In distributed systems, it is crucial to understand failure and how to mitigate it in order to maintain high availability.
As we saw in System Models, the characteristics of Nodes and Network in distributed systems make it difficult to detect failure, particularly given the asynchronous nature of networks.
Why is it so difficult?
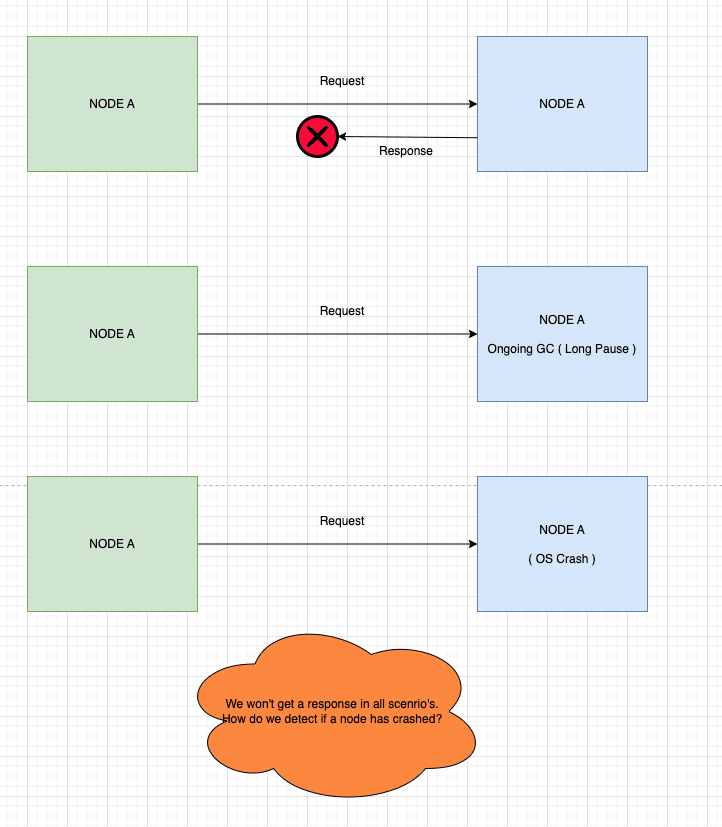
Most of the time, we find out about failures by sending a request to a node and waiting for a response for a certain amount of time. If we try X times and don't get a response, we say that the node has failed.
But it's not that easy. We only know that our requests to the node went unanswered X times. We don't know if the node has crashed, if there's a problem with the network between nodes, or if the node is just slow to respond because it's busy with other work.
A node might not respond for more than one reason. If that's the case, how do we tell the difference between these scenarios to know for sure if a node has crashed?
When we rely on timeouts, we can also get false positives. Think about this situation.
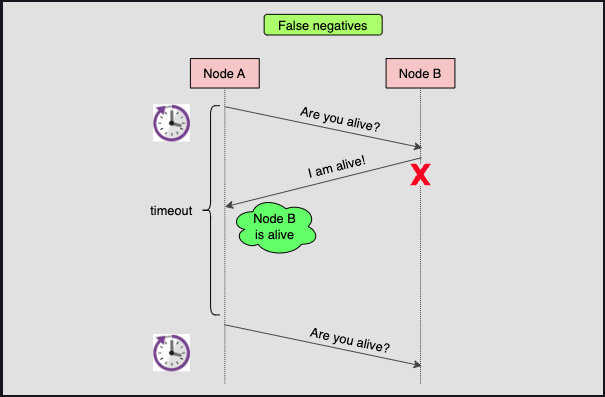
In this case, Node B crashed as soon as it replied. But since Node B answered before the crash, Node A now thinks that Node B is still alive, even though it isn't.
The timeout you choose is also a very important part of how accurate the results are.
- If you choose a short timeout, there will be a lot more false positives because the node might still be alive, but it took longer than the set timeout to process the message. Choosing a longer timeout is also not a good idea because the node could have crashed and you could be waiting for a response that will never come.
Failure Detector
A failure detector is an algorithm that checks to see if other nodes in the network have failed.
How Failure Detectors Work
We can tell the different types of failure detectors apart by looking at two basic features that show the different trade-offs.
- Completeness is the percentage of crashed nodes that a "failure detector" is able to find in a certain amount of time.
- Accuracy is the number of mistakes that a failure detector makes in a certain amount of time.
Perfect Failure Detector
A perfect failure detector is an algorithm that is both Complete and Accurate to the highest degree. This detector detects every faulty process without assuming a node has crashed before it actually does and has no margin of error.
Unfortunately, as we saw earlier, building a Perfect Failure Detector in purely Asynchronous Systems is impossible.
Eventually Perfect Failure Detectors
Perfect Failure Detectors are impossible in Asynchronous Distributed Systems, so we use Eventually Perfect Failure Detectors instead.
These detectors have the following qualities
- A node can be marked as "crashed" even if it's still alive
- A node may be temporarily labelled as alive even if it has crashed.
- Eventually, a node will be marked as crashed only if it has really crashed.
A perfect example of an Eventually Perfect Failure Detector is a timeout. When a timeout ends, we might not know right away if the node has crashed, but if we keep trying and the node doesn't respond for more than X times, we know it has crashed and mark it as crashed.





Top comments (0)