
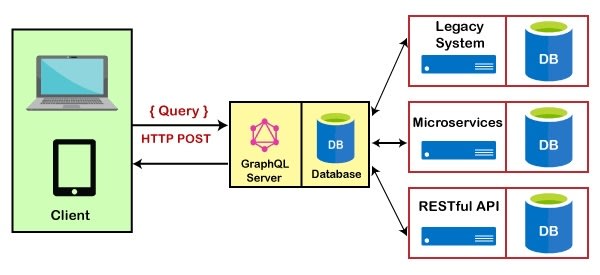
A couple of days ago I wrote an article here called GraphQL a hot smoking pile of garbage. In the article I was arguing that GraphQL was nothing but "JSON based SQL injection attacks". Everybody arguing against me told me "this is not how GraphQL is being used, you need to study how it's used, your opinion is based upon faulty assumptions, etc". Well, take a look at the above architectural sketch and feel free to explain. The above image basically proves how GraphQL is a security disaster.
The above architectural sketch is one of the primary use cases used by the second largest GraphQL service provider in the world. I don't even want to disclose their name, because of security reasons, since the above architectural sketch is basically a direct implementation of the problems I was illuminating in my previous article.
The service provider have roughly 35,000 stars on GitHub, they have 60 million dollars in VC fundings, and they're not even the largest service provider in this space. There's another similar company with 75,000 stars on GitHub, that encourages their users to do the same. And according to a website I saw the other day, there are 88 alternatives to the largest company, and 54 alternative to the second largest company in this domain.
My article wasn't written for Facebook or GitHub. I have no doubts that both Facebook and GitHub knows how to correctly apply GraphQL. My article was written for the rest of the world. The 98% of software developers applying GraphQL, believing it's an "easy alternative to HTTP REST and business logic on the server".
The above use case published by the service provider is for a FinTech company, with 3,500 users. I can only pray to (insert deity of choice) that they're not PCI compliant. Facts are ...
GraphQL a security disaster
If you need an alternative that's secure by default, feel free to register a free CRUD API generator cloudlet here.

Top comments (12)
@joelbonetr
Combined these two vendors has 120,000 stars on GitHub ... :/
And they have 130 similar copy cat companies delivering similar products ... :/
My guess is that 98% of all GraphQL implementations are done like the above sketch illustrates ...
Hi Thomas, GraphQL schemas for a service are specified using what's known as the GraphQL SDL (Schema Definition Language), Schema-First methodology is also the most common thingy in this context.
GraphQL has 3 categories of operations, i'm adding them with the http equivalent to showcase:
In each type of request that you want to handle, there are different parts. A definition on what it contains and a definition on what it returns.
The operations are performed through Resolvers, see example below:
It's up to you how to resolve each request. It's usually one of two things:
Request -> Resolver -> Req Validation -> ORMor
Request -> Resolver -> Endpoint (which can be a REST req and this endpoint will also implement a Req Validation and a call to an ORM)Of course the ORM is optional but as it's the most common I'm sticking with this flow.
Please note that GraphQL itself it's just a definition (which is the model you want to expose, how you are going to resolve the requests and what will you return as response) thus it has nothing to do with security alone.
The security, as well as you do on a regular http endpoint, is up to you. The framework, libs, handlers and functions need to be arranged in a way that prevent security vulnerabilities. Usually the framework and the ORM have standard functions/methods to deal with common security concerns, you can use dedicated libs for each topic if you prefer so.
GraphQL is not "an easy alternative to HTTP", it has it's pros and cons (yet most of them have been tackled by now) like any other tech and yes, both have a common point in utility (resolve requests through TCP/UDP, multiplexed or not). Depending on what you need to build it will be easier or harder, more or less convenient or a better or worse choice using a tech or another.
I don't want to convert this comment in an entire post explaining what GraphQL is and how it works, what architectures are suitable for it, what it does and what it don't and going to the detail but I assume that with the information yet provided it should suffice to showcase.
You're probably 100% perfectly correct. However, every single person arguing against me said "this is not the way GraphQL is intended to be used", at which point I said "this is how 98% of the world is using GraphQL". We've now got proof of that I was right ... ;)
Me being right of course, doesn't imply you're not right ...
BTW, having schemas is a terrible idea, since it moves the important parts out of the parts where the action is. We had similar problems with Hibernate and nHibernate before they were able to create "fluent APIs", with AOP type of syntax, coupling the "configuration" with the code, making it easier to see things and maintain ...
The same way when you create a RESTful endpoint you define the request handlers (for each http method) and then you add the validations and the resolvers for it, it's not so different.
Generally speaking, those are different topics and maybe GraphQL could work well together with your CRUD generator (that's another topic to discuss) as Gateway to provide an easy I/O point (optional) for your programmatically generated CRUDs.
I don't see GraphQL as competitor on your field but a "nice to have", as it's explained above, GraphQL does not generate any CRUD itself, it just provides a standardized way to handle client requests through an SDL and quite useful notations, rather than fighting with OpenAPI specs trying to define something that works not only for now but for the future. See GraphQL Directives as example.
If you understand the schema as and it's workflow as the place where the action is you may change your mind 😁
Take it a try, do some different PoCs and maybe you will find a way to incorporate GraphQL in your system, being optional or not at the end it's TBD.
Everything on this topic can be summarized in a sentence; It's not what reaches your server but how do you handle it.
I once had a dev guy once spending 2 weeks trying to configure Pulsar. We've known since RoR days the following ...
Thx, I don't disagree with you really, and you've got some great points - However, the way 98% of the world for all practical concerns is using GraphQL is the exact opposite that commenters were commenting on my OP about ... ;)
If you don't believe me, look at the architectural sketch on the top of this article, and go back to my OP and see peoples' arguments ...
I've never saw a production ready GraphQL project whose resolvers are attached to a database model directly without security layers. That's because GraphQL itself doesn't provide a way to do that, to reach this you need to code your resolvers in that specific way.
On the other hand, if you use GraphQL just as gateway (which is quite convenient), you don't need to secure your GraphQL for each resolver, the resolver itself (another endpoint) will catch the responsibility for that (just like any other GW does).
Nevertheless if it's the case, it's convenient as well to handle Auth in the gateway so you avoid requests to other endpoints if the request will fail for that reason anyway.
TLDR;
The schema you provided:
States just that. The Backend, that can be GraphQL or not, handles the request and the Authentication.
Then resolve each request with whatever is needed (that include integrations with other services, being third party or not).
In this specific case, the backend seems a single service without pieces in between the client and the backend itself. It's OK if it works for the target.
You can find architectural schemas in many different system designs using GraphQL:
It can be a monolithic block in which you'll need to handle the security:

It can be a GraphQL gateway and the security and the DB access it's used in each stand-alone service:

Maybe a combination of both:
And tones of options more, depending on the complexity of the system.
You can add proxies, load balancers, more than one gateway (BFF architecture), services and/or microservices that are using GraphQL themselves, others using REST, others using gRPC and so on.
Also you can have a monolith that exposes a GraphQL I/O, another one using REST and another one using gRPC so your thingy can be integrated with most clients out there and they can use their preferred method. The same way you can have a services or microservices architecture and provide 2, 3... 25 gateways if you want.
At the end, GraphQL it's just a piece of the entire puzzle, that you can use or not.
It's up to you to analyse and define what system design suits best for the target of your App (or a given product line or a product adaptation for a given market niche) and which tools are needed, convenient and nice to have so you can plan your roadmap better and give your clients the best possible service.
Indeed I don't get this one. Any API that provides direct read/write access to a database is stupid. That stupidity can be implemented with GraphQL or REST or SOAP or whatever, the technology doesn't matter.
If you want to rename GraphQL, statically typed REST is the right answer.
When the client is constructing the queries, it's (almost) impossible to prevent it from constructing malicious queries. The client is "user land", implying anybody with a Postman account can create queries. Even if you get all authorisation objects correctly applied towards the different tables you've got, you're still left with problems such as those originating from batch queries, where your GraphQL server ends up "DOS attacking" your database, creating a "query storm", plus a bajillion additional problems.
There are ways to secure GraphQL, by for instance not allowing the client to create queries, but rather constructing the queries in your middleware, and exposing statically types endpoints to the client. The problem is that most aren't using GraphQL this way, they see GraphQL and start thinking; "Cool, 'server less'", and implements all business logic on the client, allowing for creating queries in "client land".
The second problem is that even if you're able to somehow completely secure GQL, you're still ending up with a solution that for all practical concerns moves all business logic into client space. Typically the same API have multiple clients. You're now risking that each client implements its business logic differently, and/or users bypassing your business logic with their Postman accounts, resulting in "bad data".
The problem with using GraphQL this way is that it reduces your middleware to a "fancy database thing". It hence solves nothing really, but only "moves" the problem to an outer layer.
Most people commenting here claims they're not using GraphQL this way, as in exposing the query building directly to the client. This is probably true. However, most people commenting here aren't representative of how GraphQL is used by most developers.
However, it's the idea of GraphQL that's the problem, because if you give people a big shotgun, most people are going to shoot themselves in their legs. As a library developer I've learned one thing, which is to restrict usage of a library as much as possible. Even though I can perfectly apply the library, most others cannot, and will abuse it in ways it wasn't intended to be used ...
The above screenshot has a GraphQL vendor in the parts which are censored. This implies that the only thing that's between the database and the frontend client is a GraphQL server. This is the only product this particular vendor happens to have, and we must hence assume 98% of its clients are using GraphQL like this. To further emphasise that, realise that this particular vendor is using this as their "best practice use case" in their marketing. This particular vendor has 35,000+ stars on GitHub. There's another similar vendor with 70,000+ stars on GitHub, delivering the exact same product ...
The architectural sketch above is a use case from a FinTech provider. This company have 3,500 users. One of them might be you. If they're PCI compliant, they've got your credit card information. I consider this a really big deal ... ;)
Here's the first paragraph from GraphQL's primary website. They're basically summing up the problem a hundred times better than I can do myself.
If you use GraphQL like GraphQL's website tells you to do, you're in a "security disaster land", because everyone with a Postman account can construct Graph queries you hadn't anticipated ...
It's basically one step up from allowing the client to pass in raw SQL queries ...
We agree that's stupid.
The issue is that it's hard to discuss if we use the same word for two completely different concepts.
There is "GraphQL A" which means "giving direct acess to the database using graphql as an excuse".
Then there is "GraphQL B" which means "the alternative to rest from facebook that actually has little to do with graphs but is important nonetheless because it introduces a proper contract between backend and frontend based on static types" (the usual definition).
Not in GraphQL B. It's exactly as easy or hard as in REST, because graphql is mainly rest with static types, and static types are not a relevant factor here. Like I'm litteraly using the same code to serve an endpoint via Rest and GraphQL.
In GraphQL A yes.
For GraphQL B, what changes is that it gives the fronend some reasonable flexibility such as not receiving the fields it doesn't need, or grouping multiple requests in one http query. The business logic is still in the backend though, very reasonable.
GraphLQ B has a small difference with REST here, because the attacker could do that in one graphql query instead of multiple rest queries. But it isn't that big a difference, writing a script that DDOS with multiple REST queries is super easy and super common too.
So you have to implement rate-limiting and batch loading either way.
The idea of GraphQL B is sound, it doesn't give any shotgun that was not there before but it does gives a very useful tool: a contract betwen front and back with static types.
Companies hyping GraphQL A, companies that provides or uses an automagical "direct access to your postgres database via graphql" do however and deserve to be shunned, and the more the better. Here I have no problem agreeing with you.
The problem is that most companies are using this version ... :/
And the reason is because it's literally how GraphQL is being marketed. Both by the creators of GraphQL, and hundreds of companies setting up companies being service providers providing this as their sole service.
I agree, but see my comment above ...
Most developers don't see the difference. The particular vendor you're talking about is according to their own account "the fastest growing open source project on the planet". They've got 70,000+ stars on GitHub ...
To create an omelet you sometimes have to break a couple of eggs. Hopefully, people using such tech will search for GraphQL the next time before they start using it, and find this article, saving them from security holes the size of Niagara falls ...
I don't particularly like graphql myself, I much prefer rest schemas with prescribed models.
On the other hand, after reading this and your previous article on the topic, and your replies to people in said articles, it certainly comes across like you're a "my way or the highway" kinda person with a big ego who loves pointing out how many likes and follows they have.
Disappointing because I was hoping for an unbiased argument about graphql with well-documented evidence that supported my initial opinion.
You could try to argue factually instead of doing an ad hominem ...?
Just sayin' ... :/
It would certainly increase your credibility ...
I would at least ensure we had something to actually discuss at least ... ^_^