
Data is an important part of our world. In fact, 90% of the world’s data was created in just the last 3 years. Many tech giants have started hiring data scientists to analyze data for business decisions. Data analysis is a method where we collect data, and then various operations, such as normalizing, transforming, cleaning, etc. are applied to our data to extract useful information. Data analysis is currently in high-demand, as companies large and small seek out these valuable skills.
Currently, Python is the most important language for data analysis, and many of the industry-standard tools are written in Python. Python Pandas is one of the most essential, in-demand tools that any aspiring data analysts need to learn. In this post, we’ll introduce you to the essentials of Pandas.
Today we’ll go over:
- Introducing Pandas for Python
- Pandas Data Types and Structures
Series: the most important operationsDataFrame: the most important operations- How to read and import Pandas data
- Data Wrangling with Pandas
- Next steps
Start your career as a data analyst.
Learn how to perform predictive data analysis using Python tools.
Predictive Data Analysis with Python
Introducing Pandas for Python
The Pandas library is one of the most important and popular tools for Python data scientists and analysts, as it is the backbone of many data projects. Pandas is an open-source Python package for data cleaning and data manipulation. It provides extended, flexible data structures to hold different types of labeled and relational data. On top of that, it is actually quite easy to install and use.
Pandas is often used in conjunction with other Python libraries. In fact, Pandas is built on the NumPy package, so a lot of the structure between them is similar. Pandas is also used in SciPy for statistical analysis or with Matplotlib for plotting functions. Pandas can be used on its own with a text editor or with Juptyer Notebooks, the ideal environment for more complex data modeling. Pandas is available for most versions of Python, including Python3.
Think of Pandas as the home for your data where you can clean, analyze, and transform your data, all in one place. Pandas is essentially a more powerful replacement for Excel. Using Pandas, you can do things like:
- Easily calculate statistics about data such as finding the average, distribution, and median of columns
- Use data visualization tools, such as Matplotlib, to easily create plot bars, histograms, and more
- Clean your data by filtering columns by particular criteria or easily removing values
- Manipulate your data flexibly using operations like merging, joining, reshaping, and more
- Read, write, and store your clean data as a database,
txtfile, orCSVfile
Popularity of Pandas
As we learned, Python is the most popular programming language for data analytics, and many of the popular machine learning and visualization libraries are written in Python, including Pandas, Numpy, TensorFlow, Matplotlib, Scikit-learn, and more. In fact, Python ranked 4th in the 2020 StackOverflow survey for the most popular programming language, and it is beloved for its simplicity, easy learning-curve, and improved library support.
Pandas is an important part of data analytics. It ranks 4th for most popular and loved libraries. It also consistently ranks highly for most wanted programming tools, a sure sign that Pandas is a sought-after tool for developers around the world. Learning Pandas is an important step to becoming a data analyst.
First Step: Installing Pandas
Pandas is quite easy to install. The easiest way is to open your command line (PC) or terminal program (Mac) and install it using the following command to import the pandas features.
import pandas as pd
Pandas is now accessible with the acronym
pd.
You can also install Pandas using the built-in Python tool pip and run the following command.
$ pip install pandas
Pandas Data Structures and Data Types
A data type is like an internal construct that determines how Python will manipulate, use, or store your data. When doing data analysis, it’s important to use the correct data types to avoid errors. Pandas will often correctly infer data types, but sometimes, we need to explicitly convert data. Let’s go over the data types available to us in Pandas, also called dtypes.
-
object: text or mixed numeric or non-numeric values -
int64: integer numbers -
bool: true/false vaues -
float64: floating point numbers -
category: finite list of text values -
datetime64: Date and time values -
timedelta[ns]: differences between two datetimes
A data structure is a particular way of organizing our data. Pandas has two data structures, and all operations are based on those two objects:
SeriesDataFrame
Think of this as a chart for easy storage and organization, where Series are the columns, and the DataFrame is a table composed of a collection of series. Series can be best described as the single column of a 2-D array that can store data of any type. DataFrame is like a table that stores data similar to a spreadsheet using multiple columns and rows. Each value in a DataFrame object is associated with a row index and a column index.
Series: the most important operations
We can get started with Pandas by creating a series. We create series by invoking the pd.Series() method and then passing a list of values.
We print that series using the print statement. Pandas will, by default, count index from 0. We then explicitly define those values.
series1 = pd.Series([1,2,3,4])
print(series1)
Let’s look at a more complex example. Run the code below.
#importing pandas in our program
import pandas as pd
# Defining a series object
srs = pd.Series([11.9, 36.0, 16.6, 21.8, 34.2], index = ['China', 'India', 'USA', 'Brazil', 'Pakistan'])
# Set Series name
srs.name = "Growth Rate"
# Set index name
srs.index.name = "Country"
# printing series values
print("The Indexed Series values are:")
print(srs)
Output:
The Indexed Series values are:
Country
China 11.9
India 36.0
USA 16.6
Brazil 21.8
Pakistan 34.2
Name: Growth Rate, dtype: float64
How does this work? Two attributes of the Series object are used on line 8 and line 11. The attribute srs.name sets the name of our series object. The attribute srs.index.name then sets the name for the indexes. Pretty simple, right?
Select entries from a Series
To select entries from a Series, we select elements based on the index name or index number. This uses NumPy.
import numpy as np
import pandas as pd
srs = pd.Series(np.arange(0, 6, 1), index = ['ind0', 'ind1', 'ind2', 'ind3', 'ind4', 'ind5'])
srs.index.name = "Index"
print("The original Series:\n", srs)
print("\nSeries element at index ind3:")
print(srs['ind3']) # Fetch element at index named ind3
print("\nSeries element at index 3:")
print(srs[3]) # Fetch element at index 3
print("\nSeries elements at multiple indexes:\n")
print(srs[['ind1', 'ind4']]) # Fetch elements at multiple indexes
Output:
('The original Series:\n', Index
ind0 0
ind1 1
ind2 2
ind3 3
ind4 4
ind5 5
dtype: int64)
How does that work? Well, the elements from the Series are selected in 3 ways.
- On line 9, the element is selected based on the index name.
- On line 12, the element is selected based on the index number. Keep in mind that index numbers start from
0. - On line 15, multiple elements are selected from the
Seriesby selecting multiple index names inside the[].
Drop entries from a Series
Dropping and unwanted index is a common function in Pandas. If the drop(index_name) function is called with a given index on a Series object, the desired index name is deleted.
import numpy as np
import pandas as pd
srs = pd.Series(np.arange(0, 6, 1), index = ['ind0', 'ind1', 'ind2', 'ind3', 'ind4', 'ind5'])
srs.index.name = "Index"
print("The original Series:\n", srs)
srs = srs.drop('ind2') # drop index named ind2
print("The New Series:\n", srs)
Here, the output that the ind2 index is dropped. Also, an index can only be dropped by specifying the index name and not the number. So, srs.drop(srs[2]) does not work.
Pretty simple, right? There are many other functions, conditions, and logical operators we can apply to our series object to make productive use of indexes. Some of those functions are:
- The condition
srs[srs == 1.0]will return a series object containing indexes with values equal to 1.0. -
name : str, optionalgives a name to the Series -
copy : bool, default Falseallows us to copy data we input - The
notnull()function will return a series object with indexes assigned toFalse(forNaNvalues), and the remaining indexes are assignedTrue - and much more
Note: In Pandas,
NaNrefers to null values. This usually occurs for values not yet determined or defined. We can deal withNaNvalues by assigning values to them in our data.
DataFrame: the most important operations
There are several ways to make a DataFrame in Pandas. The easiest way to create one from scratch is to create and print a df.
import pandas as pd
df = pd.DataFrame({
"Column1": [1, 4, 8, 7, 9],
"Column2": ['a', 'column', 'with', 'a', 'string'],
"Column3": [1.23, 23.5, 45.6, 32.1234, 89.453],
"Column4": [True, False, True, False, True]
})
print(df)
Output:
Column1 Column2 Column3 Column4
0 1 a 1.2300 True
1 4 column 23.5000 False
2 8 with 45.6000 True
3 7 a 32.1234 False
4 9 string 89.4530 True
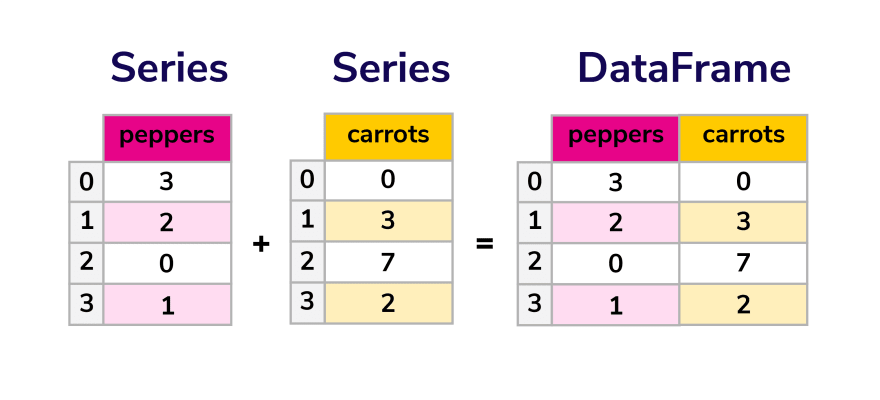
We can also create a dict and pass our dictionary data to the DataFrame constructor. Say we have some data on vegetable sales and want to organize it by type of vegetable and quantity. Our data would look like this:
data = {
'peppers': [3, 2, 0, 1],
'carrots': [0, 3, 7, 2]
}
And now we pass it to the constructor using a simple command.
quantity = pd.DataFrame(data)
quantity
How did that work?
Well, each item, or value, in our data will correspond with a column in the DataFrame we created, just like a chart. The index for this DataFrame is listed as numbers, but we can specify them further depending on our needs. Say we wanted to know quantity per month. That would be our new index. We do that using the following command.
quantity = pd.DataFrame(data, index=['June', 'July', 'August', 'September'])
quantity
Get info about your data
One of the first commands you run after loading your data is .info(), which provides all the essential information about a dataset.
import pandas as pd
df = pd.DataFrame({
"Column1": [1, 4, 8, 7, 9],
"Column2": ['a', 'column', 'with', 'a', 'string'],
"Column3": [1.23, 23.5, 45.6, 32.1234, 89.453],
"Column4": [True, False, True, False, True]
})
df.info()
Output:
RangeIndex: 5 entries, 0 to 4
Data columns (total 4 columns):
Column1 5 non-null int64
Column2 5 non-null object
Column3 5 non-null float64
Column4 5 non-null bool
dtypes: bool(1), float64(1), int64(1), object(1)
memory usage: 197.0+ bytes
From that, you can access more information with other operations, like .shape, which outputs a tuple of (rows, columns). This is super useful for telling us the size of our data, especially after we’ve cleaned it. That way, we can know what was removed.
We can also print a dataset's column names to find typos or formatting inconsistencies. We use the .columns operator to do so. You can then rename your columns easily. On top of that, the .rename() method allows us to rename columns, similar to a Search and Replace function of a Word doc.
Searching and selecting in our DataFrame
We also need to know how to manipulate or access the data in our DataFrame, such as selecting, searching, or deleting data values. You can do this either by column or by row. Let’s see how it’s done. The easiest way to select a column of data is by using brackets [ ]. We can also use brackets to select multiple columns. Say we only wanted to look at June’s vegetable quantity.
quantity.loc['June']
Note:
locandilocare used for locating data.
.iloclocates by numerical index.loclocates by the index name. This is similar tolistslicing in Python.
Pandas DataFrame object also provides methods to select specific columns. The following example shows how it can be done.
import pandas as pd
df = pd.read_csv('cancer_stats.csv')
print(df.columns) # print columns of DataFrame
print("\nThe First Column")
print(df['Sex'].head()) # Fetch the sex colum from DataFrame
print("\nThe type of this column is: " + str(type(df['Sex'])) + "\n")
print("\nThe Second Column")
print(df['Under 1'].head()) # Fetch the Under 1 colum from DataFrame
print("\nThe type of this column is: " + str(type(df['Under 1'])) + "\n")
print("\nThe Last Column")
print(df['40-44'].head()) # Fetch the 40-44 colum from DataFrame
print("\nThe type of this column is: " + str(type(df['40-44'])) + "\n")
Output:
Index([u'Sex', u'Under 1', u'1-4', u'5-9', u'10-14', u'15-19', u'20-24',
u'25-29', u'30-34', u'35-39', u'40-44'],
dtype='object')
The First Column
0 Males
1 Females
2 Males
3 Females
On line 5, the df.columns function displays the names of all columns present. We access a column by its name. On lines 8, 12, and 17, df['column_name'] is used to get the 1st, 2nd, and last column.
Keep the learning going.
Learn Pandas and Data Analysis without scrubbing through videos or documentation. Educative's text-based courses are easy to skim and feature live coding environments, making learning quick and efficient.
Create a new DataFrame from pre-existing columns
We can also grab multiple columns and create a new DataFrame object from it.
import pandas as pd
df = pd.read_csv('test.csv')
print(df.columns)
print("\nThe original DataFrame:")
print(df.head())
print("\nThe new DataFrame with selected columns is:\n")
new_df = pd.DataFrame(df, columns=['Sex', 'Under 1', '40-44'])
print(new_df.head())

Reindex data in a DataFrame
We can also reindex the data either by the indexes themselves or the columns. Reindexing with reindex() allows us to make changes without messing up the initial setting of the objects.
Note: The rules for reindexing are the same for
SeriesandDataFrameobjects.
#importing pandas in our program
import pandas as pd
# Defining a series object
srs1 = pd.Series([11.9, 36.0, 16.6, 21.8, 34.2], index = ['China', 'India', 'USA', 'Brazil', 'Pakistan'])
# Set Series name
srs1.name = "Growth Rate"
# Set index name
srs1.index.name = "Country"
srs2 = srs1.reindex(['China', 'India', 'Malaysia', 'USA', 'Brazil', 'Pakistan', 'England'])
print("The series with new indexes is:\n",srs2)
srs3 = srs1.reindex(['China', 'India', 'Malaysia', 'USA', 'Brazil', 'Pakistan', 'England'], fill_value=0)
print("\nThe series with new indexes is:\n",srs3)
Output:
('The series with new indexes is:\n', Country
China 11.9
India 36.0
Malaysia NaN
USA 16.6
Brazil 21.8
Pakistan 34.2
England NaN
Name: Growth Rate, dtype: float64)
('\nThe series with new indexes is:\n', Country
China 11.9
India 36.0
Malaysia 0.0
USA 16.6
Brazil 21.8
Pakistan 34.2
England 0.0
Name: Growth Rate, dtype: float64)
How did that work? Well, on line 11, the indexes are changed. The new index name is added between Row2 and Row4. One line 14, the columns keyword should be specifically used to reindex the columns of DataFrame. The rules are the same as for the indexes. NaN values were assigned to the whole column by default.

How to read or import Pandas data
It is quite easy to read or import data from other files using the Pandas library. In fact, we can use various sources, such as CSV, JSON, or Excel to load our data and access it. Let’s take a look at each.
Reading and importing data from CSV files
We can import data from a CSV file, which is common practice for Pandas users. We simply create or open our CSV file, copy the data, paste it in our Notepad, and save it in the same directory that houses your Python scripts. You then use a bit of code to read the data using the read_csv function build into Pandas.
import pandas as pd
data = pd.read_csv('vegetables.csv')
print(data)
read_csv will generate the index column as a default, so we need to change this for the first column is the index column. We can do this by passing the parameter index_col to tell Pandas which column to index.
data = pd.read_csv("data.csv", index_col=0)
Once we’ve used Pandas to sort and clean data, we can then save it back as the original file with simple commands. You only have to input the filename and extension. How simple!
df.to_csv('new_vegetables.csv')
Reading and importing data from JSON
Say you have a JSON file. A JSON file is basically like a stored Python dict, so Pandas can easily access and read it using the read_json function. Let’s look at an example.
df = pd.read_json('purchases.json')
Just like with CSV files, once we’ve used Pandas to sort and clean data, we can then save it back as the original file with simple commands. You only have to input the filename and extension.
df.to_json('new_purchases.json')
Reading and importing data from Excel file
Say you have an Excel file. You can similarly use the read_excel function to access and read that data.
import pandas as pd
data = pd.read_excel('workers.xlsx')
print (data)
Once we call the read_excel function, we pass the name of the Excel file as our argument, so read_excel will open the file’s data. We can the print() to display the data. If we want to go one step further, we can add the loc() method from earlier, allowing us to read specific rows and columns of our file.
import pandas as pd
data = pd.read_excel('workers.xlsx')
print (data.loc[[1,4,7],['Name','Salary']])

Data Wrangling with Pandas
Once we have our data, we can use data wrangling processes to manipulate and prepare data for the analysis. The most common data wrangling processes are merging, concatenation, and grouping. Let’s get down the basics of each of those.
Merging with Pandas
Merging is used when we want to collect data that shares a key variable but are located in different DataFrames. To merge DataFrames, we use the merge() function. Say we have df1 and df2.
import pandas as pd
d = {
'subject_id': ['1', '2', '3', '4', '5'],
'student_name': ['Mark', 'Khalid', 'Deborah', 'Trevon', 'Raven']
}
df1 = pd.DataFrame(d, columns=['subject_id', 'student_name'])
print(df1)
import pandas as pd
data = {
'subject_id': ['4', '5', '6', '7', '8'],
'student_name': ['Eric', 'Imani', 'Cece', 'Darius', 'Andre']
}
df2 = pd.DataFrame(data, columns=['subject_id', 'student_name'])
print(df2)
So, how do we merge them? It’s simple: with the merge() function!
pd.merge(df1, df2, on='subject_id')
Grouping with Pandas
Grouping is how we categorize our data. If a value occurs in multiple rows of a single column, the data related to that value in other columns can be grouped together. Just like with merging, it’s more simple than it sounds. We use the groupby function. Look at this example.
# import pandas library
import pandas as pd
raw = {
'Name': ['Darell', 'Darell', 'Lilith', 'Lilith', 'Tran', 'Tran', 'Tran',
'Tran', 'John', 'Darell', 'Darell', 'Darell'],
'Position': [2, 1, 1, 4, 2, 4, 3, 1, 3, 2, 4, 3],
'Year': [2009, 2010, 2009, 2010, 2010, 2010, 2011, 2012, 2011, 2013, 2013, 2012],
'Marks':[408, 398, 422, 376, 401, 380, 396, 388, 356, 402, 368, 378]
}
df = pd.DataFrame(raw)
group = df.groupby('Year')
print(group.get_group(2011))
Output:
Marks Name Position Year
6 396 Tran 3 2011
8 356 John 3 2011
Concatenation
Concatenation is a long word that means to add a set of data to another. We use the concat() function to do so. To clarify the difference between merge and concatenation, merge() combines data on shared columns, while concat() combines DataFrames across columns or rows.
print(pd.concat([df1, df2]))
Pretty simple, right? Some other common data wrangling processes that you should know are:
- Mapping data and finding duplicates
- Finding outliers in data
- Data Aggregation
- Reshaping data
- Replace & rename
- and more
Wrapping up and next steps
Now that you have a good sense of Python Pandas and the countless benefits it offers, it’s important to know what to learn next. Once you get down the basics, like how to import, read, and wrangle your data, it’s time to tackle the next stage of data analysis for Python:
- Statistics
- NumpPy
- Advanced data wrangling
- Visualizations for data
- Data scraping
- Real-world projects
Educative’s course Predictive Data Analysis for Python covers all these concepts and more with hands-on practice and industry-standard examples. You can master Pandas through quizzes, interactive examples, and real behavior analysis. By the end, you'll be a confident data analyst!




Top comments (0)