

AlexNet was introduced in the paper, titled ImageNet Classification with Deep Convolutional Networks, by Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton and since then it has been cited around 67000 times and is widely considered as one of the most influential papers published in the field of computer vision. It was neither the first implementation of CNN architecture nor the first GPU implementation of a Deep CNN architecture, then why it's so influential?
Let's find it out.
Before publication of the paper
- Most of the computer vision tasks were solved using machine learning methods such as SVM and K-NN or Fully Connected Neural Networks.
- CNN architecture with the use of a backpropagation algorithm for computer vision problem was introduced back in 1989 by Yann LeCun et al. (LeNet).
- Fast GPU implementation of a deep CNN with back propagation was introduced a year before (August 2011) by Dan C. Ciresan et al., which had achieved SOTA test error rate of 0.35% on MNIST, 2.53% on NORB and 19.51% on CIFAR10 datasets. They showed their implementation to be 10 to 60 times faster than a compiler-optimized CPU version. (Dan C. Ciresan Net).
- Rectified Linear Unit (ReLU) was introduced by Geoffrey E. Hinton et al. in 2010 on Restricted Boltzmann Machines replacing binary units for recognizing objects and comparing faces.
- In the authors' earlier work, they introduced Dropout layers as an efficient method for reducing overfitting.
- Other than ImageNet dataset, all the publicly available labelled dataset were relatively small (in order of tens of thousands) such as MNIST and CIFAR-10, on which it was easy to achieve good performance with optimized image augmentations.
- ImageNet Large-Scale Visual Recognition Challenge (an annual competition started since 2010) uses a subset of ImageNet (a database introduced by Fei-Fei et al. in 2009) with roughly 1000 images of variable-resolution in each of 1000 categories, enclosing a total of 1.2 million training images, 50,000 validation images, and 150,000 testing images. It is customary to report two error rates: top-1 and top-5 in final submissions.
Data Preprocessing
AlexNet was trained on the centered RGB values of the pixels.
Given a rectangular image, at first, the shorter side was re-scaled to a length of 256 and then a patch of size 256×256 was cropped from the center. Later, the mean value of pixels over the training set was subtracted from each pixel.
Architecture

The network with 60 million parameters was trained by spreading it across two NVIDIA GTX 580 GPU with 3 GB memory each. The kernels of the second, fourth, and fifth convolutional layers were connected only to feature maps which resided on the same GPU, while the kernels of the third convolutional layer were connected to all feature maps across GPUs. Neurons in the fully-connected layers were also connected to all neurons in the previous layer across GPUs.
ReLU non-linear activation was applied to the output of every convolutional and fully connected layer, replacing previously used tanh units. This non-saturating non-linear function was much faster in terms of training time than saturating non-linear tanh function.
Local Response normalization (or brightness normalization) layers followed first and second convolutional layers after applying ReLU activation. These layers helped lower top-1 and top-5 test errors by 1.4% and 1.2% respectively.
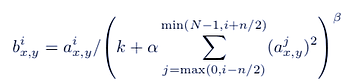
Here variable a represents the ReLU activated value of a neuron. The constants k, n, α, and β are hyper-parameters whose values were k = 2, n = 5, α = 10e-4, and β = 0.75. The sum runs over n “adjacent” kernel maps at the same spatial position, and N is the total number of kernels in the layer.
Max-pooling layers followed both response-normalization layers and the fifth convolutional layer. These overlapping (strides < kernel size) max-pooling layers helped in reducing overfitting.
Training
Image Augmentation Techniques:
- Translation and Horizontal Reflections: During training, network extracts random 227x227 patches (falsely mentioned as 224x224) and applies horizontal reflections. All these augmentations are performed on the fly on the CPU while the GPUs train previous batch of data.
- Test Time Augmentations: During test time, the network predicts by extracting five 224 × 224 patches (the four corner patches and the center patch) as well as their horizontal reflections (hence ten patches in all), and averaging the predictions.
- PCA color augmentation: At first, PCA is performed on all pixels of ImageNet training data set. As a result, they get a 3x3 covariance matrix, as well as 3 eigenvectors and 3 eigenvalues. During training, a random intensity factor based on PCA components is added to each color channel of an image, which is equivalent to changing intensity and color of illumination.
Dropout:
Each hidden neuron in the first two fully-connected layers is set to zero with a probability of 0.5 during training. This means 'dropped out' neurons do not contribute to the forward pass and do not participate in back propagation. Although during testing, all neurons were active and were not dropped.
Kernel Initializer:
Zero-mean Gaussian distribution with a standard deviation of 0.01
Bias Initializer:
1 for second, fourth, fifth convolutional layers and the fully-connected hidden layers. Remaining layers with 0.
Batch Size:
128
Optimizer:
Stochastic Gradient Descent with momentum 0.9
L2 weight decay:
5e-04
Learning Rate Manager:
LR initialized with value 1e-2 and manually reduced on a plateau by a factor of 10
Total epochs:
90
Total time:
6 days
Results
Single AlexNet model achieves top-1 and top-5 test errors of 40.7% and 18.2% respectively.
Their final submission comprised of an ensemble of 7 CNNs (average of 2 extended AlexNet pre-trained on 2011 dataset and then fine-tuned on 2012 dataset and an average of five AlexNet on 2012 dataset) which gave an error rate of 15.3%, lower by a margin of 11% than that of the runner-up (SIFT+FVs model by Fei-Fei et al.).

Thus, the world got its first Deep CNN based large database image recognition winner. The authors used several deep learning techniques which are still relevant and thus established a framework which is still followed to approach complex computer vision problems.





Top comments (47)
@zohebabai a very nice blog on one of the most popular deep learning architecture. It is considered one of the most promising neural networks architecture in Computer Vision.
Thanks a lot for the appreciation 😊. True, AlexNet shall be recalled as that. I shall be covering here all the important deep learning papers in the last decade with additional resources/information.
Sure, I will be watching your posts each weekend to increase my knowledge of Deep Learning.
Thanks for sharing this wonderful content. its very interesting. Many blogs I see these days do not really provide anything that attracts others but the way you have clearly explained everything it's really fantastic. There are lots of posts But your way of Writing is so Good & Knowledgeable. keep posting such useful information and have a look at my site as well
p2gamer
Freelancers Marketplace
Thank you..
Thanks a lot for the appreciation.
Wonderful Site for gamers. Hope you achieve your goals.
I love how you break down complex concepts into easy-to-understand points. It makes the topic accessible to everyone. Well done!
Azure Data Factory Training In Hyderabad
Python Online Job Support
DevOps Online Job Support
Salesforce Online Job Support
Aws Online Job Support
Automation Anywhere Online Job Support
Dot Net Online Job Support
Java Online Job Support
Dell Boomi Online Job Support
iOS Online Job Support
Ab initio Online Job Support
"Great post! Really enjoyed it."
"Insightful read, thank you!"
"Your blog is a treasure trove!"
Kloud Course Academy
Thanks for sharing informative content. How long have you been writing. Keep it up!
Fresher Jobs In Bangalore IT Software
IT Job Openings For Freshers In Bangalore
IT Software Jobs For Freshers
Jobs For Freshers Software Engineer
Jobs For Graduate Freshers
Software Openings For Freshers
Jobs For BTech Freshers
A nice refresher and looking forward for more 👏
Thanks for appreciating 😊.
"Azure trainings are a great way to boost your cloud skills, offering hands-on experience and real-world applications to stay ahead in tech."
PROMPT ENGINEERING COURSE IN HYDERABAD
Looking for AWS courses in Chennai? Join Login360 for comprehensive training that covers AWS fundamentals, cloud architecture, deployment, and management. Gain hands-on experience with real-time projects and expert guidance to excel in cloud computing. Enroll now to boost your career in the fast-growing AWS domain!.
Great article. It’s incredible how important this field has become. For those looking to enhance their digital marketing skills, Login360 offers some of the best courses in Coimbatore.
Some comments may only be visible to logged-in visitors. Sign in to view all comments.