This is a Plain English Papers summary of a research paper called Approximate Nearest Neighbor Search with Window Filters. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- This paper proposes a novel approximate nearest neighbor search algorithm that uses window filters to improve search efficiency.
- The algorithm is designed to work with large-scale vector databases, which are commonly used in various applications like image retrieval and recommendation systems.
- The key idea is to use a two-stage filtering process to quickly identify a set of candidate nearest neighbors, and then perform a more accurate search within this reduced set.
Plain English Explanation
The paper describes a new way to quickly find the nearest matching items in a large database of vector data. This is a common problem in many applications, like searching for similar images or recommending products.
The main innovation is a "two-stage filtering" approach. First, the algorithm uses a fast but imprecise way to identify a small set of possible matches. Then, it does a more thorough search just within that reduced set to find the actual nearest neighbor. This is more efficient than searching the entire database each time.
The authors test their algorithm on large-scale vector datasets and show it can provide approximate nearest neighbor search results much faster than previous methods, while still maintaining good accuracy.
Technical Explanation
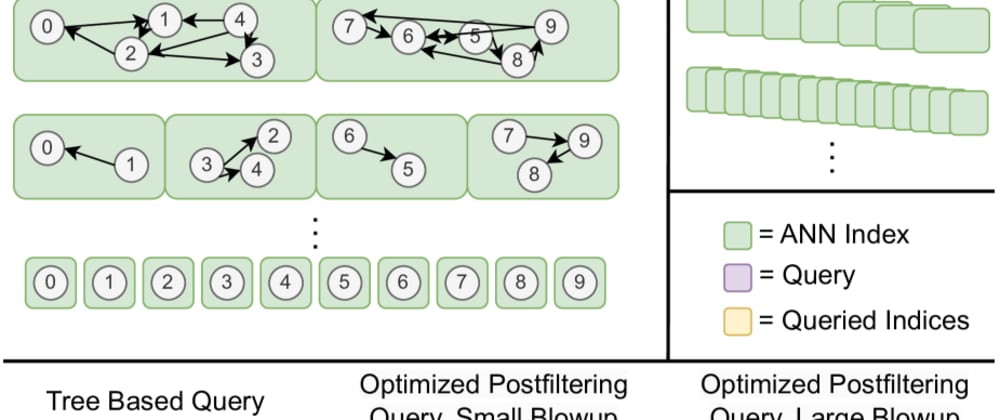
The paper introduces a new approximate nearest neighbor (ANN) search algorithm called "Window Filters". The key idea is to use a two-stage filtering process to quickly identify a set of candidate nearest neighbors, and then perform a more accurate search within this reduced set.
In the first stage, the algorithm uses a "window filter" to construct a set of candidate neighbors. This filter defines a rectangular region around the query vector and selects all database vectors that fall within that region. This can be done very efficiently using specialized data structures like k-d trees.
In the second stage, the algorithm performs a more precise nearest neighbor search, but only within the set of candidates identified in the first stage. This allows it to avoid searching the entire database, which is computationally expensive.
The authors evaluate their Window Filters algorithm on several large-scale vector datasets, including SIFT features and word embeddings. They show it can achieve significant speedups over traditional ANN search methods, while maintaining competitive accuracy.
Critical Analysis
The Window Filters algorithm represents a clever way to improve the efficiency of approximate nearest neighbor search, but it does have some limitations.
One key assumption is that the query vector and its nearest neighbors will be clustered together in the vector space. If this is not the case, for example if the nearest neighbors are spread out, then the window filter may not be effective at reducing the search space.
Additionally, the performance of the algorithm is sensitive to the choice of the window size parameter. If the window is too small, it may miss some relevant neighbors; if it's too large, the efficiency gains will be reduced. The paper does not provide clear guidance on how to set this parameter optimally.
Finally, the algorithm is designed for static datasets. It may not work as well for dynamic datasets where vectors are being continuously added or removed. Adapting the approach to handle such cases could be an interesting area for future research.
Conclusion
Overall, the Window Filters algorithm represents a promising approach for improving the efficiency of approximate nearest neighbor search in large-scale vector databases. By using a two-stage filtering process, it can achieve significant speedups over traditional methods, while still maintaining good accuracy.
While the algorithm has some limitations, it demonstrates the value of leveraging specialized data structures and multi-stage search strategies to tackle the computational challenges of working with massive high-dimensional datasets. As vector-based applications continue to grow, techniques like this will likely become increasingly important.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.





Top comments (0)