This is a Plain English Papers summary of a research paper called WaveCoder: Widespread And Versatile Enhancement For Code Large Language Models By Instruction Tuning. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- The paper presents a novel approach called "WaveCoder" for enhancing language model training on code-related instruction data.
- The approach involves generating refined and versatile synthetic code-related instruction data to improve the performance of large language models on a variety of code-related tasks.
- The authors introduce a new dataset called "CodeOcean" that includes four diverse code-related instruction tasks, which they use to evaluate the effectiveness of WaveCoder.
Plain English Explanation
The researchers have developed a new technique called "WaveCoder" that aims to improve the way language models are trained on data related to coding and programming instructions. The key idea is to generate high-quality, diverse synthetic data that can supplement the training data for these language models, helping them become better at understanding and generating code-related instructions.
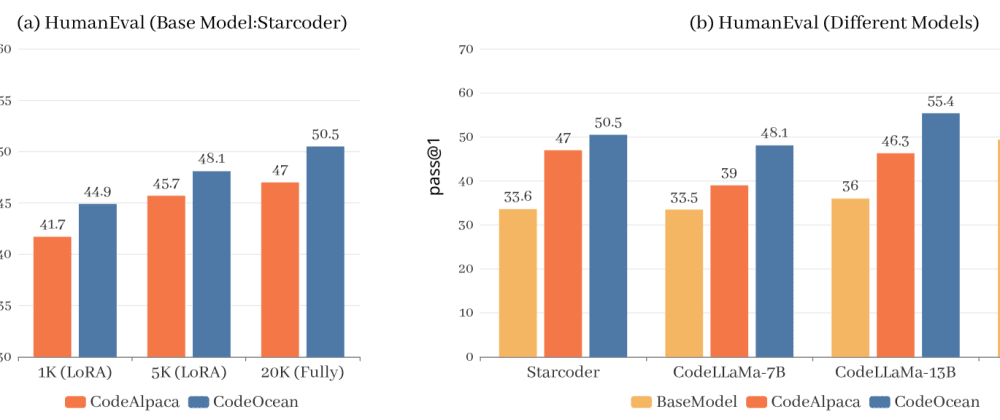
To test their approach, the researchers created a new dataset called "CodeOcean" that includes four different types of code-related tasks, such as [internal link: https://aimodels.fyi/papers/arxiv/alchemistcoder-harmonizing-eliciting-code-capability-by-hindsight] code completion, [internal link: https://aimodels.fyi/papers/arxiv/from-symbolic-tasks-to-code-generation-diversification] code generation, and [internal link: https://aimodels.fyi/papers/arxiv/codeclm-aligning-language-models-tailored-synthetic-data] code summarization. They then used WaveCoder to generate additional training data and evaluated how well the language models performed on the CodeOcean tasks.
Technical Explanation
The paper introduces a new method called "WaveCoder" that aims to improve the training of large language models on code-related instruction data. The key components of WaveCoder include:
Refined Data Generation: The authors develop techniques to generate high-quality, diverse synthetic code-related instruction data that can supplement the training data for language models. This includes [internal link: https://aimodels.fyi/papers/arxiv/genixer-empowering-multimodal-large-language-models-as] leveraging code structure and semantics to create more realistic and varied instruction samples.
Enhanced Instruction Tuning: The authors propose methods to fine-tune large language models on the generated synthetic data, as well as the original code-related instruction data, in a way that enhances the models' understanding and generation of code-related instructions.
To evaluate the effectiveness of WaveCoder, the authors introduce a new dataset called "CodeOcean" that includes four diverse code-related instruction tasks: [internal link: https://aimodels.fyi/papers/arxiv/transcoder-towards-unified-transferable-code-representation-learning] code completion, code generation, code summarization, and code classification. They show that language models trained using WaveCoder significantly outperform models trained on the original data alone across these tasks.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear focus on improving the performance of language models on code-related tasks. The use of a newly created dataset, CodeOcean, to evaluate the effectiveness of WaveCoder is a particular strength, as it allows for a comprehensive assessment of the approach.
One potential limitation of the work is the reliance on synthetic data generation, which could introduce biases or artifacts that might not be present in real-world data. The authors acknowledge this and suggest that further research is needed to understand the implications of using synthetic data for language model training.
Additionally, the paper does not explore the potential downsides or unintended consequences of improving language models' capabilities in code-related tasks. While the authors highlight the practical benefits, it would be valuable to consider any ethical or societal implications that might arise from more powerful code-generation and understanding systems.
Conclusion
The WaveCoder approach presented in this paper represents a significant advancement in the field of language model training for code-related tasks. By generating refined and versatile synthetic data and using it to enhance the instruction tuning process, the researchers have demonstrated substantial improvements in language model performance across a range of code-related benchmarks.
This work has important implications for a variety of applications, from programming assistance tools to automated code generation systems. As the authors note, further research is needed to fully understand the potential limitations and societal impacts of these advancements. Nevertheless, the WaveCoder technique is an important step forward in the ongoing effort to develop more capable and reliable language models for the domain of software engineering and programming.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.





Top comments (0)