
Contents: intro, imports, what will be scraped, process, code, extracting all videos, links, outro.
Intro
This blog post was requested by Rosalex A and is a follow-up to the Bing web scraping series. Here you'll see how to scrape Video Results using Python with beautifulsoup, requests, lxml, and selenium libraries.
You'll see two approaches:
- scrape up to 10 video results with
beautifulsoup. - scrape all video results using
seleniumby scrolling to the end of search results.
Note: This blog post assumes that you're familiar with beautifulsoup, requests, and selenium libraries as well as have basic experience with CSS selectors.
Imports
from bs4 import BeautifulSoup
import requests, lxml
from selenium import webdriver
What will be scraped
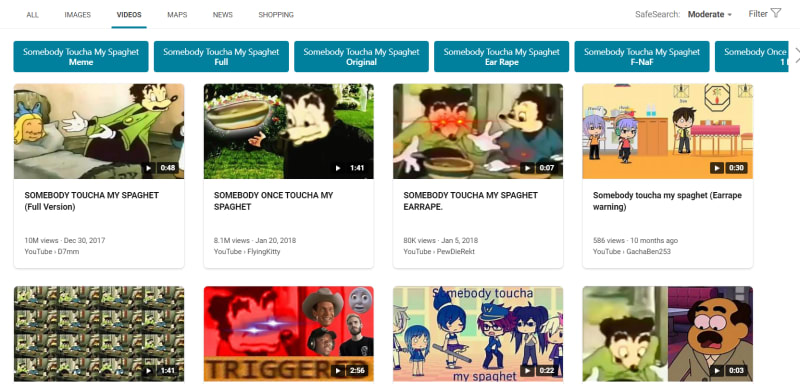
Process
Selecting CSS selectors for container, title, video url, number of views, channel name, platform, date published. CSS selectors reference.

Code
from bs4 import BeautifulSoup
import requests, lxml
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36"
}
params = {
"q": "somebody toucha my spaghet",
"cc": "us" # language/country of the search
}
html = requests.get('https://www.bing.com/videos/search', params=params, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
for result in soup.select('.mc_vtvc.b_canvas'):
title = result.select_one('.b_promtxt').text
link = f"https://www.bing.com{result.select_one('.mc_vtvc_link')['href']}"
views = result.select_one('.mc_vtvc_meta_row:nth-child(1) span:nth-child(1)').text
date = result.select_one('.mc_vtvc_meta_row:nth-child(1) span+ span').text
video_platform = result.select_one('.mc_vtvc_meta_row+ .mc_vtvc_meta_row span:nth-child(1)').text
channel_name = result.select_one('.mc_vtvc_meta_row_channel').text
print(f'{title}\n{link}\n{channel_name}\n{video_platform}\n{date}\n{views}\n')
----------------------
'''
THE THREE BEARS (1939)
https://www.bing.comhttps://www.bilibili.com/video/av18046604/
fibration
bilibili
Jan 7, 2018
566 views
SOMEBODY TOUCHA MY SPAGHET - Harmonised
https://www.bing.com/videos/search?q=somebody+toucha+my+spaghet&&view=detail&mid=A98F1E15564EFBCDA08EA98F1E15564EFBCDA08E&&FORM=VRDGAR
Mirron
YouTube
Jun 16, 2020
12K views
...
'''
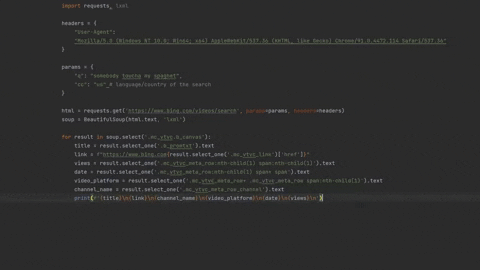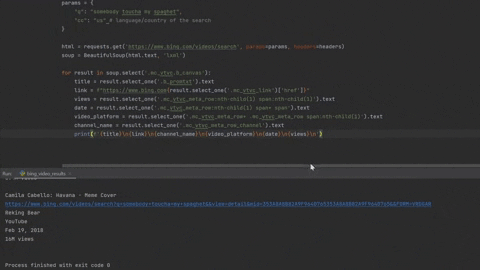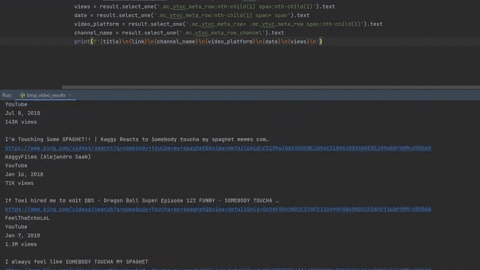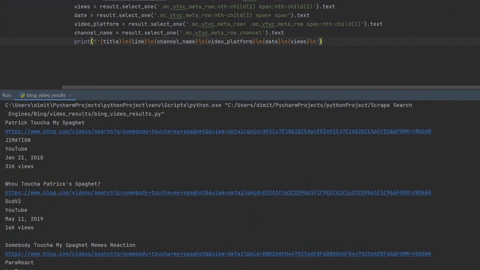
Extracting all videos
To extract all videos we need to scroll the page downwards, then click on the button when it appears and scroll down again to the end of video results.
To scroll down with Selenium you can use .send_keys() method.
driver.find_element_by_xpath('xpath').send_keys(Keys.KEYBOARD_KEY)
# in our case .send_keys(Keys.END) to scroll to the bottom of the page
You can also execute script by calling the DOM as I did in YouTube Search web scraping series, but it didn't work for me in this situation, or I was doing something wrong.
driver.execute_script("var scrollingElement = (document.scrollingElement || document.body);scrollingElement.scrollTop = scrollingElement.scrollHeight;")
# https://stackoverflow.com/a/57076690/15164646 (contains several references)
Then, clicking. To click you have only one option: .click() method.
driver.find_element_by_css_selector('.selector').click()
Full code to extract all video results
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome(executable_path='path/to/chromedriver.exe')
driver.get('https://www.bing.com/videos/search?q=somebody+toucha+my+spaghet&FORM=HDRSC3&cc=us')
time.sleep(1)
# scrolls until "more videos" button is located
while True:
# return False
end_result = driver.find_element_by_xpath('//*[@id="bop_coll"]').is_displayed()
driver.find_element_by_xpath('//*[@id="b-scopeListItem-video"]/a').send_keys(Keys.END)
# when returns True, breaks out of the while loop
if end_result == True:
break
# wait for button to load, clicks on "more videos" button and continues code execution
time.sleep(2)
driver.find_element_by_css_selector('.mBtn').click()
# scrolls until the end of the video result with 60 retries buffer to break out of the while loop.
# this block of code works but could be better implemented.
# if you know a better solution, please, write in the comments below and I'll change this section to a better one.
# https://stackoverflow.com/a/34885906/15164646
tries = 60
for i in range(tries):
while True:
try:
driver.find_element_by_xpath('//*[@id="b-scopeListItem-video"]/a').send_keys(Keys.END)
except:
if i < tries - 1:
continue
else:
raise
break
# when 2 while loops executed it will iterate over every found element
# try/except used because sometimes there are no such elements being displayed
for index, result in enumerate(driver.find_elements_by_css_selector('.mc_vtvc.b_canvas')):
title = result.find_element_by_css_selector('.b_promtxt').text
link = f"https://www.bing.com{result.find_element_by_css_selector('.mc_vtvc_link').get_attribute('href')}"
try:
views = result.find_element_by_css_selector('.mc_vtvc_meta_row:nth-child(1) span:nth-child(1)').text
except:
views = None
try:
date = result.find_element_by_css_selector('.mc_vtvc_meta_row:nth-child(1) span+ span').text
except:
date = None
try:
video_platform = result.find_element_by_css_selector('.mc_vtvc_meta_row+ .mc_vtvc_meta_row span:nth-child(1)').text
except:
video_platform = None
try:
channel_name = result.find_element_by_css_selector('.mc_vtvc_meta_row_channel').text
except:
channel_name = None
print(f'{index}\n{title}\n{link}\n{channel_name}\n{video_platform}\n{date}\n{views}\n')
driver.quit()
----------------------------
'''
1 # first element result
SOMEBODY ONCE TOUCHA MY SPAGHET
https://www.bing.comhttps://www.bing.com/videos/search?q=somebody+toucha+my+spaghet&&view=detail&mid=894647969BE1D540909A894647969BE1D540909A&&FORM=VRDGAR
FlyingKitty
YouTube
Jan 20, 2018
8.2M views
...
594 # last element result
BEST MEMES COMPILATION #49
https://www.bing.comhttps://www.bing.com/videos/search?q=somebody+toucha+my+spaghet&&view=detail&mid=05F78AB366F6D32E579305F78AB366F6D32E5793&&FORM=VRDGAR
H-Matter
YouTube
1 week ago
318K views
'''

The GIF is sped up by a 1550%
Links
GitHub Gist for first 10 results • GitHub Gist for all video results
Outro
Selenium isn't the fastest solution, but it gives an ability to scroll until no more results are shown. Other steps might be to add async functionality to this code.
If you have any questions or something isn't working correctly or you want to write something else, feel free to drop a comment in the comment section or via Twitter at @serp_api.
Yours,
Dimitry, and the rest of SerpApi Team.





Top comments (5)
Hi good job but i wanted to ask you why you prefer select to find with beautifulsoup ? Select is more advantageous ?
Hey, Rosalex!
.select()/.select_one()methods are more readable. For example if you want to chain the following selectors with.find()/.find_all()methods it would look not very readable:soup.select("div[id=foo] > div > div > div[class=fee] > span > span > a"You can read more about CSS selectors on bs4 documentation and on soupsieve documentation which is CSS selector library designed to be used with Beautiful Soup.
In short, I just used to using them :)
--- D.
Ok I understand better thank you for this explanation
Without transition I would like to know if there exists on python a module like pytrends for bing which allows to find the popularity of a word
The short answer is I don't know. Haven't seen anything like this for Bing anywhere.
Since Bing Toolbox is the only option I see at the moment which requires sing-ups and all sorts of other stuff which Google Trends doesn't require, it becomes a much harder process.
Ok thanks