As a freelance I worked on document certification using blockchain. I received several similar requests, but one of them required the implementation of a new data structure: Merkle Trees. It is a data structure widely used in decentralization and for good reasons, thanks to Merkle Trees and Merkle Proofs we set up a certification system with unique properties.
Use cases
In a previous article I described a blockchain timestamping system that allowed one of my clients to certify contracts in an irrefutable and relatively affordable way. One important feature was the ability to prove that a contract was NOT generated a posteriori.
I received a similar request a short time later, with additional constraints. Imagine a service that allows a company to certify the role and salary of its employees. Once this certification is issued, employees may prove, through my client's tool, the veracity of their résumé to a potential employer. It is a type of verification that comes with new constraints:
Constraint 1, Scalability
The quantity of document to be certified was much greater (hundreds of thousands per batch). This makes the "obvious" timestamp system prohibitive: it costs a few pennies to stamp a document. Multiplied by hundreds of thousands of documents, we reach tens of thousands of dollars per batch.
Constraint 2, Confidentiality and Right to Be Forgotten
The document and its proof must remain in the hands of the user. Once the certification has been produced, we want to give the user full control of their data. We must therefore be very attentive to the information that is shared. You cannot timestamp a batch of documents as a single file, because you would then have to send ALL documents to all users.
Constraint 3, Durability
Certification must persist for decades, even if the service provider disappears or abandons the product. This makes decentralized storage systems like IPFS hard to defend because they require "someone" to persist the data. Note that today a service like Filecoin might be suitable, but the solution we have put in place is always more cost effective.
Data Structure: The Merkle Trees
In the previous article we saw the hash functions that let you to calculate the fingerprint of a document. These functions are very useful, because if two people have a document they can quickly calculate their fingerprint and compare them without having to exchange the whole file.
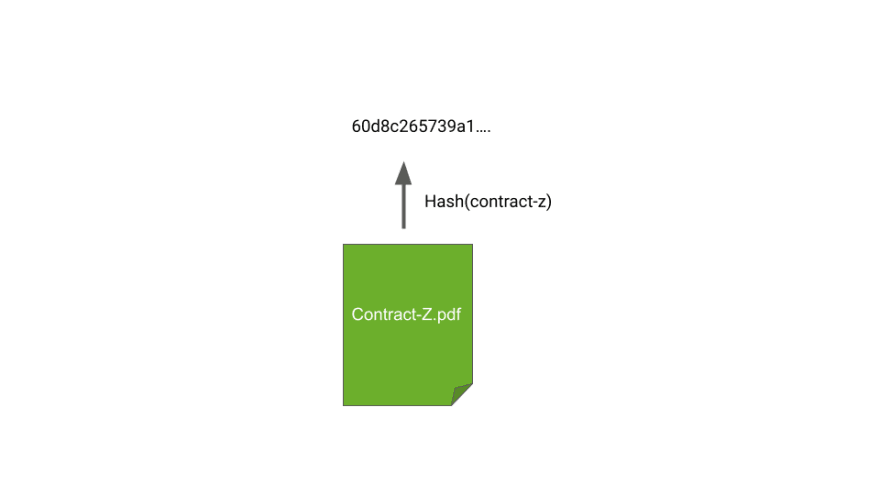
In our case we will push the use of hashes even further with a data structure called the Merkle Tree. It is a tree for which each node contains the hash of its children.
The construction of the tree is simple, we calculate the fingerprint of each document, then we group these fingerprints two by two, and we calculate a new hash. The operation is repeated until a single fingerprint is obtained. This last hash is called the root of the tree.

It is a recursive operation that allows us to take any number of documents and produce a single fingerprint. This is very efficient for our service because we can time stamp this last imprint by following the method in the previous article.
Using this approach, we can timestamp hundreds of thousands of documents very quickly. It takes a long time to compute the tree, but it's an off-chain operation run on a "regular" server. It doesn't cost much. We end up storing a single fingerprint on the blockchain. The cost on the blockchain is therefore the same, regardless of the number of documents to be certified.
This property allows us to pass Constraint 1 (Scalability)
We timestamp the root of our hash tree on the blockchain, and we send a proof to our users.
Merkle Proof
The Merkle Tree has another interesting property: it is possible to prove the existence of any document in the tree without knowing the other documents.
If I send you a document and the intermediate hashes, you can recalculate the root fingerprint and therefore verify that my document has not been modified. For example, in the diagram below, with the two intermediate hashes (in blue) and the Contract B, it is possible to find the root.
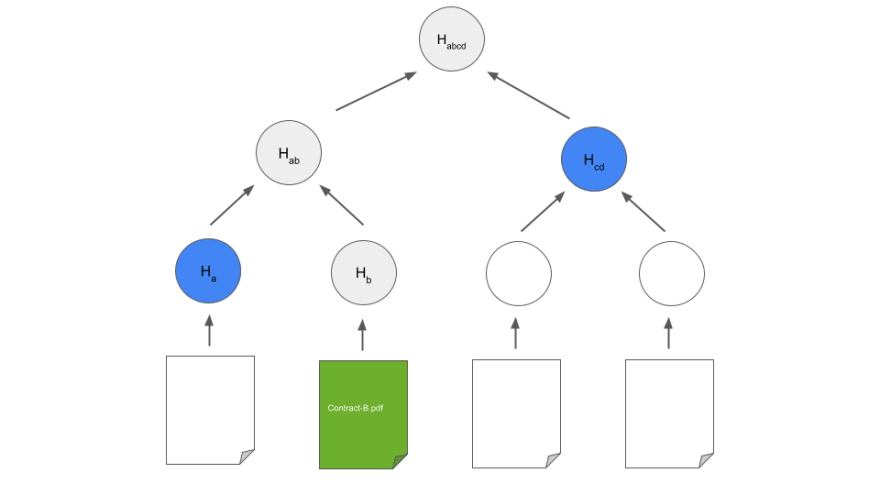
Note that for 4 documents, the proof contains 2 intermediate hashes, For 1024 documents, the proof contains 10 hashes, For 500,000 documents, the proof contains 19 hashes. There is a logarithmic relationship between the input data and the size of the proof sent to users. Basically, the more documents you have, the more "profitable" the solution becomes.
In practice
In practice, this means that a end user has to hold the document AND the proof (the intermediate hashes).
This is an additional constraint but this compromise is useful in our case: only the end user receives the proof associated with their document, therefore they are the sole master of their data.
This property allows us to pass Constraint 2 (Right to Be Forgotten)
Demonstration
We adopted the QR Code solution, here is an example:

This QR Code contains Andrew O’Reilly’s identity, his role in the company, AND proof of merkle. If you read this QR code with your phone, you should come to a web application that will perform the verification described above.
You can also test the application by opening this page
Here is a screenshot of the verification result:

In the next QR Code, I changed Andrew's role to pass him off as the CEO of the company:

It will open the following link: Demo Page you will see that the evidence fails.
And here is the capture of the failed verification:

Note that these QR codes are quite large because they contain ALL of the data to be verified. Our certification system is therefore not based on an external service to store the data, which makes the service sustainable.
This property allows us to pass Constraint 3 (Durability)
The Off-chain Part
The off-chain part is similar to that mentioned in a previous article.

The Blockchain's complexity is "absorbed" by the off-chain part and hidden from the rest of the application. Under these conditions, the blockchain becomes a service "like any other" which provides a very specific functionality in our infrastructure.
Some important details
If you need to implement a similar service, consider:
Make sure that the hash creation and verification process is deterministic:
When checking the proof, we only have the hash to check and the hash of the current proof. However, Hash (A + B) is different from Hash (B + A), so we have to define an ordering for the hashes. For the sake of simplicity I sort them alpha-numerically. Thus the process of calculating the proof is based solely on the information that we have during the proof.
Add entropy on "simple" data
In the case of identity verification, one must take into account the possibility that a malicious user tries to brute-force the fingerprints. With some initial information (name, first name, role), it would be possible to "guess" the other missing information. To avoid this, I add a random string of characters in the data. This makes the hash of the proof unpredictable, even with some or all of the initial data.
Ultimately
The merkle tree is a structure widely used in decentralization. It has very useful properties, in our case it is used to timestamp hundreds of thousands of documents at minimum cost. The proof system lets us implement a timestamping system that also preserves the confidentiality and durability of user's data.
A demonstration of the application is available: blockchain-proof.singulargarden.com.
You can use the QR Code feature as shown above. There is also a more classic document verification on the home page. Here are two sample files and the proof.
If you want to know more or have any questions, please reach out on LinkedIn or Twitter.
You can find the latest version of the article, and subscribe to more on my site.







Top comments (0)