
What will be scraped
Title, link, thumbnail, origin, views, date published, channel from all results.

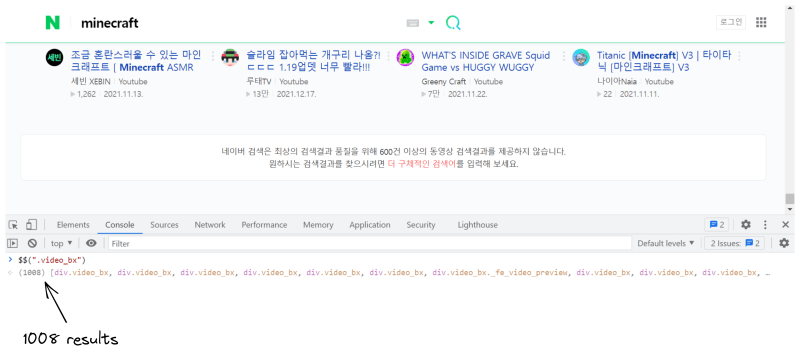
📌Note: Naver Search does not provide more than 600 video search results for the best search result quality: "네이버 검색은 최상의 검색결과 품질을 위해 600건 이상의 동영상 검색결과를 제공하지 않습니다", this is what you'll see when you hit the bottom of the search results.
However, 1008 results were scraped during multiple tests. Possibly, it's because Naver is constantly changing.
Testing CSS selector with SelectorGadget Chrome extension:
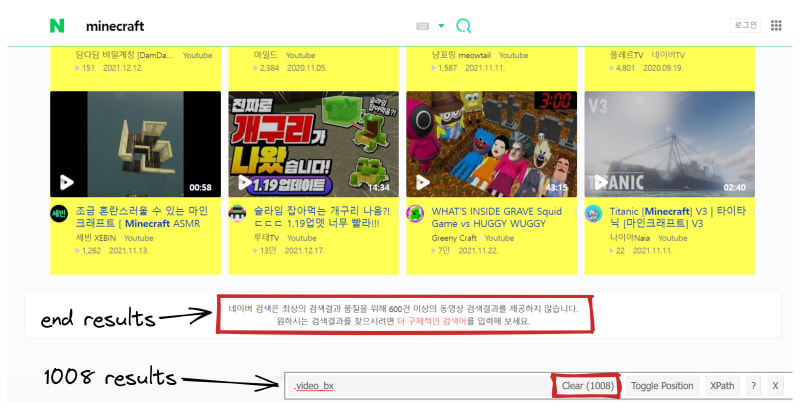
Testing CSS selector in the console:
Prerequisites
Basic knowledge scraping with CSS selectors
CSS selectors declare which part of the markup a style applies to thus allowing to extract data from matching tags and attributes.
If you haven't scraped with CSS selectors, there's a dedicated blog post of mine about how to use CSS selectors when web-scraping that covers what it is, pros and cons, and why they're matter from a web-scraping perspective.
Separate virtual environment
If you didn't work with a virtual environment before, have a look at the dedicated Python virtual environments tutorial using Virtualenv and Poetry blog post of mine to get familiar.
In short, it's a thing that creates an independent set of installed libraries including different Python versions that can coexist with each other at the same system thus preventing libraries or Python version conflicts.
📌Note: this is not a strict requirement for this blog post.
Install libraries:
pip install requests, parsel, playwright
Full Code
This section is split into two parts:
| Method | Used libraries |
|---|---|
| parse data without browser automation |
requests and parsel which is a bs4 analog that supports Xpath. |
| parse data with browser automation |
playwright, which is a modern selenium analog. |
Scrape all Naver Video Results without Browser Automation
import requests, json
from parsel import Selector
params = {
"start": 0, # page number
"display": "48", # videos to display. Hard limit.
"query": "minecraft", # search query
"where": "video", # Naver videos search engine
"sort": "rel", # sorted as you would see in the browser
"video_more": "1" # required to receive a JSON data
}
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
}
video_results = []
html = requests.get("https://s.search.naver.com/p/video/search.naver", params=params, headers=headers, timeout=30)
json_data = json.loads(html.text.replace("( {", "{").replace("]})", "]}"))
html_data = json_data["aData"]
while params["start"] <= int(json_data["maxCount"]):
for result in html_data:
selector = Selector(result)
for video in selector.css(".video_bx"):
title = video.css(".text").xpath("normalize-space()").get().strip()
link = video.css(".info_title::attr(href)").get()
thumbnail = video.css(".thumb_area img::attr(src)").get()
channel = video.css(".channel::text").get()
origin = video.css(".origin::text").get()
video_duration = video.css(".time::text").get()
views = video.css(".desc_group .desc:nth-child(1)::text").get()
date_published = video.css(".desc_group .desc:nth-child(2)::text").get()
video_results.append({
"title": title,
"link": link,
"thumbnail": thumbnail,
"channel": channel,
"origin": origin,
"video_duration": video_duration,
"views": views,
"date_published": date_published
})
params["start"] += 48
html = requests.get("https://s.search.naver.com/p/video/search.naver", params=params, headers=headers, timeout=30)
html_data = json.loads(html.text.replace("( {", "{").replace("]})", "]}"))["aData"]
print(json.dumps(video_results, indent=2, ensure_ascii=False))
Create URL parameters and request headers:
# https://docs.python-requests.org/en/master/user/quickstart/#passing-parameters-in-urls
params = {
"start": 0, # page number
"display": "48", # videos to display. Hard limit.
"query": "minecraft", # search query
"where": "video", # Naver videos search engine
"sort": "rel", # sorted as you would see in the browser
"video_more": "1" # unknown but required to receive a JSON data
}
# https://requests.readthedocs.io/en/master/user/quickstart/#custom-headers
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
}
Create temporary list to store parsed data:
video_results = []
Pass headers, URL params and make a request to get JSON data:
html = requests.get("https://s.search.naver.com/p/video/search.naver", params=params, headers=headers, timeout=30)
# removes (replaces) unnecessary parts from parsed JSON
json_data = json.loads(html.text.replace("( {", "{").replace("]})", "]}"))
html_data = json_data["aData"]
| Code | Explanation |
|---|---|
timeout=30 |
to stop waiting for a response after 30 sec. |
Returned JSON data from json_data:
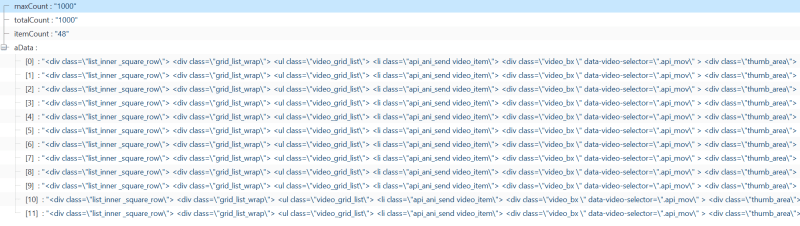
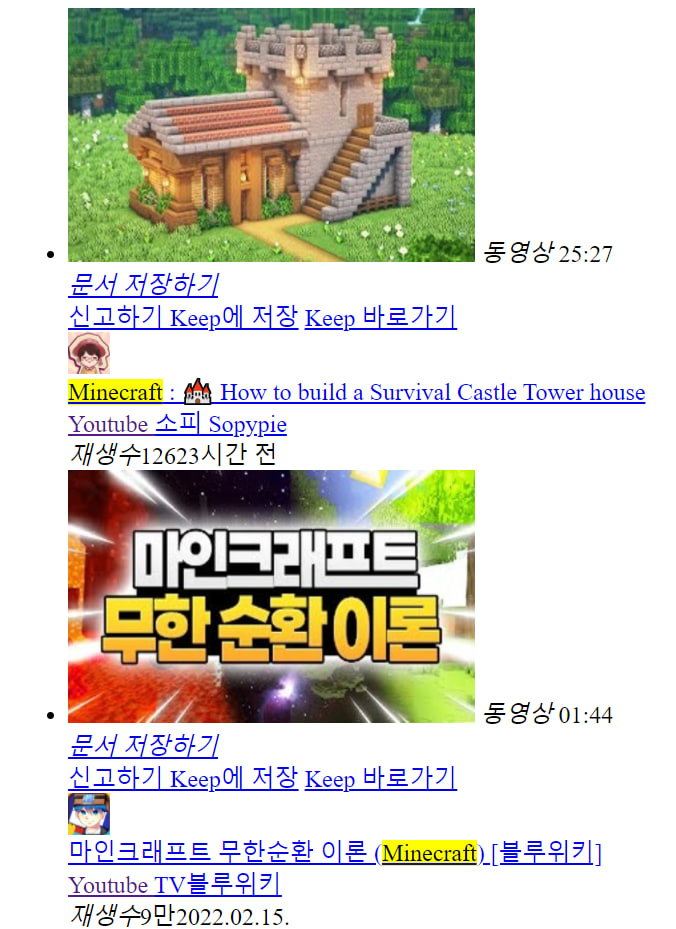
Actual HTML returned from html_data, more precisely from json_data["aData"] (saved and opened in the browser):
Create a while loop to extract all available video results:
while params["start"] <= int(json_data["maxCount"]):
for result in html_data:
selector = Selector(result)
for video in selector.css(".video_bx"):
title = video.css(".text").xpath("normalize-space()").get().strip()
link = video.css(".info_title::attr(href)").get()
thumbnail = video.css(".thumb_area img::attr(src)").get()
channel = video.css(".channel::text").get()
origin = video.css(".origin::text").get()
video_duration = video.css(".time::text").get()
views = video.css(".desc_group .desc:nth-child(1)::text").get()
date_published = video.css(".desc_group .desc:nth-child(2)::text").get()
video_results.append({
"title": title,
"link": link,
"thumbnail": thumbnail,
"channel": channel,
"origin": origin,
"video_duration": video_duration,
"views": views,
"date_published": date_published
})
params["start"] += 48
# update previous page to a new page
html = requests.get("https://s.search.naver.com/p/video/search.naver", params=params, headers=headers, timeout=30)
html_data = json.loads(html.text.replace("( {", "{").replace("]})", "]}"))["aData"]
| Code | Explanation |
|---|---|
while params["start"] <= int(json_data["maxCount"]) |
iterate until hits 1000 results which is a hard limit of ["maxCount"]
|
xpath("normalize-space()") |
to get blank text nodes since parsel translates every CSS query to XPath, and because XPath's text() ignores blank text nodes and gets first text element. |
::text or ::attr(href)
|
parsel own CSS pseudo-elements support which extracts text or attributes accordingly. |
params["start"] += 48 |
to increment to next page results: `48, 96, 144, 192 ... |
Output:
python
print(json.dumps(video_results, indent=2, ensure_ascii=False))
json
[
{
"title": "Minecraft : 🏰 How to build a Survival Castle Tower house",
"link": "https://www.youtube.com/watch?v=iU-xjhgU2vQ",
"thumbnail": "https://search.pstatic.net/common/?src=https%3A%2F%2Fi.ytimg.com%2Fvi%2FiU-xjhgU2vQ%2Fmqdefault.jpg&type=ac612_350",
"channel": "소피 Sopypie",
"origin": "Youtube",
"video_duration": "25:27",
"views": "126",
"date_published": "1일 전"
},
{
"title": "조금 혼란스러울 수 있는 마인크래프트 [ Minecraft ASMR Tower ]",
"link": "https://www.youtube.com/watch?v=y8x8oDAek_w",
"thumbnail": "https://search.pstatic.net/common/?src=https%3A%2F%2Fi.ytimg.com%2Fvi%2Fy8x8oDAek_w%2Fmqdefault.jpg&type=ac612_350",
"channel": "세빈 XEBIN",
"origin": "Youtube",
"video_duration": "00:58",
"views": "1,262",
"date_published": "2021.11.13."
}
]
Scrape all Naver Video Results with Browser Automation
`python
from playwright.sync_api import sync_playwright
import json
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://search.naver.com/search.naver?where=video&query=minecraft")
video_results = []
not_reached_end = True
while not_reached_end:
page.evaluate("""let scrollingElement = (document.scrollingElement || document.body);
scrollingElement.scrollTop = scrollingElement scrollHeight;""")
if page.locator("#video_max_display").is_visible():
not_reached_end = False
for index, video in enumerate(page.query_selector_all(".video_bx"), start=1):
title = video.query_selector(".text").inner_text()
link = video.query_selector(".info_title").get_attribute("href")
thumbnail = video.query_selector(".thumb_area img").get_attribute("src")
channel = None if video.query_selector(".channel") is None else video.query_selector(".channel").inner_text()
origin = video.query_selector(".origin").inner_text()
video_duration = video.query_selector(".time").inner_text()
views = video.query_selector(".desc_group .desc:nth-child(1)").inner_text()
date_published = None if video.query_selector(".desc_group .desc:nth-child(2)") is None else \
video.query_selector(".desc_group .desc:nth-child(2)").inner_text()
video_results.append({
"position": index,
"title": title,
"link": link,
"thumbnail": thumbnail,
"channel": channel,
"origin": origin,
"video_duration": video_duration,
"views": views,
"date_published": date_published
})
print(json.dumps(video_results, indent=2, ensure_ascii=False))
browser.close()
`
Lunch a Chromium browser and make a request:
`python
also supports async
with sync_playwright() as p:
# launches Chromium, opens a new page and makes a request
browser = p.chromium.launch(headless=False) # or firefox, webkit
page = browser.new_page()
page.goto("https://search.naver.com/search.naver?where=video&query=minecraft")
`
Create temporary list to store extracted data:
python
video_results = []
Create a while loop and check for exception to stop scrolling:
`python
not_reached_end = True
while not_reached_end:
# scroll to the bottom of the page
page.evaluate("""let scrollingElement = (document.scrollingElement || document.body);
scrollingElement.scrollTop = scrollingElement scrollHeight;""")
# break out of the while loop when hit the bottom of the video results
# looks for text at the bottom of the results:
# "Naver Search does not provide more than 600 video search results..."
if page.locator("#video_max_display").is_visible():
not_reached_end = False
`
| Code | Explanation |
|---|---|
page.evaluate() |
to run JavaScript expressions. You can also use playwright keyboard keys and shortcuts to do the same thing |
Iterate over scrolled results and append to temporary list:
`python
for index, video in enumerate(page.query_selector_all(".video_bx"), start=1):
title = video.query_selector(".text").inner_text()
link = video.query_selector(".info_title").get_attribute("href")
thumbnail = video.query_selector(".thumb_area img").get_attribute("src")
# return None if no result is displayed from Naver.
# "is None" used because query_selector() returns a NoneType (None) object:
# https://playwright.dev/python/docs/api/class-page#page-query-selector
channel = None if video.query_selector(".channel") is None else video.query_selector(".channel").inner_text()
origin = video.query_selector(".origin").inner_text()
video_duration = video.query_selector(".time").inner_text()
views = video.query_selector(".desc_group .desc:nth-child(1)").inner_text()
date_published = None if video.query_selector(".desc_group .desc:nth-child(2)") is None else \
video.query_selector(".desc_group .desc:nth-child(2)").inner_text()
video_results.append({
"position": index,
"title": title,
"link": link,
"thumbnail": thumbnail,
"channel": channel,
"origin": origin,
"video_duration": video_duration,
"views": views,
"date_published": date_published
})
`
| Code | Explanation |
|---|---|
enumerate() |
to get index position of each video |
query_selector_all() |
to return a list of matches. Default: []
|
query_selector() |
to return a single match. Default: None
|
Close browser instance after data has been extracted:
python
browser.close()
Output:
json
[
{
"position": 1,
"title": "Minecraft : 🏰 How to build a Survival Castle Tower house",
"link": "https://www.youtube.com/watch?v=iU-xjhgU2vQ",
"thumbnail": "https://search.pstatic.net/common/?src=https%3A%2F%2Fi.ytimg.com%2Fvi%2FiU-xjhgU2vQ%2Fmqdefault.jpg&type=ac612_350",
"channel": "소피 Sopypie",
"origin": "Youtube",
"video_duration": "25:27",
"views": "재생수126",
"date_published": "20시간 전"
},
{
"position": 1008,
"title": "Titanic [Minecraft] V3 | 타이타닉 [마인크래프트] V3",
"link": "https://www.youtube.com/watch?v=K39joThAoC0",
"thumbnail": "https://search.pstatic.net/common/?src=https%3A%2F%2Fi.ytimg.com%2Fvi%2FK39joThAoC0%2Fmqdefault.jpg&type=ac612_350",
"channel": "나이아Naia",
"origin": "Youtube",
"video_duration": "02:40",
"views": "재생수22",
"date_published": "2021.11.11."
}
]
Links
Outro
This blog post is for information purpose only. Use the received information for useful purposes, for example, if you know how to help improve Naver's service.
If you have anything to share, any questions, suggestions, or something that isn't working correctly, reach out via Twitter at @dimitryzub, or @serp_api.
Yours,
Dmitriy, and the rest of SerpApi Team.
Join us on Reddit | Twitter | YouTube
Add a Feature Request💫 or a Bug🐞

Top comments (0)