
This article was written for Pathrise, an online mentorship program that works with students and professionals on every component of their job search.
Scikit-learn is the most popular Python machine learning library for data science. Learn the top tips and tricks to take your Scikit skills to the next level.
Scikit-learn (also called sklearn) is the most popular Python machine learning library for data science. Any data scientist or machine learning engineer needs Scikit in their tool belt. For many big companies, like J.P. Morgan, Spotify, Hugging Face, and more, Scikit-learn is an indispensable part of their product development.
Understanding this tool can open doors for employment in the data science world and help you land a data science job more easily.
Sklearn provides flexible tools for learning, improving, and executing our machine learning models. This article will take your Sklearn skills to the next level with some insider tips and tricks. These best practices will excel your machine learning skills and make your programming life easier.
Today we will cover the following 5 best practices and tricks:
- Imputing missing values with iterative imputer
- Generating random dummy data
- Using Pickle for model persistence
- Plotting a confusion matrix
- Creating visualizations for decision trees
- What to learn next
1. Imputing missing values with iterative imputer
When a dataset has missing values, many problems in an ML algorithm can occur. In each column, we need to identify and replace missing values before we model prediction tasks. This process is called data imputation.
It’s easy to stick with traditional methods for imputing missing values, like mode (for classification) or the mean/median (for regression). But Sklearn provides more powerful, simpler ways to impute missing values.
In Sklearn, the IterativeImputer class allows us to use an entire set of features to locate and eliminate missing values. In fact, it is specifically designed to estimate missing values by taking them as a function of other features.
This approach repeatedly defines a model to predict missing features as a function of other features. This improves our dataset with each iteration.
To use this built-in iterative imputation feature, you must import enable_iterative_imputer, since it is still in the experimental phase.
>>> # explicitly require this experimental feature
>>> from sklearn.experimental import enable_iterative_imputer
>>> # now you can import normally from sklearn.impute
>>> from sklearn.impute import IterativeImputer
Take a look at this code example below to see how simple IterativeImputer is. With this code, any missing values in a dataframe will be filled in a new dataframe called impute_df.
We set the number of iterations and verbosity, which is optional. The imputer is fitted to the dataset that has missing values, generating our new dataframe.
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
df = pd.DataFrame(*a dataset with missing values that we want to impute*)
imp = IterativeImputer(max_iter=10, verbose=0)
imp.fit(df)
impute_df = imp.transform(df)
impute_df = pd.DataFrame(impute_df, columns=df.columns)
2. Generating random dummy data
Dummy data refers to datasets that do not contain useful data. Instead, they reserve space where real or useful data should be present. Dummy data is a placeholder for testing, so it must be evaluated carefully to prevent unintended results.
Sklearn makes it easy to generate reliable dummy data. We simply use the functions make_classification() for classification data or make_regression() for regression data. You’ll also want to set the parameters, like the number of samples and features.
These functions give us control over the behavior of your data, so we can easily debug or test on small datasets.
Look at the code example below with 1,000 samples and 20 features.
Look at the code example below with 1,000 samples and 20 features.
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=20)
3. Using Pickle for model persistence
Model resistance allows us to reuse an ML model without retraining it. Sklearn’s Pickle model allows us to reuse a model and achieve model persistence. Once you save a model as a Pickle, it can be easily loaded later at any time for more predictions.
To serialize your algorithms and save them, you can use either the pickle or joblib Python libraries. Take a look at the code example below.
import pickle
# Save a KNN model
saved_model = pickle.dumps(knn)
# Load a saved KNN model
load_model = pickle.loads(saved_model)
# Make new predictions from a pickled model
load_model.predict(test_X)
4. Plotting a confusion matrix
A confusion matrix is a table that describes a classifier’s performance for test data. Sklearn’s most recent release adds the function plot_confusion_matrix to generate an accessible and customizable confusion matrix that maps our true positive, false positive, false negative, and true negative values.
Take a look at this code example from the Sklearn documentation.
>>> from sklearn.metrics import confusion_matrix
>>> y_true = [2, 0, 2, 2, 0, 1]
>>> y_pred = [0, 0, 2, 2, 0, 2]
>>> confusion_matrix(y_true, y_pred)
array([[2, 0, 0],
[0, 0, 1],
[1, 0, 2]])
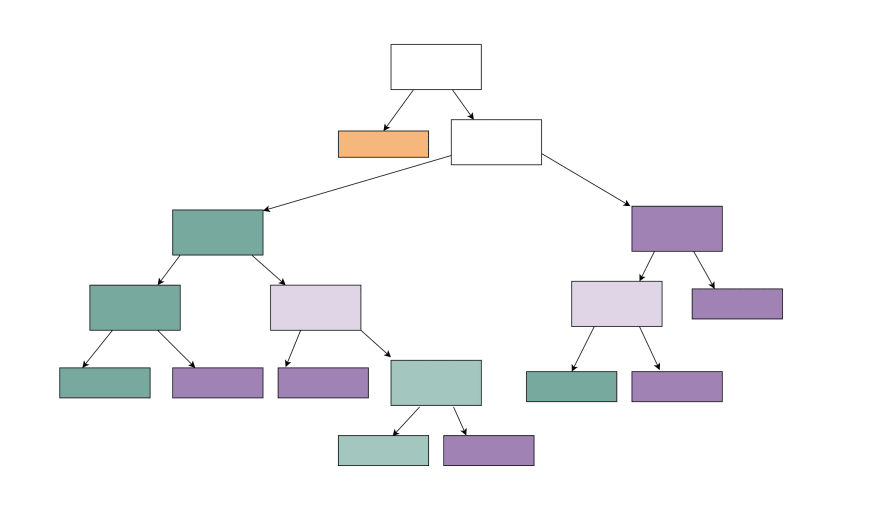
5. Creating visualizations for decision trees
The decision tree is one of the most popular classification algorithms for data science. In this algorithm, the training model learns to predict values of the target variable by learning decision rules with a tree representation. A tree is made up of nodes with corresponding attributes.
We can now visualize decision trees with matplotlib using tree.plot_tree. This means you don’t have to install any dependencies to create simple visualizations. You can then save your tree as a .png file for easy access.
Take a look at this example from the Sklearn documentation. The example visual decision tree should give you the basic structure of what Scikit-learn generates (see the official documentation for further details).
tree.plot_tree(clf)
What to learn next
Congrats! You’ve now learned a lot more about Sklearn and are ready to take your machine learning skills to the next level. There is still a lot to learn about Scikit to get the most out of this powerful library.
A good next step is to explore more Scikit tricks, learn Seaborn and Keras, and take an online course to solidify your learning.
Educative’s course Hands-on Machine Learning with Scikit-learn will help you dive deeper into linear regression, logistic regression, k-means clustering, and more. By the end, you’ll be able to confidently use Sklearn in your own projects.
Or, if you are ready for more advanced content, check out Educative’s course Grokking the Machine Learning Interview to learn how to apply ML concepts to real-world system design situations that you can expect in an ML interview.
Happy learning!





Top comments (2)
concise and well wrtitten article. kudos
Great article. One small correction, pickle is a Python module, no scikit-learn's.