
Intro
Previous episodes recap:
- We want to build a RegEx Engine.
- In the first episode we briefly spoke about the grammar we want to recognize.
- In the second episode we built the lexer (the first of three components we need, the others are the parser, and finally the engine).
This episode is kind of a spin-off, as it isn’t much centered on the RegEx itself, as we will explore Python strings, using the project just as an excuse to learn something new.
Dear Py\thon
Aaagh…Python strings…
The problem with what we created so far is that a string in Python, by default, treats the ‘\’ as an escape.
Thus, in our implementation, the lexer can't read ‘\’, then the following character, and finally decide the meaning of it.
For example, if we escape, for whatever reason, the letter ‘c’ we will get the correct output (an ElementToken with char field = ‘c’), but for the wrong reason. But, if we escape the escape character ‘\’, writing ‘\’, we will note an unexpected behavior:
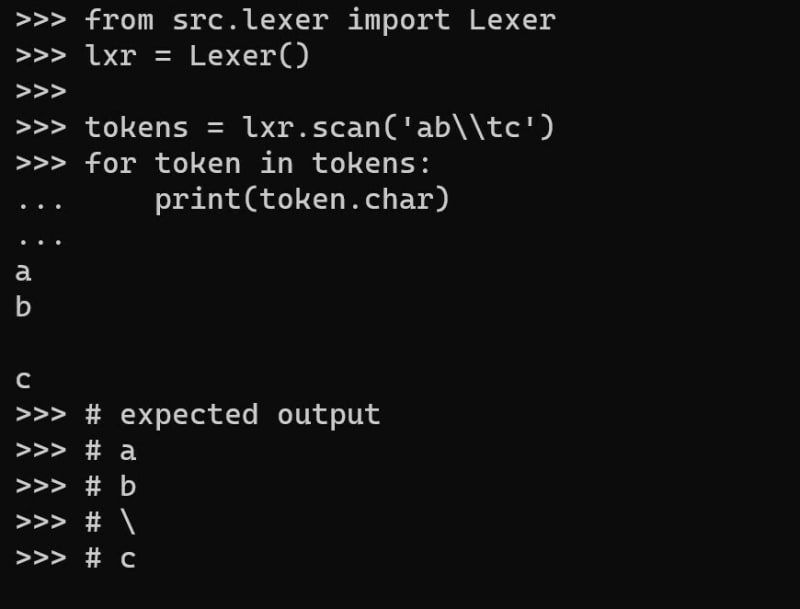
The scanned tokens vs. the expected ones. The hole between b and c is a ‘\t’, while we wanted a ‘\’.
Why is this happening? Is there a bug in the Lexer implementation we have done so far?
The answer is no, there’s no bug in the implementation.
The problem is that Python escaped the escape character for us, so our lexer read ‘\’ as one character, a backslash, and our lexer will escape the next character.
But, this is not the behavior we wanted. We wanted to escape a backslash, not the character following the escaped backslash.
Luckily, it is not difficult to ‘fix’ this behavior, and we have at least two ways to do this.
First Way
The first way is to simply pass the lexer a raw string instead of a string. To do this it is sufficient to prefix the string with an r:
lexer.scan(r'ab\\tc')
Doing this way, unfortunately, the user must remember to pass a raw string instead of a string to the lexer whenever needed.
Second Way
The problem with the first solution is that the user may forget about this particular and his regex will show unexpected behavior.
Maybe we should prevent it and automatically, and always, interpret the string as raw, thus preventing this strange behavior to ever happen.
To achieve this, we should build a function that “convert” our string representation to raw and call it right away before the lexer does any processing.
To do that, we should do something like this [1]:
def str_to_raw(s):
raw_map = {8:r'\b', 7:r'\a', 12:r'\f', 10:r'\n', 13:r'\r', 9:r'\t', 11:r'\v'}
return r''.join(i if ord(i) > 32 else raw_map.get(ord(i), i) for i in s)
In this way, the passed regex is “converted“ to a raw string, and interpreted as raw.
The problem with this approach is that it is extremely hacky, as you should extend raw_map to include every possible escape sequence.
This solution would be very specific on the particular Python implementation, something you should generally avoid whenever possible.
Conclusion
The first solution is most likely the one you want, because of how hacky the second is, but you’re free to implement the solution you prefer or find a better one on your own.
Resources
[1] How to create raw string from string variable in python? — Stack Overflow — Stack Overflow
Cover by Pankaj Patel on Unsplash.





Top comments (0)