This is a Plain English Papers summary of a research paper called {sigma}-GPTs: A New Approach to Autoregressive Models. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Introduces a new approach to autoregressive models called σ-GPTs (Sigma-GPTs)
- Proposes a novel sampling method that can generate diverse samples while maintaining high quality
- Demonstrates improved performance on language modeling and text generation tasks compared to traditional autoregressive models
Plain English Explanation
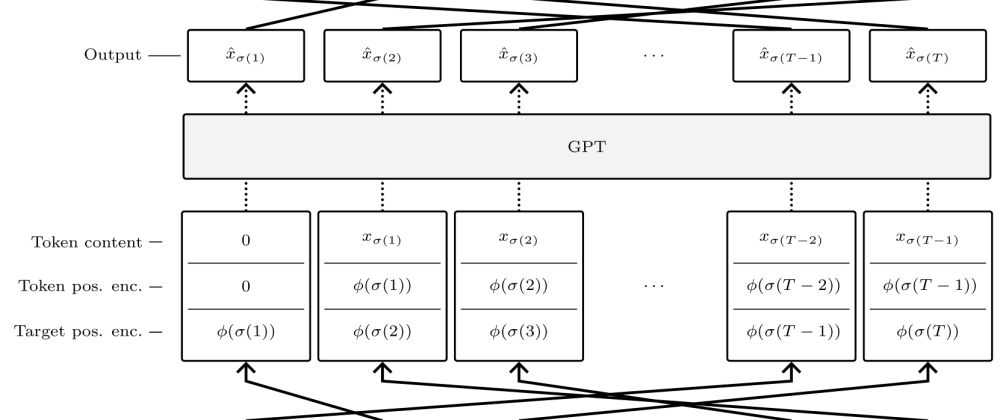
The paper introduces a new type of language model called σ-GPTs (Sigma-GPTs), which take a different approach to autoregressive modeling compared to traditional models like GPT. Autoregressive models work by predicting the next token in a sequence based on the previous tokens. However, this can lead to issues like lack of diversity in the generated samples.
The key innovation in σ-GPTs is a new sampling method that aims to address this problem. Instead of simply selecting the most likely next token, σ-GPTs consider a range of potential tokens and use a technique called "rejection sampling" to select one that balances quality and diversity. This allows the model to generate more varied and unexpected outputs while still maintaining high quality.
The paper demonstrates that σ-GPTs outperform traditional autoregressive models on language modeling and text generation benchmarks, producing more diverse and engaging samples. This could have applications in areas like creative writing, dialog systems, and open-ended text generation.
Technical Explanation
The paper proposes a new approach to autoregressive modeling called σ-GPTs (Sigma-GPTs). Autoregressive models like GPT work by predicting the next token in a sequence based on the previous tokens. However, this can lead to issues like lack of diversity in the generated samples, as the model often simply selects the most likely next token.
To address this, the authors introduce a novel sampling method for σ-GPTs. Instead of just taking the top-k most likely tokens, σ-GPTs consider a wider range of potential tokens and use a technique called "rejection sampling" to select one. This involves evaluating each candidate token based on both its likelihood and a diversity score, and then probabilistically accepting or rejecting it. This allows the model to generate more varied and unexpected outputs while still maintaining high quality.
The paper evaluates σ-GPTs on language modeling and text generation tasks, showing that they outperform traditional autoregressive models. The authors also conduct ablation studies to analyze the impact of different components of the approach, such as the diversity score and the rejection sampling process.
Critical Analysis
The paper presents a promising new approach to autoregressive modeling that addresses important limitations of existing techniques. The authors' use of rejection sampling to balance quality and diversity is an elegant solution to the lack of diversity issue that often plagues autoregressive models.
However, the paper does not delve deeply into the potential downsides or limitations of the σ-GPT approach. For example, the rejection sampling process may introduce additional computational overhead, which could be a concern for real-time applications. The authors also do not explore how the method might perform on more open-ended or creative text generation tasks, where the balance between quality and diversity may be even more crucial.
Additionally, the paper does not address potential biases or unintended behaviors that could arise from the σ-GPT approach. As with any powerful language model, there is a risk of the model perpetuating or amplifying societal biases, producing harmful or offensive content, or being used for malicious purposes like text generation attacks. Further research is needed to understand the safety and robustness of σ-GPTs in real-world applications.
Conclusion
The σ-GPT approach presented in this paper represents a meaningful step forward in autoregressive modeling, addressing a key limitation of traditional methods. By incorporating a novel sampling technique that balances quality and diversity, the authors have demonstrated impressive results on language modeling and text generation tasks.
This research could have significant implications for a wide range of applications that rely on generative language models, from creative writing and dialog systems to personalized recommendation engines and stock market prediction. As the field of generative AI continues to advance, approaches like σ-GPTs may play a key role in unlocking the full potential of these powerful language models.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.





Top comments (0)