Authored by Dhruba Borthakur
Introduction to Operational Analytics
Operational analytics is a very specific term for a type of analytics which focuses on improving existing operations. This type of analytics, like others, involves the use of various data mining and data aggregation tools to get more transparent information for business planning. The main characteristic that distinguishes operational analytics from other types of analytics is that it is “analytics on the fly," which means that signals emanating from the various parts of a business are processed in real-time to feed back into instant decision making for the business. Some people refer to this as "continuous analytics," which is another way to emphasize the continuous digital feedback loop that can exist from one part of the business to others.
Operational analytics allows you to process various types of information from different sources and then decide what to do next: what action to take, whom to talk to, what immediate plans to make. This form of analytics has become popular with the digitization trend in almost all industry verticals, because it is digitization that furnishes the data needed for operational decision-making.
Let's discuss some examples of operational analytics. Let's say that you are a software game developer and you want your game to automatically upsell a certain feature of your game depending on the gamer’s playing habits and the current state of all the players in the current game. This is an operational analytics query because it allows the game developer to make instant decisions based on analysis of current events.
Back in the day, product managers used to do a lot manual work, talking to customers, asking them how they use the product, what features in the product slow them down, etc. In the age of operational analytics, a product manager can gather all these answers by querying data that records usage patterns from the product’s user base; and he or she can immediately feed that information back to make the product better.
Similarly, in the case of marketing analytics, a marketing manager would use to organize a few focus groups, try out a few experiments based on their own creativity and then implement them. Depending on the results of experimentation, they would then decide what to do next. An experiment may take weeks or months. We are now seeing the rise of the "marketing engineer," a person who is well-versed in using data systems. These marketing engineers can run multiple experiments at once, gather results from experiements in the form of data, terminate the ineffective experiments and nurture the ones that work, all through the use of data-based software systems. The more experiments they can run and the quicker the turnaround times of results, the better their effectiveness in marketing their product. This an another form of operational analytics.
Definition of Operational Analytics Processing
An operational analytics system helps you make instant decisions from reams of real-time data. You collect new data from your data sources and they all stream into your operational data engine. Your user-facing interactive apps query the same data engine to fetch insights from your data set in real time, and you then use that intelligence to provide a better user experience to your users.
Ah, you might say that you have seen this "beast" before. In fact, you might be very, very familiar with it from close quarters as well... it encompasses your data pipeline that sources data from various sources, deposits it into your data lake or data warehouse, runs various transformations to extract insights, and then parks those nuggets of information in a key-value store for fast retrieval by your interactive user-facing applications. And you would be absolutely right in your analysis: an equivalent engine that has the entire set of these above functions is an operational analytics processing system!
The definition of an operational analytics processing engine can be expressed in the form of the following six propositions:
- Complex queries : Support for queries like joins, aggregations, sorting, relevance, etc.
- Low data latency : An update to any data record is visible in query results in under than a few seconds.
- Low query latency : A simple search query returns in under a few milliseconds.
- High query volume : Able to serve at least a few hundred concurrent queries per second.
- Live sync with data sources : Ability to keep itself in sync with various external sources without having to write external scripts. This can be done via change-data-capture of an external database, or by tailing streaming data sources.
- Mixed types : Allows values of different types in the same column. This is needed to be able to ingest new data without needing to clean them at write time.
Let’s discuss each of the above propositions in greater detail and discuss why each of the above features is necessary for an operational analytics processing engine.
Proposition 1: Complex queries
A database, in any traditional sense, allows the application to express complex data operations in a declarative way. This allows the application developer to not have to explicitly understand data access patterns, data optimizations, etc. and frees him/her to focus on the application logic. The database would support filtering, sorting, aggregations, etc. to empower the application to process data efficiently and quickly. The database would support joins across two or more data sets so that an application could combine the information from multiple sources to extract intelligence from them.
For example, SQL, HiveQL, KSQL etc. provide declarative methods to express complex data operations on data sets. They have varying expressive powers: SQL supports full joins whereas KSQL does not.
Proposition 2: Low data latency
An operational analytics database, unlike a transactional database, does not need to support transactions. The applications that use this type of a database use it to store streams of incoming data; they do not use the database to record transactions. The incoming data rate is bursty and unpredictable. The database is optimized for high-throughout writes and supports an eventual consistency model where newly written data becomes visible in a query within a few seconds at most.
Proposition 3: Low Latency queries
An operational analytics database is able to respond to queries quickly. In this respect, it is very similar to transactional databases like Oracle, PostgreSQL, etc. It is optimized for low-latency queries rather than throughput. Simple queries finish in a few milliseconds while complex queries scale out to finish quickly as well. This is one of the basic requirements to be able to power any interactive application.
Proposition 4: High query volume
A user-facing application typically makes many queries in parallel, especially when multiple users are using the application simultaneously. For example, a gaming application might have many users playing the same game at the same time. A fraud detection application might be processing multiple transactions from different users simultaneously and might need to fetch insights about each of these users in parallel. An operational analytics database is capable of supporting a high query rate, ranging from tens of queries per second (e.g. live dashboard) to thousands of queries per second (e.g. an online mobile app).
Proposition 5: Live sync with data sources
An online analytics database allows you to automatically and continuously sync data from multiple external data sources. Without this feature, you will create yet another data silo that is difficult to maintain and babysit.
You have your own system-of-truth databases, which could be Oracle or DynamoDB, where you do your transactions, and you have event logs in Kafka; but you need a single place where you want to bring in all these data sets and combine them to generate insights. The operational analytics database has built-in mechanisms to ingest data from a variety of data sources and automatically sync them into the database. It may use change-data-capture to continuously update itself from upstream data sources.
Proposition 6: Mixed types
An analytics system is super useful when it is able to store two or more different types of objects in the same column. Without this feature, you would have to clean up the event stream before you can write it to the database. An analytics system can provide low data latency only if cleaning requirements when new data arrives is reduced to a minimum. Thus, an operational analytics database has the capability to store objects of mixed types within the same column.
The six above characteristics are unique to an OPerational Analytics Processing (OPAP) system.
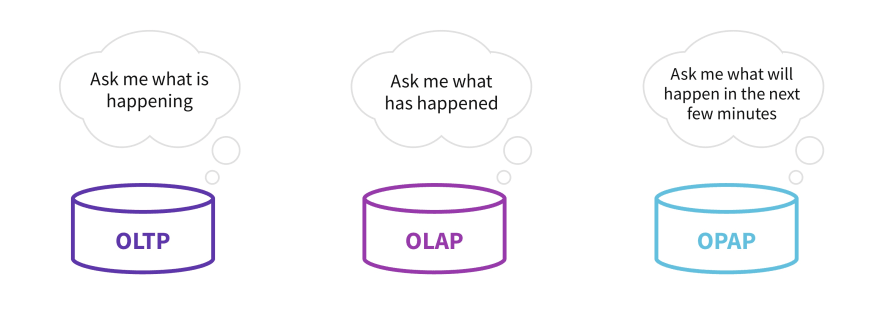
Architectural Uniqueness of an OPAP System
The Database LOG
The Database is the LOG; it durably stores data. It is the "D" in ACID systems. Let’s analyze the three types of data processing systems as far as their LOG is concerned.
The primary use of an OLTP system is to guarantee some forms of strong consistency between updates and reads. In these cases the LOG is behind the database server(s) that serves queries. For example, an OLTP system like PostgreSQL has a database server; updates arrive at the database server, which then writes it to the LOG. Similarly, Amazon Aurora's database server(s) receives new writes, appends transactional information (like sequence number, transaction number, etc.) to the write and then persists it in the LOG. On both of these cases, the LOG is hidden behind the transaction engine because the LOG needs to store metadata about the transaction.

Similarly, many OLAP systems support some basic form of transactions as well. For example, the OLAP Snowflake Data Warehouse explicitly states that it is designed for bulk updates and trickle inserts (see Section 3.3.2 titled Concurrency Control). They use a copy-on-write approach for entire datafiles and a global key-value store as the LOG. The database servers fronting the LOG means that streaming write rates are only as fast as the database servers can handle.
On the other hand, an OPAP system’s primary goal is to support a high update rate and low query latency. An OPAP system does not have the concept of a transaction. As such, an OPAP system has the LOG in front of the database servers, the reason being that the log is needed only for durability. Making the database be fronted by the log is advantageous: the log can serve as a buffer for large write volumes in the face of sudden bursty write storms. A log can support a much higher write rate because it is optimized for writes and not for random reads.
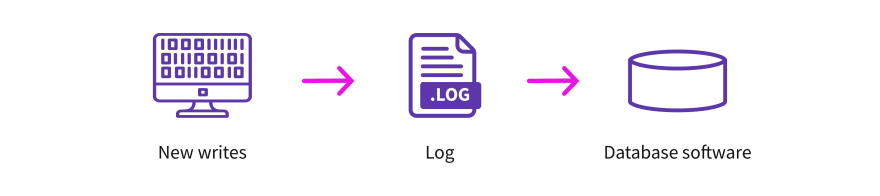
Type binding at query time and not at write time
OLAP databases associate a fixed type for every column in the database. This means that every value stored in that column conforms to the given type. The database checks for conformity when a new record is written to the database. If a field of a new record does not adhere to the specified type of the column, the record is either discarded or a failure is signaled. To avoid these types of errors, OLAP database are fronted by a data pipeline that cleans and validates every new record before it is inserted to the database.
For example, let’s say that a database has a column called ‘zipcode’. We know that zip code are integers in the US while zipcodes in the UK can have both letters and digits. In an OLAP database, we have to convert both of these to the ‘string’ type before we can store them in the same column. But once we store them as strings in the database, we lose the ability to make integer comparisons as part of the query on this column. For example, a query of the type select count(*) from table where zipcode > 1000 will throw an error because we are doing an integral range check but the column type is a string.
On the other hand an OPAP database does not have a fixed type for every column in the database. Instead, the type is associated with every individual value stored in the column. The ‘zipcode’ field in an OPAP database is capable of storing both these types of records in the same column without losing the type information of every field.
Going further, for the above query select count(*) from table where zipcode > 1000, the database could inspect and match only those values in the column that are integers and return a valid result set. Similarly, a query select count(*) from table where zipcode=’NW89EU’ could match only those records that have a value of type ‘string’ and return a valid result set.
Thus, an OPAP database can support a strong schema, but enforce the schema binding at query time rather than at data insertion time. This is what is termed strong dynamic typing.
Comparisons with Other Data Systems
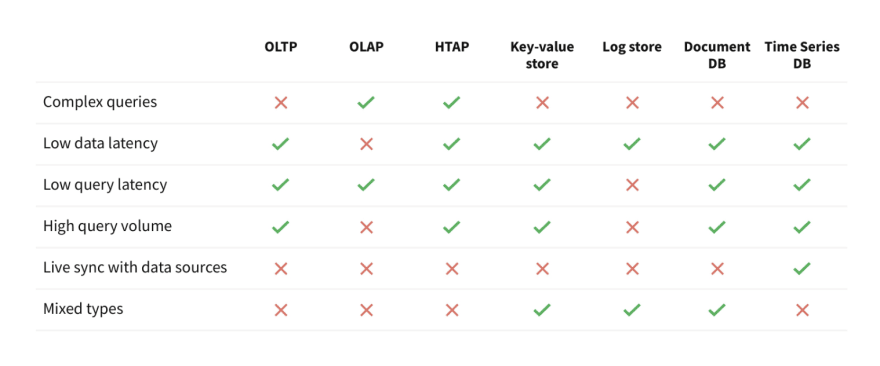
Now that we understand the requirements of an OPAP database, let’s compare and contrast other existing data solutions. In particular, let’s compare its features with an OLTP database, an OLAP data warehouse, an HTAP database, a key-value database, a distributed logging system, a document database and a time-series database. These are some of the popular systems that are in use today.
Compare with an OLTP database
An OLTP system is used to process transactions. Typical examples of transactional systems are Oracle, Spanner, PostgreSQL, etc. The systems are designed for low-latency updates and inserts, and these writes are across failure domains so that the writes are durable. The primary design focus of these systems is to not lose a single update and to make it durable. A single query typically processes a few kilobytes of data at most. They can sustain a high query volume, but unlike an OPAP system, a single query is not expected to process megabytes or gigabytes of data in milliseconds.
Compare with an OLAP data warehouse
An OLAP data warehouse can process very complex queries on large datasets and is similar to an OPAP system in this regard. Examples of OLAP data warehouses are Amazon Redshift and Snowflake. But this is where the similarity ends. An OLAP system is designed for overall system throughput whereas OPAP is designed for the lowest of query latencies. An OLAP data warehouse can have an overall high write rate, but unlike a OPAP system, writes are batched and inserted into the database periodically. An OLAP database requires a strict schema at data insertion time, which essentially means that schema binding happens at data write time. On the other hand, an OPAP database natively understands semi-structured schema (JSON, XML, etc.) and the strict schema binding occurs at query time. An OLAP warehouse supports a low number of concurrent queries (e.g. Amazon Redshift supports up to 50 concurrent queries), whereas a OPAP system can scale to support large numbers of concurrent queries.
Compare with an HTAP database
An HTAP database is a mix of both OLTP and OLAP systems. This means that the differences mentioned in the above two paragraphs apply to HTAP systems as well. Typical HTAP systems include SAP HANA and MemSQL.
Compare with a key-value store
Key-Value (KV) stores are known for speed. Typical examples of KV stores are Cassandra and HBase. They provide low latency and high concurrency but this is where the similarity with OPAP ends. KV stores do not support complex queries like joins, sorting, aggregations, etc. Also, they are data silos because they do not support the auto-sync of data from external sources and thus violate Proposition 5.
Compare with a logging system
A log store is designed for high write volumes. It is suitable for writing a high volume of updates. Apache Kafka and Apache Samza are examples of logging systems. The updates reside in a log, which is not optimized for random reads. A logging system is good at windowing functions but does not support arbitrary complex queries across the entire data set.
Compare with a document database
A document database natively supports multiple data formats, typically JSON. Examples of a document database are MongoDB, Couchbase and Elasticsearch. Queries are low latency and can have high concurrency but they do not support complex queries like joins, sorting and aggregations. These databases do not support automatic ways to sync new data from external sources, thus violating Proposition 5.
Compare with a time-series database
A time-series database is a specialized operational analytics database. Queries are low latency and it can support high concurrency of queries. Examples of time-series databases are Druid, InfluxDB and TimescaleDB. It can support a complex aggregations on one dimension and that dimension is ‘time’. On the other hand, an OPAP system can support complex aggregations on any data-dimension and not just on the ‘time’ dimension. Time series database are not designed to join two or more data sets whereas OPAP systems can join two or more datasets as part of a single query.
References
- Techopedia: https://www.techopedia.com/definition/29495/operational-analytics
- Andreessen Horowitz: https://a16z.com/2019/05/16/everyone-is-an-analyst-opportunities-in-operational-analytics/
- Forbes: https://www.forbes.com/sites/forbestechcouncil/2019/06/11/from-good-to-great-how-operational-analytics-can-give-businesses-a-real-time-edge/
- Gartner: https://www.gartner.com/en/newsroom/press-releases/2019-02-18-gartner-identifies-top-10-data-and-analytics-technolo
- Tech Republic: https://www.techrepublic.com/article/how-data-scientists-can-help-operational-analytics-succeed/
- Quora: https://www.quora.com/What-is-Operations-Analytics
- Rockset: https://www.rockset.com/

Top comments (0)