL’s popularity was the developer experience and productivity it provided to the frontend/full stack developer, who no longer needed to wait on a backend developer to build an API for them. The ability to dynamically fetch whatever data is required is a productivity dream that GraphQL seemed to be in the best place to enable.
However the realities of enabling GraphQL inside of an organization are multifold. GraphQL promises one single API for all your application development needs. For this to indeed be true, the GraphQL API needs to be able to fetch data across multiple domains. This opens up further architectural challenges to account for performance, security and scalability as well as organisational challenges of how teams should be architected - where is authorization handled, who is responsible for performance, how is the GraphQL API maintained, how does the workflow change for each microservice author, and so on.
Meanwhile, in an adjacent data universe of analytical / static data, the idea of a data mesh was born.
What is a Data Mesh?
The idea of data mesh was introduced by Zhamak Dehghani (Director of Emerging Technologies, Thoughtworks) in 2019. Zhamak describes Data Mesh as “an architectural paradigm that unlocks analytical data at scale; rapidly unlocking access to an ever-growing number of distributed domain data sets, for a proliferation of consumption scenarios such as machine learning, analytics or data intensive applications across the organization. Data mesh addresses the common failure modes of the traditional centralized data lake or data platform architecture, with a shift from the centralized paradigm of a lake, or its predecessor, the data warehouse. Data mesh shifts to a paradigm that draws from modern distributed architecture: considering domains as the first-class concern, applying platform thinking to create a self-serve data infrastructure, treating data as a product and implementing open standardization to enable an ecosystem of interoperable distributed data products.”
Can the Data Mesh concept be applied to operational data?
Operational data is becoming increasingly fragmented - data is stored across multiple databases depending on the nature of the data. Relational and transactional data could be in Postgres/MySQL (and increasingly in distributed and scale-out flavours of these databases!), search data or materialized data could be in a document stores like Mongo & Elastic, and workload specific data like timeseries could use another type of databases. In addition to this, data that’s required to be accessed by applications could come from 3rd party SaaS services and CMSes. Although the data is spread across these sources, they’re still potentially inter-related and fulfil the goals of a domain.
Similar to what the data mesh tries to address with analytical data, distributed operational & transactional data can also be made self-serve for application developers by creating a single semantically unified API so that frontend / full stack developers can access any data fast to build applications and experiences for their users.
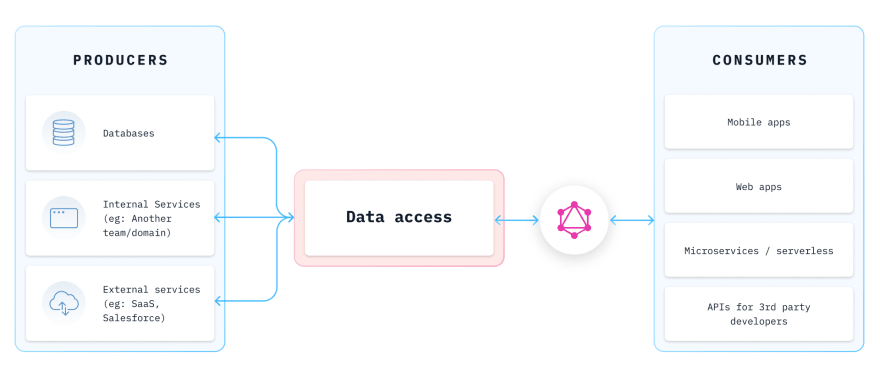
The promise of GraphQL and the architectural concept of the data mesh seem to be perfectly suited to solve the application development challenges of the modern enterprise - with an extreme focus on developer productivity and enablement of the application developer; both of which are themes very dear to our hearts at Hasura!
The Enterprise GraphQL Conference:
In the second edition of the Enterprise GraphQL Conference, we’re exploring these concepts with technical & business leaders who are at the forefront of these changes - either implementing it within their organization or working with organizations who are trying to solve these challenges at scale.
The 3-hour mini-conference has a power-packed line up with:
- Tanmai Gopal, Hasura’s CEO, will be kicking off this conference with an introduction to the concepts behind the Data Mesh. He will also talk about how GraphQL is an ideal choice for building a Data Mesh.
- Rachel Stephens, a Senior Analyst at RedMonk, will talk about how databases have evolved to solve different use cases over the years. She’ll also give us a peek into what we can expect from database technologies in the future.
- Arun Vijayvergiya, Staff Engineer at Airbnb: Last year, Airbnb introduced Viaduct - data-oriented service mesh - at EGC. This year, Arun will talk about how it’s evolved to serve most of Airbnb’s traffic and its impact on how they create and operate services.
- Engineers from Nutrien Australia, will share their experiences and everything they learnt building and operating a Data Mesh powered by GraphQL, Typescript, Hasura, and React Native Web.
- Zhamak Dehghani, the creator of the concept of the Data Mesh, in a fireside chat with our CEO Tanmai Gopal on porting the data mesh over to operational data.
If you’re a technical leader exploring ways to amplify developer productivity in your organization, or an architect looking to understand modern architectures to deal with the proliferation of data sources that your teams need to access or a developer looking to understand the use-cases of GraphQL at scale, this conference is for you!
We look forward to having you join us on the 28th October from 9AM PST - 12PM PST for 5 power-packed sessions on this theme! Register here → https://hasura.io/enterprisegraphql/

Top comments (0)