This is a Plain English Papers summary of a research paper called New 32B AI Model Masters Complex Reasoning Through Systematic Training Approach. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
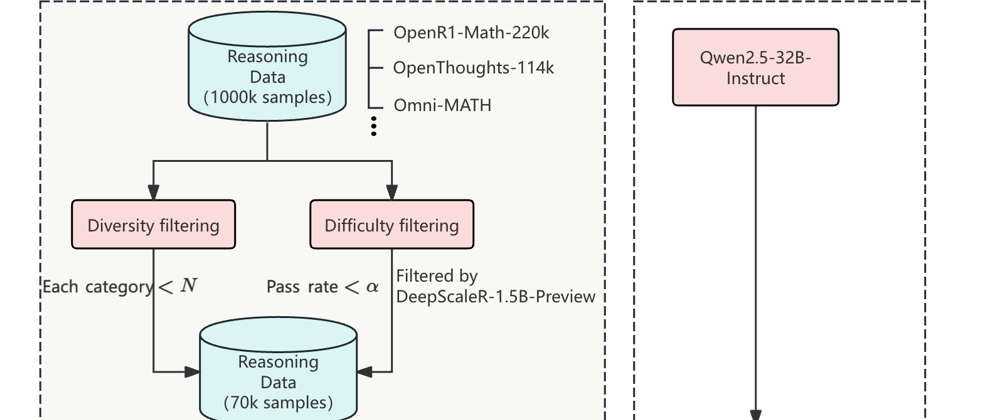
- Light-R1 is a new 32B parameter language model specifically designed for long chain-of-thought reasoning
- Built using a curriculum approach combining Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Reinforcement Learning (RL)
- Started training from scratch rather than building on existing models
- Achieves strong performance on complex reasoning benchmarks with long-form answers
- Demonstrates that systematic training rather than model size is key for reasoning capabilities
Plain English Explanation
Language models have gotten incredibly good at many tasks, but they still struggle with complex reasoning - especially when they need to work through problems step-by-step over long sequences. The researchers behind Light-R1 decided to tackle this challenge head-on.
Instead of...





Top comments (0)