
Hello everyone,
It's Niraj again and today, I will be sharing my code contribution of the forth week of the GSoC. If you haven't read my previous week's blog. Please read it first.
What did I do this week?
As I have mentioned in my past blog, our upstream build had a bug and due to that I couldn't create pull request for my work on asynchronous cvedb. I have created PR: Added asynchronous cvedb module after a patch for the bug got merged.
I have improved many things in this PR since I last discussed. I am using aiohttp to download NVD dataset instead of requesting with multiprocessing pool. This has improved our downloading speed since now every tasks are downloading concurrently in same thread instead of 4 tasks at a time with process pool. My teammate Harmandeep singh is working on improving output of the CVE Binary Tool and he has mentioned me that he is going to use rich library to improve console output and it also provides beautiful progress bar so, it would be nice to have one for updating database. So, I have started looking into the docs of the rich library and I have implemented the progress bar functionality for downloading and loading database. Here is the quick demo:
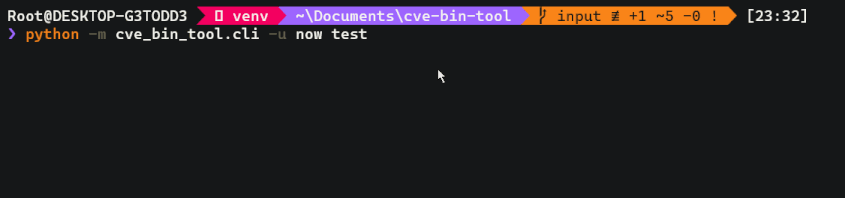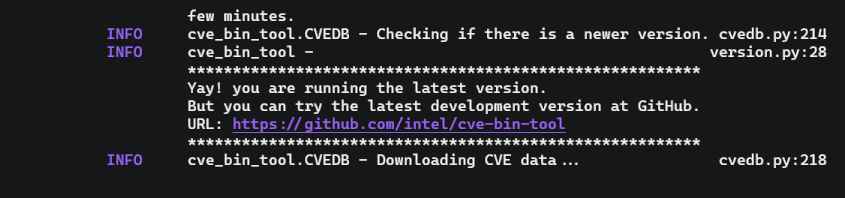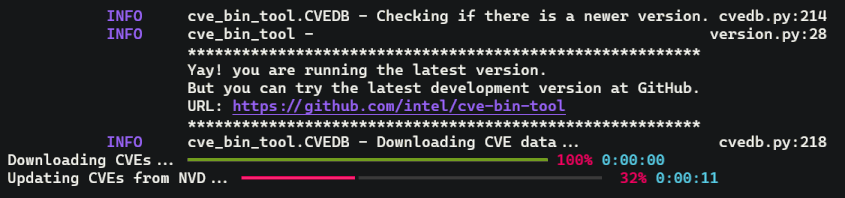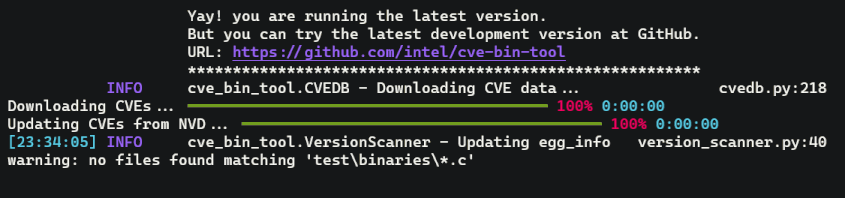
To implement this, I have used track function from rich library which create a wrapper around normal generator to provide progress bar functionality. Normally in asyncio workflow, we create bunch of tasks and wait for all of them to finish but to track progress I need to have a generator that yield a task as they complete. Hopefully, asyncio provide this functionality with asyncio.as_completed generator which yield task as they finished. Here is the code for that:
total_tasks = len(tasks)
for task in track(
asyncio.as_completed(tasks),
description="Downloading CVEs...",
total=total_tasks,
):
await task
Here, a task is a coroutine that download CVEs for a year from NVD datafeeds and tasks are simply list of these tasks.
Currently, we are using official curl website to supplement CVEs for curl. They provide tabular data of CVE description, from version, to version, CVE number and CWE. Until now, we were only fetching CVE number from the website and storing it to our local database but now I am storing every fields from the curl website and storing it to the local cache and database. This will help user get more detailed information.
There was also a bug in my code for getting event loop and it was breaking our CI. I have found out that event loop can only exist in the main thread by default and since we are running tests in parallel with pytest-xdist and sometimes, CI fails with RuntimeError: There is no current event loop in thread 'Dummy-1' and I have fixed it with creating my own custom get_event_loop function which tries to get event loop using asyncio.get_event_loop but if it can't then it creates a new event loop and set it as default event loop for this thread. Here's the snippet for my custom get_event_loop:
def get_event_loop():
try:
loop = asyncio.get_event_loop()
except RuntimeError:
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
if sys.platform.startswith("win"):
if isinstance(loop, asyncio.SelectorEventLoop):
loop = asyncio.ProactorEventLoop()
asyncio.set_event_loop(loop)
return loop
I have also fixed a small bug in extractor module pointed out in issue #766. I also resolved changes requested by my mentor for my cvedb PR.
What am I doing this week?
I am going to start my work on input_engine module this week and I am hoping to replace our csv2cve module with modern input_engine this week.





Top comments (0)