Vector representations of language are crucial in advancing Natural Language Processing (NLP). Simply put, by converting text into vectors, a computer can effectively capture the content and meaning of the text.
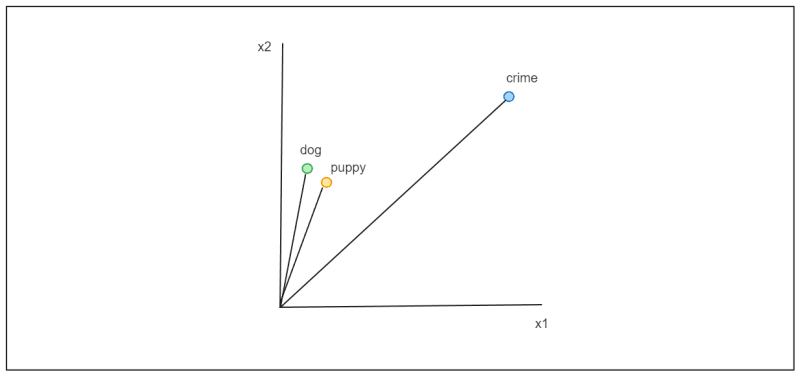
These vectors enable various NLP tasks, including sentiment analysis, document clustering, question answering, text generation, semantic similarity, vector search, and more. Vectors representing similar contexts are positioned close to each other in the vector space, as illustrated in the following visualization.
In general, there are two types of vectors: dense vectors and sparse vectors. While they can be utilized for similar tasks, each has advantages and disadvantages.
The dimensionality of a dense vector, which represents a text entity in a compact manner, is determined by the deep learning model used to convert the text into vectors. For instance, BERT generates a 768-dimensional vector for each token. In contrast, a sparse vector has a higher dimensionality than a dense vector, but most of its values are zero, hence the term 'sparse '.
In this post, we will delve into two popular variants of sparse embedding: BM25 and SPLADE. Let's begin with the older method, BM25.
The Fundamentals of BM25
Best Matching 25 (BM25) is a text-matching algorithm that can be viewed as an enhancement of the Term Frequency-Inverse Document Frequency (TF-IDF) algorithm. TF-IDF is an information retrieval algorithm that measures the importance of a keyword within a document relative to a collection of documents.
For example, imagine we have the keyword "machine learning," and we want to find the most relevant document in a collection based on this keyword. The TF-IDF algorithm would calculate the relevancy score of the keyword in each document using a formula that looks like this:

The document with the highest relevancy score will be recommended to the user.
BM25 can be considered an enhancement of TF-IDF due to two key factors:
It takes into account the document length.
It incorporates the concept of a keyword saturation term.
Now, let's jump into why these improvements are significant. The traditional TF-IDF algorithm does not consider the length of the document. This results in longer documents having an advantage over shorter ones, as the likelihood of the keyword appearing more frequently increases with document length. The BM25 algorithm addresses this issue by normalizing the document length in the Term Frequency (TF) equation.
On the other hand, the introduction of the saturation term in BM25 addresses the problem of potential keyword spamming within a document. In TF-IDF, the TF equation linearly increases with each additional occurrence of a keyword in a document. However, we might argue that the impact of going from 1 to 2 occurrences should be more significant than going from 100 to 101 occurrences.
The saturation term in the BM25 algorithm resolves this by gradually diminishing the influence of a keyword's occurrence as its frequency increases. Furthermore, the saturation term value can be adjusted to control how rapidly the keyword occurrence reaches the saturation point, as you can see in the visualization below:

With these key enhancements incorporated into the BM25 equation, the algorithm can deliver improved information retrieval results compared to the traditional TF-IDF approach.
BM25 is a type of sparse embedding, meaning the generated vector consists primarily of zero values. The dimensionality of the BM25 vector depends on the unique number of entities (subwords, words, or tokens) within the document collection. The non-zero entries in the BM25 vector correspond to the dimensions where the query keyword resides, and the values represent the keyword's relevancy score.
If we have a single-word keyword, and each entity represents a word, then only one element of the BM25 vector will have a non-zero value. This condition applies when the exact match of the keyword can be found in the document. Otherwise, all values in the vector will be zero.
This highlights a drawback of traditional sparse vectors. When the exact match of the query keyword cannot be found in a document, the sparse vector of BM25 fails to capture the importance of the keyword, even though the document may discuss a similar topic.
To address this limitation, more recent advancements in sparse embedding have been made, leading to the development of SPLADE. However, before we delve into SPLADE, let's briefly revisit the fundamental concepts of BERT, as SPLADE is largely based on this powerful Transformer-encoder model.
The Fundamentals of BERT
Bidirectional Encoder Representations from Transformers, or BERT, is a state-of-the-art Transformer-encoder-based model that performs remarkably in many NLP tasks. As the name suggests, this model relies on the famous Transformer architecture as its building block.
![]()
The Transformer is a powerful encoder-decoder-based model capable of performing various tasks across different modalities. The key distinguishing feature of the Transformer architecture is the self-attention layer within each encoder and decoder block, which enables models derived from it, including BERT, to capture the semantic meaning of text input effectively.
BERT comprises multiple Transformer encoder blocks, and the number of these encoder blocks depends on the specific BERT variant. For example, the BERT Base model consists of 12 encoder blocks, while the BERT Large model has 24 encoder blocks.
![]()
The pre-training process of a BERT model involves a technique known as Masked Language Modeling (MLM). In this method, a certain percentage of input tokens are randomly replaced by a [MASK] token, and the goal is to predict this masked token. The bidirectional nature of the Transformer encoder used in BERT allows the model to predict the most likely token at any position based on the context of the entire input sequence.
The Fundamentals of SPLADE
SPLADE generates a learnable sparse vector, going beyond a typical sparse vector. It leverages BERT's MLM capability in its construction. The process begins by tokenizing both the document and the query using the same sub-word-level tokenization process as BERT. SPLADE then employs the MLM approach for each token, predicting the most probable tokens for each position from BERT's vocabulary of 30,522 tokens, considering the context of the entire sequence.
Subsequently, SPLADE combines these probabilities for each token across all positions and applies a logarithmic saturation method to introduce data sparsity. The resulting weights indicate the relevance of each vocabulary token to the input tokens, thereby creating a learned sparse vector.

As you might imagine, the non-zero values produced by SPLADE tend to be much higher than those of traditional sparse vectors like BM25.
To illustrate this, consider a keyword like "study". If we use BM25 to convert it into a sparse vector, we would have only one non-zero value in the corresponding vector. In contrast, with SPLADE, we would likely have more than one non-zero value, as the vector elements associated with similar terms like "learn", "research", or "investigate" would also be non-zero.
This difference in sparsity can improve information retrieval accuracy, as SPLADE's ability to capture semantically similar terms, even without exact keyword matches, allows it to retrieve more relevant documents for a given query.
BM25 and SPLADE Implementation
Now that we understand the key differences between BM25 and SPLADE, let's implement both of them using Milvus to perform text search.
If you'd like to follow along, you can check out the code implementation in the provided notebook.
To use traditional sparse embedding like BM25, we need a collection of data that can serve as our corpus. For this purpose, we'll be using the climate change data available on HuggingFace as our corpus. Let's start by downloading the data.
import pymilvus
from pymilvus import MilvusClient
from pymilvus import (
utility,
FieldSchema, CollectionSchema, DataType,
Collection, AnnSearchRequest, RRFRanker, connections,
)
from pymilvus.model.sparse.bm25.tokenizers import build_default_analyzer
from pymilvus.model.sparse import BM25EmbeddingFunction,SpladeEmbeddingFunction
from datasets import load_dataset
dataset = load_dataset("climate_fever")
If you take a look at our dataset, we have four columns: claim_id, claim, claim_label , and evidences. For the corpus of BM25, we’ll use the claim column only. Here are several examples of what’s inside the claim column.
corpus_text = dataset['test']['claim']
print(corpus_text[:5])
"""
Output:
['Global warming is driving polar bears toward extinction',
'The sun has gone into 'lockdown' which could cause freezing weather, earthquakes and famine, say scientists',
'The polar bear population has been growing.',
"Ironic' study finds more CO2 has slightly cooled the planet",
'Human additions of CO2 are in the margin of error of current measurements and the gradual increase in CO2 is mainly from oceans degassing as the planet slowly emerges from the last ice age.']
"""
Now that we have our corpus text, let's use it to fit the BM25 model.
analyzer = build_default_analyzer(language="en")
# Use the analyzer to instantiate the BM25EmbeddingFunction
bm25_ef = BM25EmbeddingFunction(analyzer)
# Fit the model on the corpus to get the statistics of the corpus
bm25_ef.fit(corpus_text)
Meanwhile, we don’t need to fit a SPLADE model into a certain corpus, as it leverages the BERT model under the hood. Therefore, we can use it to transform a text into sparse embedding straight away.
Let’s say now we have five texts, and we want to transform them into sparse embeddings. We can do so easily by using the encode_documents() method from Milvus.
documents = ["Currently, scientists none of these places, which today supply much of the world's food, will be reliable sources of any.",
"Over the coming 25 or 30 years, scientists say, the climate is likely to gradually warm. However, researchers also say that this phenomenon can be stopped if human emissions are reduced to zero.",
"The jet stream forms a boundary between the cold north and the warmer south, but the lower temperature difference means the winds are now weaker.",
"Coral becomes stressed and expels the algae, which leave the coral a bleached white color.",
"The rapid changes in the climate may have profound consequences for humans and other species... Severe drought caused food shortages for millions of people in Ethiopia, with a lack of rainfall resulting in intense and widespread forest fires in Indonesia that belched out a vast quantity of greenhouse gas"]
# Create embeddings for the documents
bm25_docs_embeddings = bm25_ef.encode_documents(documents)
print("Sparse dim:", bm25_ef.dim, list(bm25_docs_embeddings)[0].shape)
splade_ef = SpladeEmbeddingFunction(
model_name="naver/splade-cocondenser-ensembledistil",
device="cpu"
)
"""
Output
Sparse dim: 3432 (1, 3432)
"""
splade_docs_embeddings = splade_ef.encode_documents(documents)
print("Sparse dim:", splade_ef.dim, list(splade_docs_embeddings)[0].shape)
"""
Output:
Sparse dim: 30522 (1, 30522)
"""
The sparse vector dimensions of BM25 and SPLADE differ, as shown above. The dimension of a BM25 vector is determined by the vocabulary size within the corpus text, while the dimension of a SPLADE vector corresponds to the deep learning model it is based on. Given that SPLADE is built on BERT, which has a vocabulary size of 30,522, the vector dimension of SPLADE is also 30,522.
After transforming each of the five texts into BM25 and SPLADE vector embeddings, the next step is establishing a database for storing and efficiently retrieving them as needed. To achieve this, we will utilize Milvus as the vector database. First, we need to define the schema of the collection. The collection should contain four fields: ID, text, BM25 embedding, and SPLADE embeddings.
Before storing the embeddings, it is also essential to determine the indexing method for the vectors. Milvus offers two indexing methods for sparse vectors: the inverted index or the Weak-AND (WAND) algorithm. Given the high dimensionality of our sparse vectors, the inverted index method is preferred. This method maps each dimension to the non-zero values in the embedding, facilitating direct access to relevant data during searches.
Milvus currently supports only the inner product among the metrics used for vector search. Therefore, we’ll use this metric for our vector search operations.
connections.connect("default", host="localhost", port="19530")
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR,
is_primary=True, auto_id=True, max_length=100),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=512),
FieldSchema(name="bm25_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="splade_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
]
schema = CollectionSchema(fields, "")
col = Collection("bm25_splade_demo", schema)
sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}
col.create_index("bm25_vector", sparse_index)
col.create_index("splade_vector", sparse_index)
# Insert data into schema
entities = [documents, bm25_docs_embeddings, splade_docs_embeddings]
col.insert(entities)
col.flush()
Now that we stored the embeddings inside of a vector database, let’s do a vector search based on a query and then we compare the result of BM25 and SPLADE.
Imagine we have a query as follows: “What do scientists say about climate?”. Let’s examine the results obtained from BM25 and SPLADE.
To convert a query into a vector embedding, we can simply use the encode_queries() method, and then we can perform a vector search straight after.
def get_relevant_text(query_embeddings, anns_field):
res = client.search(
collection_name="bm25_splade_demo",
data=query_embeddings[0],
anns_field=anns_field,
limit=1,
search_params={"metric_type": "IP", "params": {}},
output_fields =["text"]
)
print(res)
# Set up a Milvus client
client = MilvusClient(
uri="<http://localhost:19530>"
)
collection = Collection("bm25_splade_demo") # Get an existing collection.
collection.load()
queries = ["What do scientists say about climate?"]
bm25_query_embeddings = bm25_ef.encode_queries(queries)
"""
Output:
[[{'id': '449467966088806767', 'distance': 7.698919773101807, 'entity': {'text': 'Over the coming 25 or 30 years, scientists say, the climate is likely to gradually warm. However, researchers also say that this phenomenon can be stopped if human emissions are reduced to zero.'}}]]
"""
splade_query_embeddings = splade_ef.encode_queries(queries)
"""
[[{'id': '449467966088806767', 'distance': 16.795665740966797, 'entity': {'text': 'Over the coming 25 or 30 years, scientists say, the climate is likely to gradually warm. However, researchers also say that this phenomenon can be stopped if human emissions are reduced to zero.'}}]]
"""
As you can see, both BM25 and SPLADE are able to fetch the most relevant document according to our query. This result is expected, as the word “scientists”, “climate”, and “say” in our query are also apparent in the resulting document.
Let’s now try a different query and check the result of both algorithms once again. This time our query is “What will get incrementally hotter?” Using the same approach as before, below is the result that we’ll get.
queries = ["What will get incrementally hotter?"]
bm25_query_embeddings = bm25_ef.encode_queries(queries)
splade_query_embeddings = splade_ef.encode_queries(queries)
get_relevant_text(bm25_query_embeddings, "bm25_vector")
"""
Output:
[[]]
"""
get_relevant_text(splade_query_embeddings, "splade_vector")
"""
Output:
[[{'id': '449467966088806767', 'distance': 6.944008827209473, 'entity': {'text': 'Over the coming 25 or 30 years, scientists say, the climate is likely to gradually warm. However, researchers also say that this phenomenon can be stopped if human emissions are reduced to zero.'}}]]
"""
In this example, BM25 and SPLADE produce different results. BM25 is unable to find any matching documents for the given query, while SPLADE is still able to identify the most relevant document.
This is because BM25 is an exact string matching algorithm. If there is a vocabulary mismatch between the query and a document, that document cannot be matched, even if it has a semantically similar meaning to the query.
On the other hand, SPLADE leverages the sophisticated BERT model under the hood, allowing it to capture the semantic similarity between the query and the document content. This enables SPLADE to retrieve the most relevant document, even when the specific terms in the query do not exactly match the terms within the document.
BM25 and SPLADE Consideration
BM25 and SPLADE are two sparse embedding vectors with their advantages and disadvantages.
BM25, an intuitive information retrieval algorithm, offers predictable behavior and easily explainable results. Its vector, containing fewer non-zero values compared to SPLADE, enhances the retrieval process, leading to superior search efficiency.
BM25 also relies on exact string matching and does not depend on specific trainable deep learning models, meaning no additional fine-tuning is required. However, the vocabulary used in the query must also be found in the corpus; otherwise, it risks returning no matching results.
SPLADE, in contrast, generates a vector with more non-zero values, resulting in a slower retrieval process. However, this characteristic can potentially yield superior results, as SPLADE has the capability to include semantically similar terms for each input word. Its foundation on BERT also enables it to potentially deliver good results even when the query vocabularies are not present in the corpus.
However, the performance of SPLADE is not guaranteed to be better than BM25 if the same model is used for different data domains. Like any deep learning model, SPLADE must be fine-tuned according to the specific data to outperform BM25 significantly.
Conclusion
This article discusses two of the most popular algorithms for transforming text into sparse embeddings: BM25 and SPLADE. BM25 is an exact matching algorithm that enables fast and efficient document retrieval. If you have a large corpus and the collection of documents is within the same domain, BM25 can be used as a strong baseline.
On the other hand, SPLADE is a more sophisticated algorithm that leverages BERT to expand the vocabulary in both the query and the documents. This allows SPLADE to retrieve relevant documents, even when the exact terms in the query cannot be found in any of the documents.





Top comments (0)