
Welcome to the third part of the "Image similarity search with pgvector" learning series!
In the previous articles, you learned how to describe vector embeddings and vector similarity search. You also used the multi-modal embeddings APIs of Azure AI Vision for generating embeddings for a collection of images of paintings.
Introduction
In this learning series, we will create a search system that lets users provide a text description or a reference image to find similar paintings. We have already generated vector embeddings for the images in our dataset using the multi-modal embeddings API of Azure AI Vision. In this post, we will use Azure Blob Storage to store the images and Azure Cosmos DB for PostgreSQL to store our vector embeddings using the pgvector extension. In the next tutorials, we will perform a similarity search on our embeddings.
The workflow is illustrated in the following image:
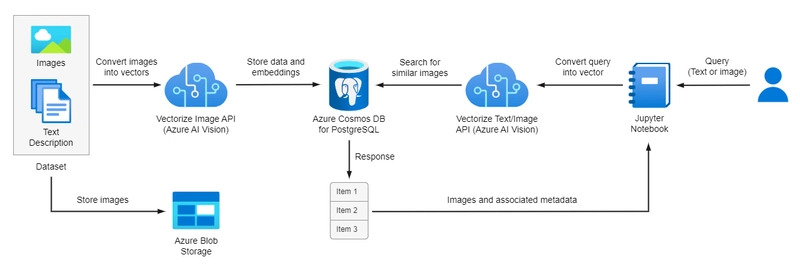
In this tutorial, you will learn how to:
- Upload images to an Azure Blob Storage container using the Python SDK.
- Activate the pgvector extension on Azure Cosmos DB for PostgreSQL.
- Store vector embeddings on an Azure Cosmos DB for PostgreSQL table.
Prerequisites
To proceed with this tutorial, ensure that you have the following prerequisites installed and configured:
- An Azure subscription - Create an Azure free account or an Azure for Students account.
- Python 3.10, Visual Studio Code, Jupyter Notebook, and Jupyter Extension for Visual Studio Code.
Set-up your working environment
In this guide, you'll learn how to upload a collection of paintings' images to an Azure Blob Storage container and insert vector embeddings into an Azure Cosmos DB for PostgreSQL table. The entire functional project is available in the GitHub repository. If you're keen on trying it out, just fork the repository and clone it to have it locally available.
Before running the scripts covered in this post, you should:
- Create a virtual environment and activate it.
-
Install the required Python packages using the following command:
pip install -r requirements.txt Create vector embeddings for a collection of images by running the scripts found in the data_processing directory.
Upload images to Azure Blob Storage
The code for uploading images to an Azure Blob Storage container can be found at data_upload/upload_images_to_blob.py.
Azure Blob Storage is a cloud storage service that is optimized for storing large amounts of unstructured data, such as images. It offers three types of resources:
- The storage account that contains all your Azure Storage data objects. Every object that is stored in Azure Storage is identified by a unique address.
- Containers in the storage account which are similar to directories in a file system.
- Blobs that are organized in the containers.
The following diagram illustrates the relationship between these resources:

Azure Blob Storage resources: storage account, container, and blobs. Image source: Azure Blob Storage Object model – Microsoft Docs
Create an Azure Storage account
- Open the Azure CLI.
-
Create an Azure Storage Account using the following command:
az storage account create --name account-name --resource-group your-group-name --location your-location --sku Standard_LRS --allow-blob-public-access true --min-tls-version TLS1_2
Upload images to an Azure Blob Storage container
The Azure Blob Storage client library for Python provides the following classes to manage blobs and containers:
-
BlobServiceClient: We will use theBlobServiceClientclass to interact with the Azure Storage account and create a container. -
ContainerClient: We will use theContainerClientclass to interact with our container and the blobs inside the container. -
BlobClient: We will use theBlobClientclass to upload a blob to our container.
The process of uploading our images to Azure Blob Storage can be summarized as follows:
- Create a new container to store our images.
- Retrieve the filenames of the images in the dataset.
- Upload the images in the container, utilizing multiple threads via the
ThreadPoolExecutorclass. Additionally, use thetqdmlibrary to display progress bars for better visualizing the image uploading process.
import os
import csv
import sys
from dotenv import load_dotenv
from azure.storage.blob import BlobServiceClient, ContainerClient, ContentSettings
from azure.core.exceptions import ResourceExistsError
from concurrent.futures import ThreadPoolExecutor
from tqdm import tqdm
# Constants
MAX_WORKERS = 4
IMAGE_FILE_CSV_COLUMN_NAME = "image_file"
# Directories
current_dir = os.path.dirname(os.path.realpath(__file__))
parent_dir = os.path.dirname(current_dir)
# Load environemt file
load_dotenv(os.path.join(parent_dir, ".env"), override=True)
# Azure Blob Storage credentials
blob_account_name = os.getenv("BLOB_ACCOUNT_NAME")
blob_account_key = os.getenv("BLOB_ACCOUNT_KEY")
blob_endpoint_suffix = os.getenv("BLOB_ENDPOINT_SUFFIX")
blob_connection_string = (
f"DefaultEndpointsProtocol=https;AccountName={blob_account_name};"
f"AccountKey={blob_account_key};EndpointSuffix={blob_endpoint_suffix}"
)
container_name = os.getenv("CONTAINER_NAME")
# Dataset's folder
dataset_folder = os.path.join(parent_dir, "dataset")
dataset_filepath = os.path.join(dataset_folder, "dataset_embeddings.csv")
# Images' folder
images_folder = os.path.join(parent_dir, "semart_dataset", "images")
# Content-Type for blobs
content_settings = ContentSettings(content_type="image/jpeg")
def main():
# Create Azure Blob Storage client
blob_service_client = BlobServiceClient.from_connection_string(conn_str=blob_connection_string)
# Create a new container
try:
container_client = blob_service_client.create_container(name=container_name, public_access="blob")
except ResourceExistsError:
sys.exit(f"A container with name {container_name} already exists.")
# Find the URLs of the images in the dataset
images = load_image_filenames()
print(f"Number of images in the dataset: {len(images)}")
print(f"Uploading images to container '{container_name}'")
# Upload images to blob storage
upload_images(images=images, container_client=container_client)
def load_image_filenames() -> list[str]:
with open(dataset_filepath, "r") as csv_file:
csv_reader = csv.DictReader(csv_file, delimiter="\t", skipinitialspace=True)
image_filenames = [row[IMAGE_FILE_CSV_COLUMN_NAME] for row in csv_reader]
return image_filenames
def upload_blob_from_local_file(
image_filepath: str,
container_client: ContainerClient,
) -> None:
blob_name = os.path.basename(image_filepath)
try:
blob_client = container_client.get_blob_client(blob=blob_name)
with open(image_filepath, mode="rb") as data:
blob_client.upload_blob(data=data, overwrite=True, content_settings=content_settings)
except Exception as e:
print(f"Couldn't upload image {blob_name} to Azure Storage Account due to error: {e}")
def upload_images(images: list[str], container_client: ContainerClient) -> None:
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
list(
tqdm(
executor.map(
lambda x: upload_blob_from_local_file(
image_filepath=os.path.join(images_folder, x),
container_client=container_client,
),
images,
),
total=len(images),
)
)
Store embeddings in Azure Cosmos DB for PostgreSQL
The code for inserting vector embeddings into an Azure Cosmos DB for PostgreSQL table can be found at data_upload/upload_data_to_postgresql.py.
Create an Azure Cosmos DB for PostgreSQL cluster
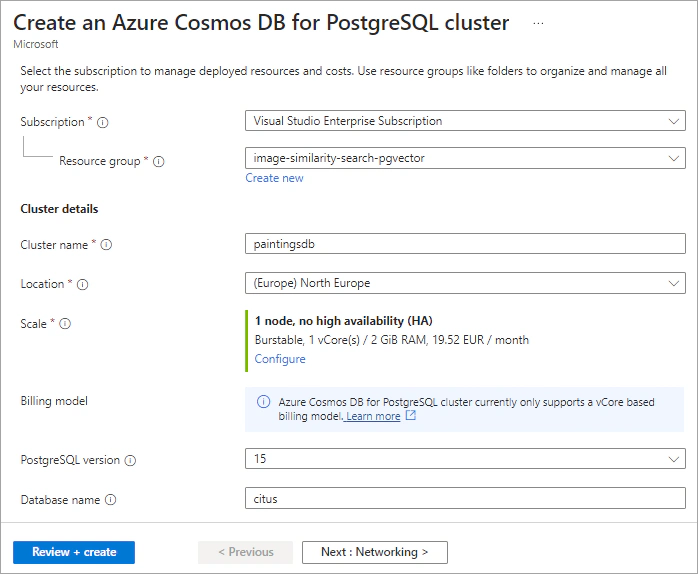
Let's use the Azure portal to create an Azure Cosmos DB for PostgreSQL cluster.
- Search for “Azure Cosmos DB for PostgreSQL” and then select +Create.
-
Fill out the information on the Basics tab:
- Subscription: Select your subscription.
- Resource group: Select your resource group.
- Cluster name: Enter a name for your Azure Cosmos DB for PostgreSQL cluster.
- Location: Choose your preferred region.
- Scale: You can leave Scale as its default value or select the optimal number of nodes as well as compute, memory, and storage configuration. Burstable, 1 vCores / 2 GiB RAM, 32 GiB storage is sufficient for this demo.
- PostgreSQL version: Choose a PostgreSQL version such as 15.
- Database name: You can leave database name at its default value citus.
- Administrator account: The admin username must be citus. Select a password that will be used for citus role to connect to the database.
-
On the Networking tab, select Allow public access from Azure services and resources within Azure to this cluster and create your preferred firewall rule.

Select Review + Create. Once the deployment is complete, navigate to your resource.
Activate the pgvector extension
The pgvector extension adds vector similarity search capabilities to your PostgreSQL database. To use the extension, you have to first create it in your database. You can install the extension, by connecting to your database and running the CREATE EXTENSION command from the psql command prompt:
SELECT CREATE_EXTENSION('vector');
The pgvector extension introduces a data type called VECTOR that can be used during the creation of a table to indicate that a column will hold vector embeddings. When creating the column, it's essential to specify the dimension of the vectors. In our scenario, Azure AI Vision generates 1024-dimensional vectors.
Insert data into a PostgreSQL table
To insert data into an Azure Cosmos DB for PostgreSQL table, we will proceed as follows:
- Create a table to store the filenames of the images, their embeddings, and their associated metadata. All information is saved in a CSV file, as presented in Part 2.
- Insert the data from the CSV file into the table using the PostgreSQL
COPYcommand.
import os
import psycopg2
from psycopg2 import pool
from dotenv import load_dotenv
# Constants
IMAGE_FILE_COLUMN_NAME = "image_file"
DESCRIPTION_COLUMN_NAME = "description"
AUTHOR_COLUMN_NAME = "author"
TITLE_COLUMN_NAME = "title"
TECHNIQUE_COLUMN_NAME = "technique"
TYPE_COLUMN_NAME = "type"
TIMEFRAME_COLUMN_NAME = "timeframe"
VECTOR_COLUMN_NAME = "vector"
# Directories
current_dir = os.path.dirname(os.path.realpath(__file__))
parent_dir = os.path.dirname(current_dir)
# Load environemt file
load_dotenv(os.path.join(parent_dir, ".env"), override=True)
# Azure CosmosDB for PostgreSQL credentials
postgres_host = os.getenv("POSTGRES_HOST")
postgres_database_name = os.getenv("POSTGRES_DB_NAME")
postgres_user = os.getenv("POSTGRES_USER")
postgres_password = os.getenv("POSTGRES_PASSWORD")
sslmode = "require"
table_name = os.getenv("POSTGRES_TABLE_NAME")
postgres_connection_string = (
f"host={postgres_host} user={postgres_user} "
f"dbname={postgres_database_name} "
f"password={postgres_password} sslmode={sslmode}"
)
# Dataset's folder
dataset_folder = os.path.join(parent_dir, "dataset")
dataset_filepath = os.path.join(dataset_folder, "dataset_embeddings.csv")
def main():
postgresql_pool = psycopg2.pool.SimpleConnectionPool(1, 20, postgres_connection_string)
if (postgresql_pool):
print("Connection pool created successfully")
# Get a connection from the connection pool
conn = postgresql_pool.getconn()
cursor = conn.cursor()
print("Creating a table...")
cursor.execute(f"DROP TABLE IF EXISTS {table_name};")
cursor.execute(
f"CREATE TABLE {table_name} ("
f"{IMAGE_FILE_COLUMN_NAME} TEXT PRIMARY KEY,"
f"{DESCRIPTION_COLUMN_NAME} TEXT NOT NULL,"
f"{AUTHOR_COLUMN_NAME} TEXT NOT NULL,"
f"{TITLE_COLUMN_NAME} TEXT NOT NULL,"
f"{TECHNIQUE_COLUMN_NAME} TEXT,"
f"{TYPE_COLUMN_NAME} TEXT,"
f"{TIMEFRAME_COLUMN_NAME} TEXT,"
f"{VECTOR_COLUMN_NAME} VECTOR(1024) NOT NULL);"
)
print("Saving data to table...")
with open(dataset_filepath) as csv_file:
cursor.copy_expert(
f"COPY {table_name} FROM STDIN WITH "
f"(FORMAT csv, DELIMITER '\t', HEADER MATCH);",
csv_file
)
conn.commit()
# Fetch all rows from table
cursor.execute(f"SELECT * FROM {table_name};")
rows = cursor.fetchall()
print(f"Number of records in the table: {len(rows)}")
# Close the connection
cursor.close()
conn.close()
Next steps
In this post, you uploaded the paintings’ images into an Azure Blob Storage container, configured the Azure Cosmos DB for PostgreSQL database as a vector database using the pgvector extension, and inserted the data into a table. In the subsequent posts, you will leverage the pgvector extension to perform a similarity search on the embeddings.
If you want to explore pgvector's features, check out these learning resources:
- How to use pgvector on Azure Cosmos DB for PostgreSQL – Microsoft Docs
- Official GitHub repository of the pgvector extension
👋 Hi, I am Foteini Savvidou!
An Electrical and Computer Engineer and Microsoft AI MVP (Most Valuable Professional) from Greece.




Top comments (0)