Software at Scale
 Software at Scale
Software at Scale
Systemizing Platform Strategy
As technology organizations grow, there’s a lot of software engineering work that doesn’t translate to additional customer value but is just the “cost of doing business” - like initiatives for reliability, security, and developer infrastructure. This work is often undertaken by so-called platform teams.
For the purpose of this blog post, let’s solidify the definition of a platform team - a platform team doesn’t directly focus on additional customer value (new products/features) and has other engineering teams as customers. Examples include developer tools teams, infrastructure, or reliability teams where the team works on internal systems which other customer-facing teams use, directly or indirectly. On the other hand, a team that purely focuses on the reliability of an internal system, where the work doesn’t impact other engineering teams, is not a platform team.
I’ve been on such platform teams that own developer tools, build and deploy infrastructure, and internal platforms for the past few years. In these teams, the largest challenge has been crafting, scoping, and prioritizing initiatives every planning cycle. Each team operated with a unique set of constraints and aimed to solve different problems, but over time, I noticed some themes that held true across teams, and also resonated with other folks I spoke to across the industry.
So I created an aspirational process to systemize prioritization of platform work, and I’ve sketched it out in this blog.
Strategy Challenges
Platform strategy is tricky for many reasons.
First, you probably have customers with conflicting needs. It’s easy to make your system seem more reliable by reducing the frequency of changes you allow or preventing Friday night deploys, but that would affect developer velocity so it might not be the right trade-off.
Second, it’s an N-dimensional problem - if you own multiple areas like security and reliability, you might have projects that could solve problems in both areas, so we should be forcing ourselves to think holistically. For example, a project to improve build times might improve both developer experience and get the finance team off your back, and leave you room for other important initiatives. In contrast, driving a project solely to optimize CI/CD infrastructure might help with the same cost savings, but won’t improve developer experience.
Third, technical choices tend to have compounding implications over time, which make decisions (and the corresponding opportunity costs) feel expensive and Type-1. For example, if you choose to punt on enforcing that your codebase is fully typed today, the codebase will keep growing, and solving this problem in the future will require more work, with the additional work often proportional to the growth of your engineering team.
Lastly, the cost/benefit calculation of each initiative constantly changes due to the rapid changes in our industry and the technological landscape. For example, if you wait just one more quarter, maybe AWS/Kafka/<insert offering> will add that feature that solves this problem for you in a much cheaper way. Alternatively, you might pick the wrong horse when you’re an early adopter of a particular technology, and you might have to pay down that cost by a painful migration later on.
To summarize:
Platform teams often have customers with conflicting needs and have to think carefully about the implications of each project
Projects might have an impact across multiple areas of ownership so it pays to think holistically
Technical choices compound over time, increasing the cost of mistakes
The fast-moving industry landscape causes the cost/benefit calculation of each choice to change rapidly
Prioritization Considerations
With all these in mind, it’s helpful to come up with a set of guidelines that help with effective prioritization.
Principles & Commitments
Principles are an abstract set of statements that help guide prioritization. For instance, AWS has a job zero which is considered table-stakes for the team and takes precedence over any other work. AWS states that security is their job zero, and for good reason - a customer data leak could be highly damaging to the brand, turn away future customers, and cause significant monetary loss. Losing the keys to the kingdom might cause your business to shut down.
Slightly more concrete is commitments - the set of properties that your system should adhere to, or the set of features that are considered the bare minimum to support. It’s important to ensure that commitments are met, and breakages are resolved in a timely manner. For example, at Vanta (where I work at the time of writing), the Platform team commits to ensuring that hot-reloading works for front-end development.
It’s important to systemize commitments - shared publicly within the organization, and have general alignment on the importance within the team, so that teams can share a reference on the prioritization of commitment-related work. Without systemized commitments, teams often end up having implicit commitments, where the set of what actually gets fixed depends on the interests and engagement of individuals, rather than the team. For example, if you have an engineer who cares that alert volume stays low, it’s easy to grow dependent on them, and the system would degrade over time when they decide to move on and no one prioritizes work to improve the situation.
SLAs are basically metric-based commitments, and provide easier tracking, alerting, therefore accountability.
Having a list of commitments makes your job as a prioritizer easier - if it’s not easy maintaining a set of commitments, it’s very likely that you either need to change them or prioritize a project that solves the underlying problems. This is similar to Will Larson’s thinking on whether your team is operating in Foundation or Innovation mode - it should be somewhat straightforward to plan your work if there’s a lot of work to be done to meet what your team considers table-stakes.
Understanding
A platform team has to have a deep understanding of its domain. The team has to understand its mission, purpose, and how it helps with the overall business. After this, it needs to have a reasonable understanding of the industry - how teams with similar missions in other companies are generally run, and upcoming technology in their field. For example, an observability team should have a rough understanding of the capabilities of observability systems that can be used for companies of their given scale. A developer tooling team at a certain company size should understand how much companies at their size usually spend per engineer on internal tools.
There are fairly obvious downsides when a team doesn’t understand its mission. But if it doesn’t understand its systems - it will likely find it hard to resolve issues during an outage, efficiently make small changes to meet simple internal customer needs, empathize with the quirks in the system, and be aware of when the system genuinely isn’t going to be enough. Common symptoms of a platform team without sufficient knowledge are team-members grumbling about how complex and opaque the existing system is, a fear of making changes, and a continuous stream of reactive work.
Toil
Platform teams need to have a strong focus on toil reduction. A team that works purely on the most business impactful projects and doesn’t take team sustainability into account is likely to have burned-out team members and attrition, which doesn’t help the business. The exact amount of time that your team spends on toil vs. projects is case by case - Google SRE points to 50%, but I’ve found that to be too much in practice in a smaller company - more than 30% is probably excessive.
Impact
First, it’s important to recognize that platform teams are ultimately responsible for business continuity and performance, not employee happiness. A platform team might nominally be serving internal teams, but it needs to prioritize based on what will help the business most, not by the raw number of teams impacted. In order to do this, platform teams have to understand company and business strategy as well as regular product teams.
Measuring the impact of a particular project is often an art when there aren’t reasonable metrics to help guide the decision, and deserves its own blog post.
Taking all these pieces, we have enough of the picture to help formulate our system.
Platform Strategy Decision Maze
Putting all the considerations together - we show a rough flow-chart to help formulate strategy. This is similar to the concept of an idea-maze for thinking about startup ideas.
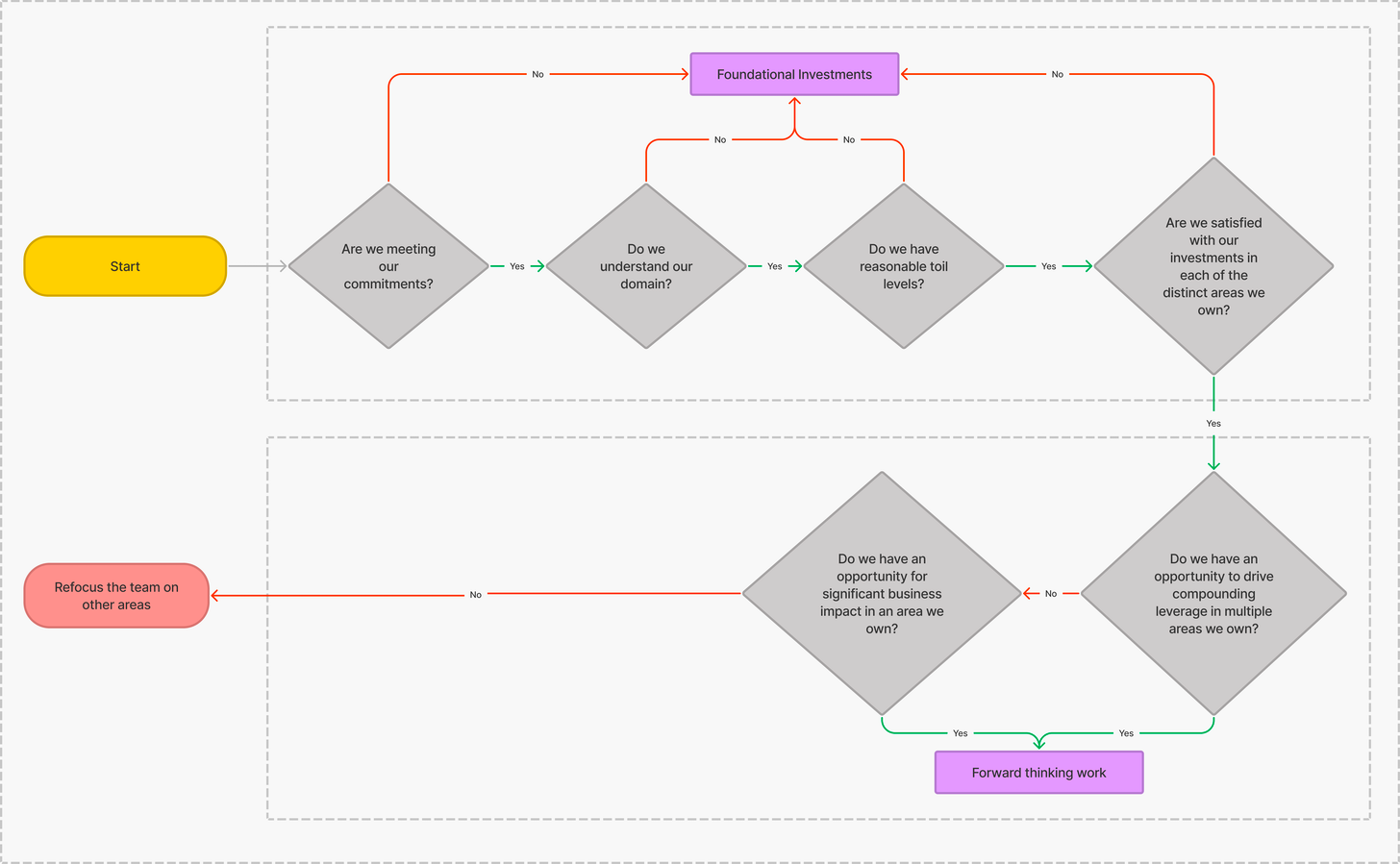
We can call this the decision maze.
The key idea is for the team to develop the muscle to successfully execute foundational work, obtain mastery over their systems, reduce toil to ensure that unplanned work is bounded, and fundamentally understand their domain. This buys time and expertise for the successful execution of forward-thinking projects and keeps the system sustainable for changing circumstances.
For foundational investments, in prioritized order, the team should:
Maintain its commitments to the business (or tweak them)
Understand its domain
Minimize toil
Ensure sufficient investment in each area that they own
Armed with the breathing room from these foundational investments, the team could focus on compounding leverage - initiatives that can deliver increasing value over time, or prevent issues that would get likelier over time, and cross-cutting efforts - systematic efforts that would improve multiple areas of ownership.
Let’s explore how this solves the problems we originally laid out.
Teams ensure that they stick to their commitments as they execute projects, keeping customers with conflicting needs satisfied.
Teams develop a holistic understanding of their systems and the state of the industry, which helps tease out projects that might impact multiple areas of ownership and understand what they can incorporate from outside.
Teams focus on solving problems with compounding leverage and multiple areas of impact over other problems.
The next challenge is being satisfied with the answers to the questions at each decision point in the decision maze.
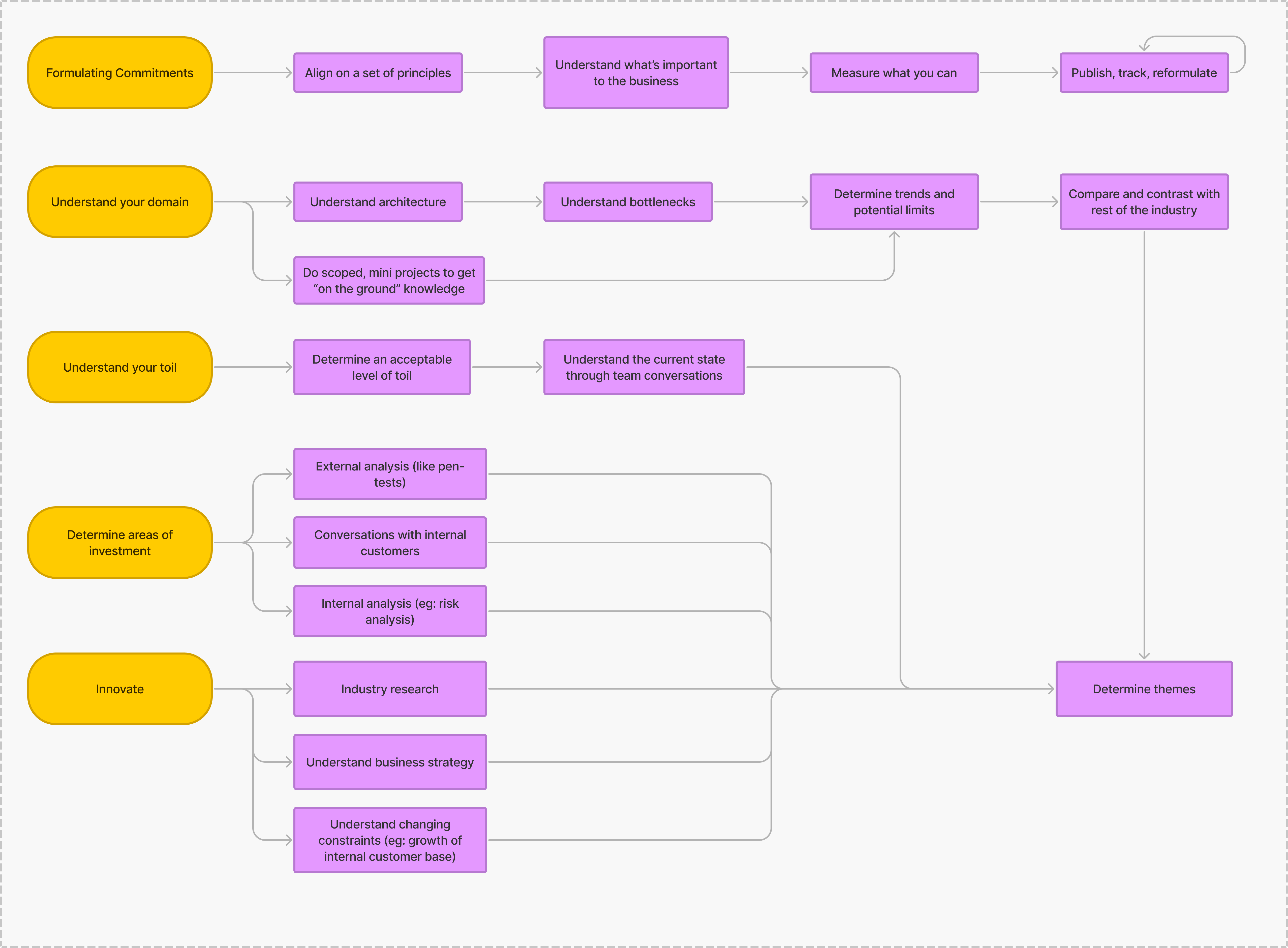
Above, we’ve sketched out potential methods to help guide each decision.
Let’s take an example of an infrastructure or reliability team tasked with network traffic management trying to lay out its strategy. The team could:
Set up their security principles and SLAs on availability numbers, and gain the confidence they will be able to hit those in the medium term, otherwise, fund a project to get there
Understand their various owned subsystems like reverse proxies, the subsystem’s relative strengths and weaknesses, and how they stack up with similar open-source systems/paid products
Reduce their toil like on-call alarms through tackling low-hanging fruit, or have a plan on the roadmap to resolve the problem
Perform risk analysis and forecast growth to understand whether they need to invest in security, availability, or both
Talk to internal customers about capabilities that their systems should have and do some requirements gathering to understand blind spots
Investigate whether a project would let the team have significantly better commitments, increased system simplicity, reduced toil, or provide significant business impact on an important dimension like latency
To be clear, this isn’t a hard-and-fast ruleset, and teams often need to prioritize projects that don’t follow the prescribed ordering for various important reasons like team morale or momentum. Additionally, there might be the need for foundational projects in one area of ownership, and innovative projects in another area, and work can take place in parallel. So truly, these are just rules of thumb to kick-start a conversation on the extremely tricky and unverifiable process of crafting a strategy for platform teams.
Credits
Credits to Robbie Ostrow for teaching me about systemizing commitments, and Will Larson for his excellent writing on infrastructure prioritization, foundational vs. innovation investments, and picking the right work.




