![Cover image for Creating a Mini C Compiler using Lex and Yacc [Part 1]](https://media2.dev.to/dynamic/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fzsfr7eqx3c581stuzcvi.jpg)
Have you wondered how a compiler is written? Do you want to learn how to use lex and yacc to write a compiler? Great timing!
About this series
In this series of posts, we will create a small compiler that compiles a subset of C, and then we will build a “virtual machine” that executes the compiled instructions.
I will try to include all details in the posts, but if something doesn’t work or is mistakenly left out, check the GitHub repository for the full code.
Mini C, our language
Before building the compiler, let’s establish what the language is. Here is an example program that can be compiled and run:
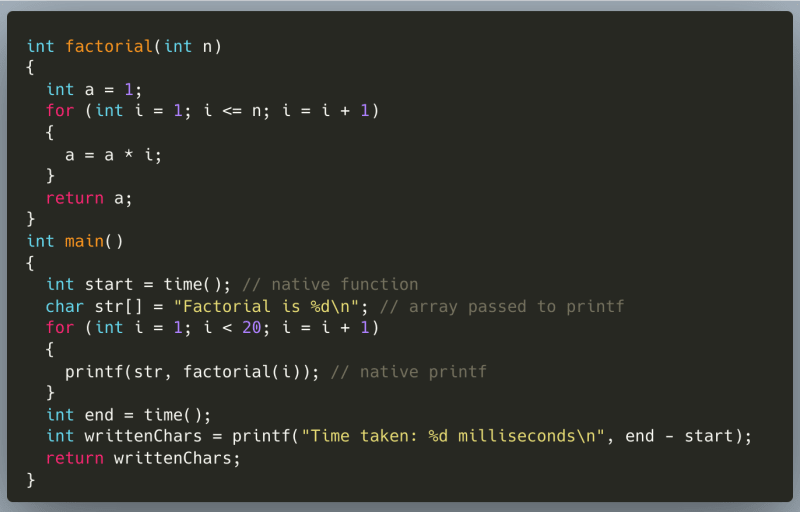
We will go through implementing function calls, adding native functions printf() and time() , multi-dimensional arrays and floating point numbers.
Exciting? Well, whip up your favourite editor, slap on your playlist and fill your coffee mug. Setting the mood, you know.
Pre-requisites
Well, before we get going, let’s make sure we are all on the same page. Here are a couple of things you should be familiar of:
First, the general stages of a compiler, namely Lexical Analysis, Syntax Analysis, Semantic Analysis, Code generation, and Optimization. You can read more about these here.
Second, regular expressions and grammar. Read what a programming language grammar is on this page and about regular expressions here.
Lex and Yacc
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://res.cloudinary.com/practicaldev/image/fetch/s--EfcvKmkJ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_800/https://cdn-images-1.medium.com/max/11232/0%2AjSNKHS3Sc6R5tb2U)
You also need Lex and Yacc installed on your OS. A short guide on using these tools can be read here: https://arcb.csc.ncsu.edu/~mueller/codeopt/codeopt00/y_man.pdf.
The Flow
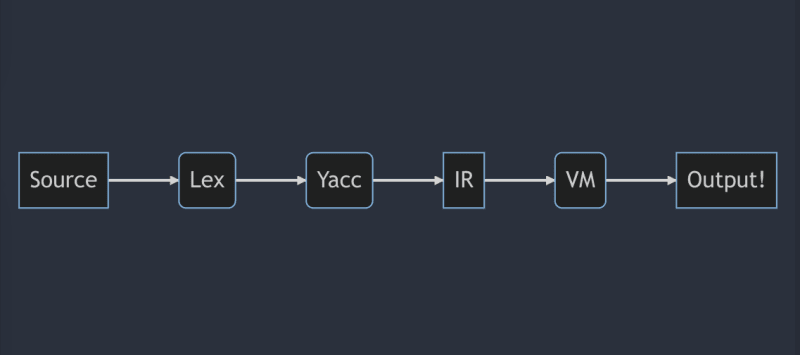
Here is the structure of the compiler. The frontend phase contains Lex and Yacc, which generates the Intermediate Representation in the form of Three Address Code and passes it over to the backend. The backend phase then takes the IR and executes it. We can put the optimisation and machine code generation phases here.
Actually, Yacc calls upon the lexer generated by Lex to tokenize the input stream.
yylex()is called repeatedly byyyparseto get the next token and determine what action to perform based on the grammar. We will delve deeper into this process in the next part of the series.
Lex
Lex is a program that generates scanners, also known as tokenizers, that recognise text lexical patterns. Lex is commonly used with the yacc parser generator.
You can say that Lex is a glorious Regex Engine. Getting a bit fancy, Lex is a paragon of virtuosity in the world of regex engines, but its prowess extends far beyond mere pattern matching. In fact, this powerful tool boasts a plethora of additional features that make it a revered asset in the realm of lexical analysis.
There are other alternatives to lex and yacc now, though, like ANTLR or other parser generators and parser combinators. This stackoverflow answer describes the differences between the two.
Lex takes in a specification file and produces C code that matches the regexes in the input file and performs actions according to the string matched. You can write C code in the input file that will be directly copied to the output file.
The specification file defines the rules for matching the input text. This file consists of three sections: definitions, rules, and user code. You can declare variables, macros, and regular expressions in the definitions section. The rules section is where you specify the patterns to match and the actions to perform when a match is found. In the user code section, you can write any additional C code you need for your scanner.
definitions
%%
rules
%%
user code
Since this is not a Lex guide, I won’t go into further details and features of Lex. Check out this flex manual; it has excellent examples and explanations.
Tokens
We need tokens, but what are they?

The figure above shows the tokens for a statement int arr[] = {1};
In short, tokens break the code into symbols, identifiers and literals (like numbers and strings) while ignoring comments and whitespace.
How many tokens will the following line be split into?
char str[5] = "abcd";
Answer: 8
Token Types
Each token has a token type. This type represents what class the token belongs to. A class can be as broad as a keyword. The substring of the source code that the token represents is called its lexeme. Thus, the lexeme of a number type token will be, for example, the string 1.23 . The lexeme of a keyword is the keyword itself.
Although Lex is used to tokenize the source, the tokens are declared in the Yacc file. Create a file named parser.y to write the token types.
No need to panic if you don’t know Yacc! Stick around for the next part where we will dive into the finer details. Or if you are bold and impatient enough, here is a handy starting point.
Every token in Yacc has a *value *associated with it. For an integer, the value is the integer value. This is stored in the yylval variable that is declared in the lex file.
Since we need to deal with a variety of Token values (integer, floating, character, strings), we define a union as the yylval datatype. This is done using the %union command in Yacc.
/* File: parser.y */
%{
#include <stdio.h>
#include <stdlib.h>
char *currentFileName;
extern int lineno, col;
int yyerror(char *s);
int yylex();
%}
%union {
int iValue;
float fValue;
char* sValue;
IdStruct id;
char cValue;
};
/* Keywords */
%token <iValue> K_INT K_FLOAT K_CHAR
%token FOR WHILE ELSE IF SWITCH CASE RETURN CONTINUE BREAK DEFAULT
/* Literals */
%token <iValue> INTEGER
%token <fValue> FLOAT
%token <cValue> CHARACTER
%token <sValue> STRING
/* Variables and functions */
%token <id> IDENTIFIER
/* Operators && || >= <= == != */
%token AND OR GE LE EQ NE
/* Other operators are returned as ASCII */
/* End of file token */
%token EOF_TOKEN
%%
/* Dummy grammar */
program: IDENTIFIER;
%%
// Error routine
int yyerror(char *s){
exit(1);
return 1;
}
As evident as it can be, the %token defines the tokens in the parser. The token type is specified in the angled brackets, referring to one of the variables from the %union declaration.
Yacc calls the function
yyerroron encountering a parsing error. You can read more about theseyy-functions here.
You should have noticed the identifier variable is id with a type IdStruct. This struct is defined in the symbol.h file and looks like this:
// File: symbol.h
#ifndef __SYMBOL
#define __SYMBOL
// Stores the coordinate in source file
typedef struct
{
// Length is for an expression
unsigned int line, col, length;
} Coordinate;
// Token type for an identifier
typedef struct
{
Coordinate src; // used for error reporting
char *name; //copied string (pointer)
} IdStruct;
#endif
Yacc generates a header file named y.tab.h with the declared tokens as members of an enumeration. To generate this header file, run yacc -d parser.y.
tokenizer.l
Let’s get started on our tokenizer. This will chop up our source code into tokens defined earlier and pass them over to the parser. The parser then uses these tokens to generate the parse tree according to the grammar.
First, we begin with the definitions section of the specification file.
/* tokenizer.l */
%{
#include <stdio.h>
#include <string.h>
#include <math.h>
#include <stdlib.h>
#include "symbol.h"
#include "y.tab.h"
#define MAX_STR_CONST 1000
#define yyterminate() return EOF_TOKEN
/* YY_USER_ACTION is called after
matching a pattern and before executing the action */
#define YY_USER_ACTION \
col += yyleng;
extern char *currentFileName;
int col = 1; //track the current column
int lineno = 1;
int yyerror(char* s);
%}
MAX_STR_CONST is the max length of a string literal in Mini C. yyterminate() defines the function to terminate the lexer. This returns the End Of File token.
Next, define a few helper regex patterns:
%}
alpha [a-zA-Z]
alphanum [a-zA-Z0-9]
digit [0-9]
nonzero [1-9]
%%
This completes the definitions part. We will return here to add a few more things to handle strings and comments, but that’s for later.
Keywords and Symbols
Welcome to the Rules section! Here we lay out our tokenizer building brick by brick.
Since yylval is a union defined by %union in parser.y , we have to carefully set the right field of the union.
Keywords and symbols are very simple: just return what you match. Here are the match patterns:
%%
char string_buf[MAX_STR_CONST]; /* to store strings */
char *string_buf_ptr;
/* Keywords */
"int" {return K_INT;}
"float" {return K_FLOAT;}
"char" {return K_CHAR;}
"for" {return FOR;}
"while" {return WHILE;}
"else" {return ELSE;}
"if" {return IF;}
"switch" {return SWITCH;}
"case" {return CASE;}
"return" {return RETURN;}
"continue" {return CONTINUE;}
"break" {return BREAK;}
"default" {return DEFAULT;}
/* Symbols
Return the first character of the matched string
*/
[-+*/%] return *yytext;
[;,:()] return *yytext;
[\{\}\[\]] return *yytext;
[=!<>] return *yytext;
/* Lex always executes the longest match action */
"==" {return EQ;}
">=" {return GE;}
"<=" {return LE;}
"!=" {return NE;}
"&&" {return AND;}
"||" {return OR;}
On calling yylex() , lex will go through these patterns and execute the action for the pattern that matches the longest string.
Numbers and Characters
Here is the regex pattern to match integers and floating numbers:
/* Integers */
0 {yylval.iValue = 0; return INTEGER;}
{nonzero}({digit})*([eE][-+]?[0-9]+)? {
yylval.iValue = (int)round(atof(yytext)); return INTEGER;}
/* Floats */
{nonzero}({digit})*"."({digit})*([eE][-+]?[0-9]+)? {
yylval.fValue = atof(yytext); return FLOAT;}
/* Characters */
"\'"({alpha}|{digit})"\'" {yylval.cValue = yytext[1]; return CHARACTER;}
The action part sets the iValue or fValue field accordingly and returns the type of token ( INTEGER or FLOAT )
yytextpoints to the current matched substring of the source string. It has to be parsed into an integer or floating point number using the standard library functionsatoi(argument to int) andatof
Identifiers
An identifier token will capture the identifier string and pass it to the parser. This captured string will stick around throughout the lifetime of the compiler.
/* Identifiers */
(_|{alpha})((_|{alphanum}))* {
yylval.id.name = malloc(strlen(yytext)+1);
yylval.id.src.line = lineno;
yylval.id.src.col = col - yyleng;
// yylval.name = malloc(strlen(yytext)+1);
strcpy(yylval.id.name, yytext);
// strcpy(yylval.name, yytext);
return IDENTIFIER;
}
Strings
For strings, we use start conditions in lex. To define a start condition, place the definition in the definitions section.
%x str
%x comment single_line_comment /* for comments */
These are exclusive start conditions, meaning that other rules won’t be matched when these conditions are active. To parse strings, we BEGIN the str condition on seeing the first " and keep adding characters to the buffer till the closing " is not seen.
/* Strings*/
\" { string_buf_ptr = string_buf; BEGIN(str);}
<str>\" {
BEGIN(INITIAL);
*string_buf_ptr = '\0';
yylval.sValue = (char*)malloc(strlen(string_buf)+1);
strcpy(yylval.sValue, string_buf);
return STRING;
}
<str>\n {yyerror("Unterminated string.\n"); return ERROR;}
<str>\\n {*string_buf_ptr++ = '\n';}
<str>[^\n] {
*string_buf_ptr++ = *yytext;
}
There is no support for escape characters except
\n, but if you are feeling adventurous enough, have a go at adding other escape sequences like\"
Comments
Comments are treated as whitespace and ignored by the tokenizer. Again, we use start conditions to ignore characters inside the comment.
/* Comments*/
"//" BEGIN(single_line_comment);
<single_line_comment>"\n" {col = 1; lineno++; BEGIN(INITIAL);}
<single_line_comment><<EOF>> {BEGIN(INITIAL); return EOF_TOKEN;}
<single_line_comment>[^\n]+ ;
"/*" BEGIN(comment);
<comment>"\n" {col = 1; lineno++;}
<comment>"*/" {BEGIN(INITIAL);}
<comment><<EOF>> {yyerror("Unclosed comment found\n");}
<comment>. ;
Whitespace
It’s sad, but we have to do it. Ignore whitespace. And raise an error on any other character.
/* Whitespace */
[ \t\r] ;
\n {col = 1; lineno++;}
. {yyerror("Error: Invalid character"); return ERROR;}
Strapping with Main
Almost done! Wrap up the tokenizer by closing the rules section like so:
%%
int yywrap(){
yyterminate();
return EOF_TOKEN;
}
And create a file main.c that will read tokens from a file:
//File main.c
#include <stdio.h>
#include <stdlib.h>
#include "symbol.h"
#include "y.tab.h"
// The current line number.
// This is from tokenizer.l.
extern int lineno;
extern FILE *yyin;
// Current token's lexeme
extern char *yytext;
// The source file name
extern char *currentFileName;
// From lex.yy.c, returns the next token.
// Ends with EOF
int yylex();
int main()
{
yyin = fopen("input.txt", "r");
int token;
while ((token = yylex()) != EOF_TOKEN)
{
printf("Token: %d: '%s'\n", token, yytext);
}
return 0;
}
Create a file input.txt and enter your sample program.
// input.txt
int a = 3;
while(a){
printf("%d", a);
}
Compile by running:
> yacc -d parser.y
> lex tokenizer.l
> gcc y.tab.c lex.yy.c main.c -ll -lm
> ./a.out
And there’s your output!
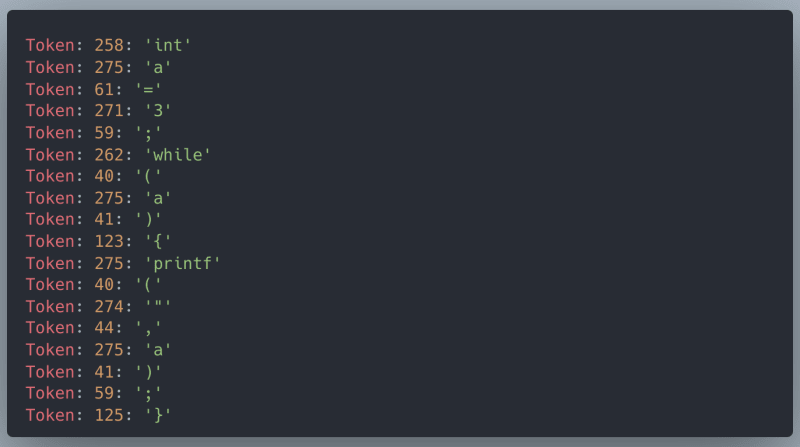
Conclusion
Awesome job, you now have your own tokenizer!
Although I have used very little of what Lex offers, it is worth going through one of the links above (find them!😄) and maybe adding or modifying a few tokens yourself.
In the next part, we shall write the grammar and be able to determine if the given program has valid syntax or not. Till then, happy coding!
I hope you enjoyed this post and learned something new. If you did, please show support and hit that react button. It really helps me out and motivates me to keep writing more awesome content for you. Thanks for reading!
Final Code
The complete source code of the compiler is available on GitHub.
I have added a few more functions to report errors in the source program. When an invalid character is detected, yyerror calls the point_at_in_line function with the current column and line numbers. This reads the source file and prints the given line and column number in a pleasing manner.





Top comments (0)