
Intro
Currently, we don't have an API that supports extracting data from Brave Search.
This blog post is to show you way how you can do it yourself with provided DIY solution below while we're working on releasing our proper API.
The solution can be used for personal use as it doesn't include the Legal US Shield that we offer for our paid production and above plans and has its limitations such as the need to bypass blocks, for example, CAPTCHA.
You can check our public roadmap to track the progress for this API: [New API] Brave Search
What will be scraped
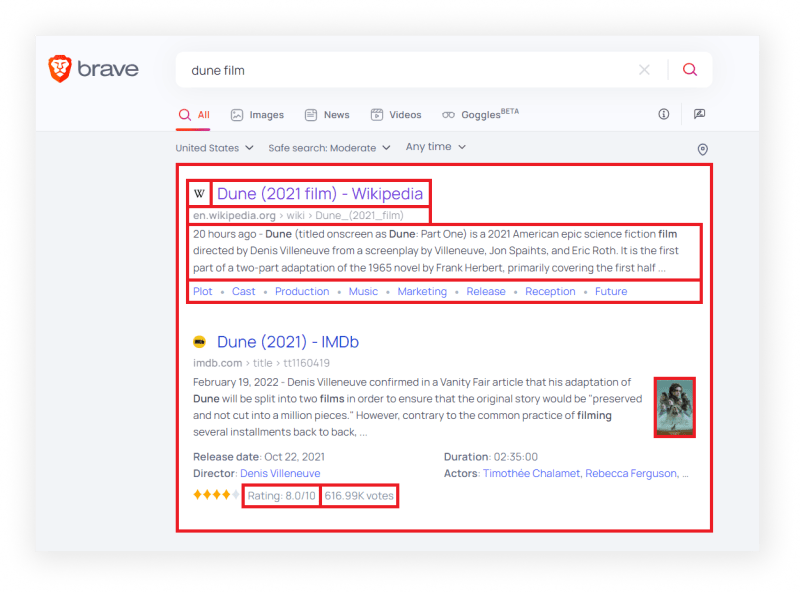
📌Note: Some results may be missing data such as rating, votes, images in snippet, and links to sites.
What is Brave Search
TL;DR
Privacy consumer tech market is growing fast. If you're tracking you website position in other search engines then you can take advantage of this growing market.
Brave Search is offering users independent privacy search alternatives to other big search engines. Brave doesn't want to replace Google or Bing search engines as Josep M. Pujol, chief of search at Brave said: "We need more choices, not to replace Google or Bing, but to offer alternatives."
Brave search is faster compare to Chrome because it (Brave Browser) blocks ads and trackers which speed up page load time, and it respect user privacy, and the only independent search engine. In other words, it has its own index, which it also gives it independence from other search providers.
As Brendan Eich, CEO and co-founder of Brave said: "Brave Search offers a new way to get relevant results with a community-powered index, while guaranteeing privacy.".
But wait, there's DuckDuckGo already. Since this blog post mainly focuses on scraping data, you can have a look at differences in focused on that topic articles:
- Brave VS DuckDuckGo – Which one is Best for Privacy
- Brave vs Duckduckgo: A Detailed Review and Comparison
Full Code
If you don't need explanation, have a look at full code example in the online IDE.
from bs4 import BeautifulSoup
import requests, lxml, json
def get_organic_results():
# https://docs.python-requests.org/en/master/user/quickstart/#passing-parameters-in-urls
params = {
'q': 'dune film', # query
'source': 'web', # source
'tf': 'at', # publish time (by default any time)
'offset': 0 # pagination (start from page 1)
}
# https://docs.python-requests.org/en/master/user/quickstart/#custom-headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
brave_organic_search_results = []
while True:
html = requests.get('https://search.brave.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
if soup.select_one('.ml-15'):
params['offset'] += 1
else:
break
page = {}
page['page'] = params['offset']
page['items'] = []
for result in soup.select('.snippet'):
title = result.select_one('.snippet-title').get_text().strip()
favicon = result.select_one('.favicon').get('src')
link = result.select_one('.result-header').get('href')
displayed_link = result.select_one('.snippet-url').get_text().strip().replace('\n', '')
snippet = result.select_one('.snippet-content .snippet-description , .snippet-description:nth-child(1)').get_text()
snippet = snippet.strip().split('\n')[-1].lstrip() if snippet else None
snippet_image = result.select_one('.video-thumb img , .thumb')
snippet_image = snippet_image.get('src') if snippet_image else None
rating_and_votes = result.select_one('.ml-10')
rating = rating_and_votes.get_text().strip().split(' - ')[0] if rating_and_votes else None
votes = rating_and_votes.get_text().strip().split(' - ')[1] if rating_and_votes else None
sitelinks_container = result.select('.deep-results-buttons .deep-link')
sitelinks = None
if sitelinks_container:
sitelinks = []
for sitelink in sitelinks_container:
sitelinks.append({
'title': sitelink.get_text().strip(),
'link': sitelink.get('href')
})
page['items'].append({
'title': title,
'favicon': favicon,
'link': link,
'displayed_link': displayed_link,
'snippet': snippet,
'snippet_image': snippet_image,
'rating': rating,
'votes': votes,
'sitelinks': sitelinks
})
brave_organic_search_results.append(page)
print(json.dumps(brave_organic_search_results, indent=2, ensure_ascii=False))
if __name__ == "__main__":
get_organic_results()
Preparation
Install libraries:
pip install requests lxml beautifulsoup4
Basic knowledge scraping with CSS selectors
CSS selectors declare which part of the markup a style applies to thus allowing to extract data from matching tags and attributes.
If you haven't scraped with CSS selectors, there's a dedicated blog post of mine about how to use CSS selectors when web-scraping that covers what it is, pros and cons, and why they're matter from a web-scraping perspective.
Reduce the chance of being blocked
Make sure you're using request headers user-agent to act as a "real" user visit. Because default requests user-agent is python-requests and websites understand that it's most likely a script that sends a request. Check what's your user-agent.
There's a how to reduce the chance of being blocked while web scraping blog post that can get you familiar with basic and more advanced approaches.
Code Explanation
Import libraries:
from bs4 import BeautifulSoup
import requests, lxml, json
| Library | Purpose |
|---|---|
BeautifulSoup |
to scrape information from web pages. It sits atop an HTML or XML parser, providing Pythonic idioms for iterating, searching, and modifying the parse tree. |
requests |
to make a request to the website. |
lxml |
to process XML/HTML documents fast. |
json |
to convert extracted data to a JSON object. |
Create URL parameters and request headers:
# https://docs.python-requests.org/en/master/user/quickstart/#passing-parameters-in-urls
params = {
'q': 'dune film', # query
'source': 'web', # source
'tf': 'at', # publish time (by default any time)
'offset': 0 # pagination (start from page 1)
}
# https://docs.python-requests.org/en/master/user/quickstart/#custom-headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
| Code | Explanation |
|---|---|
params |
a prettier way of passing URL parameters to a request. |
user-agent |
to act as a "real" user request from the browser by passing it to request headers. Default requests user-agent is a python-reqeusts so websites might understand that it's a bot or a script and block the request to the website. Check what's your user-agent. |
Create the brave_organic_search_results list to store all data:
brave_organic_search_results = []
To scrape Brave search with pagination, you need to use the offset parameter of the URL, which defaults to 0 for the first page, 1 for the second, and so on. Since data is retrieved from all pages, it is necessary to implement a while loop:
while True:
# pagination will be here
In each iteration of the loop, you need to make a request, pass the created request parameters and headers. The request returns HTML to BeautifulSoup:
html = requests.get('https://search.brave.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
| Code | Explanation |
|---|---|
timeout=30 |
to stop waiting for response after 30 seconds. |
BeautifulSoup() |
where returned HTML data will be processed by bs4. |
After that, check the presence of the Next button. If it is present, then increase the offset parameter by one, else stop the loop:
if soup.select_one('.ml-15'):
params['offset'] += 1
else:
break
For each page, it is important to create a page dictionary. The dictionary consists of 2 keys:
-
pagecontaining the current page number. -
itemscontaining a list with all the data from the page.
page = {}
page['page'] = params['offset']
page['items'] = []
To retrieve data from all items in the page, you need to find the .snippet selector of the items. You need to iterate each item in the loop:
for result in soup.select('.snippet'):
# data extraction will be here
To extract the data, you need to find the matching selector. SelectorGadget was used to grab CSS selectors. I want to demonstrate how the selector selection process works:
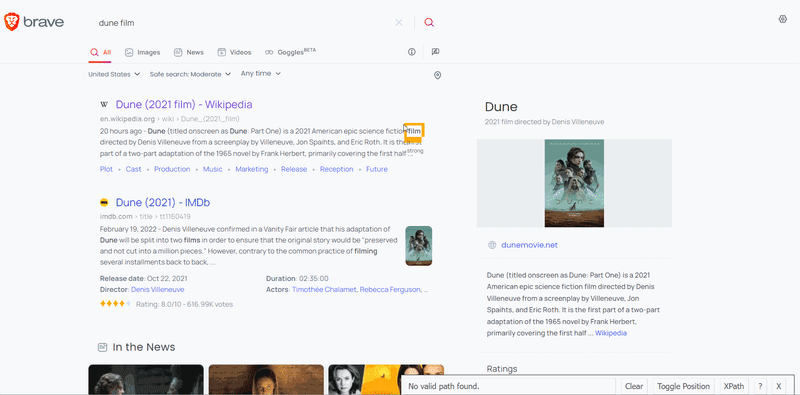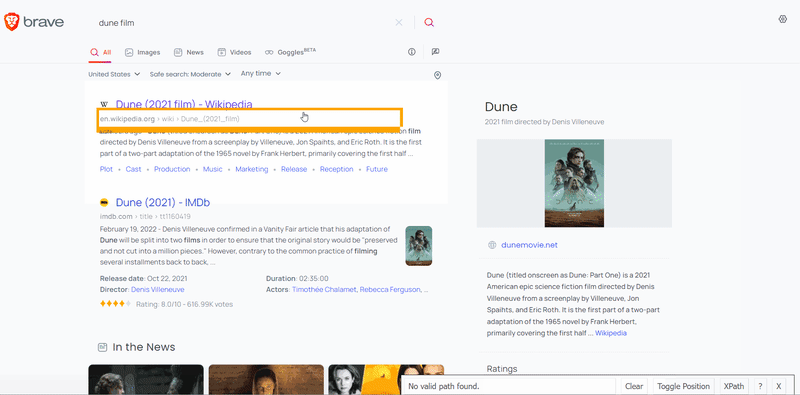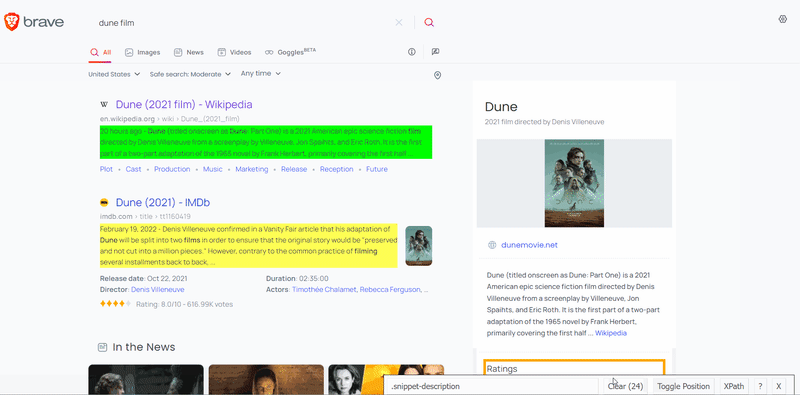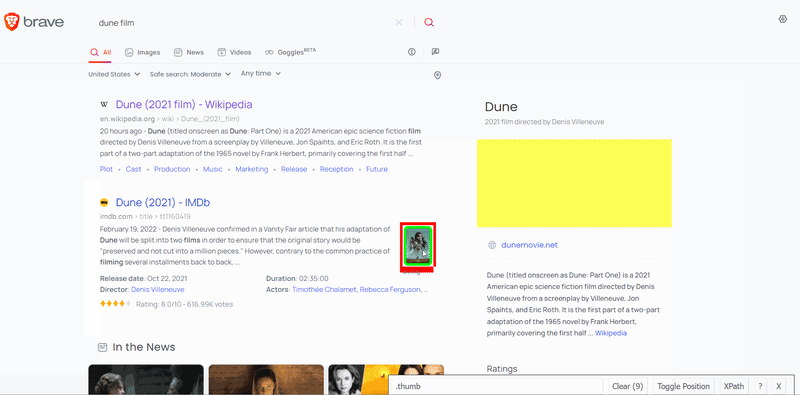
After the selectors have been found, we need to get the corresponding text or attribute value:
title = result.select_one('.snippet-title').get_text().strip()
favicon = result.select_one('.favicon').get('src')
link = result.select_one('.result-header').get('href')
displayed_link = result.select_one('.snippet-url').get_text().strip().replace('\n', '')
snippet = result.select_one('.snippet-content .snippet-description , .snippet-description:nth-child(1)').get_text()
snippet = snippet.strip().split('\n')[-1].lstrip() if snippet else None
snippet_image = result.select_one('.video-thumb img , .thumb')
snippet_image = snippet_image.get('src') if snippet_image else None
rating_and_votes = result.select_one('.ml-10')
rating = rating_and_votes.get_text().strip().split(' - ')[0] if rating_and_votes else None
votes = rating_and_votes.get_text().strip().split(' - ')[1] if rating_and_votes else None
📌Note: When extracting the snippet, snippet_image, rating and votes, a ternary expression is used which handles the value of this data, if any.
| Code | Explanation |
|---|---|
select_one()/select() |
to run a CSS selector against a parsed document and return all the matching elements. |
get_text() |
to get textual data from the node. |
get(<attribute>) |
to get attribute data from the node. |
strip() |
to return a copy of the string with the leading and trailing characters removed. |
replace() |
to replace all occurrences of the old substring with the new one without extra elements. |
split() |
to return a list of words in a string, separating the string with a delimiter string. |
lstrip() |
to return a copy of the string with leading characters removed. |
Separately, I would like to note the extraction of sitelinks, because links to sites are retrieved a little differently.
Firstly, the presence of sitelinks_container selector in the current element is checked. If they are present, then iterate over all hyperlinks.
For each sitelink we append a dictionary with the title key, where the link name will be located, and the link key, where the link itself will be located:
sitelinks_container = result.select('.deep-results-buttons .deep-link')
sitelinks = None
if sitelinks_container:
sitelinks = []
for sitelink in sitelinks_container:
sitelinks.append({
'title': sitelink.get_text().strip(),
'link': sitelink.get('href')
})
After the data from item is retrieved, it is appended to the page['items'] list:
page['items'].append({
'title': title,
'favicon': favicon,
'link': link,
'displayed_link': displayed_link,
'snippet': snippet,
'snippet_image': snippet_image,
'rating': rating,
'votes': votes,
'sitelinks': sitelinks
})
At the end of the function, the page dictionary containing the extracted data from the page is added to the brave_organic_search_results list:
brave_organic_search_results.append(page)
Output
[
{
"page": 1,
"items": [
{
"title": "Dune (2021 film) - Wikipedia",
"favicon": "https://imgs.search.brave.com/0kxnVOiqv-faZvOJc7zpym4Zin1CTs1f1svfNZSzmfU/rs:fit:32:32:1/g:ce/aHR0cDovL2Zhdmlj/b25zLnNlYXJjaC5i/cmF2ZS5jb20vaWNv/bnMvNjQwNGZhZWY0/ZTQ1YWUzYzQ3MDUw/MmMzMGY3NTQ0ZjNj/NDUwMDk5ZTI3MWRk/NWYyNTM4N2UwOTE0/NTI3ZDQzNy9lbi53/aWtpcGVkaWEub3Jn/Lw",
"link": "https://en.wikipedia.org/wiki/Dune_(2021_film)",
"displayed_link": "en.wikipedia.org› wiki › Dune_(2021_film)",
"snippet": "Dune (titled onscreen as Dune: Part One) is a 2021 American epic science fiction film directed by Denis Villeneuve from a screenplay by Villeneuve, Jon Spaihts, and Eric Roth. It is the first part of a two-part adaptation of the 1965 novel by Frank Herbert, primarily covering the first half ...",
"snippet_image": null,
"rating": null,
"votes": null,
"sitelinks": [
{
"title": "Plot",
"link": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Plot"
},
{
"title": "Cast",
"link": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Cast"
},
{
"title": "Production",
"link": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Production"
},
{
"title": "Music",
"link": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Music"
},
{
"title": "Marketing",
"link": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Marketing"
},
{
"title": "Release",
"link": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Release"
},
{
"title": "Reception",
"link": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Reception"
},
{
"title": "Future",
"link": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Future"
}
]
},
{
"title": "Dune (2021) - IMDb",
"favicon": "https://imgs.search.brave.com/_XzIkQDCEJ7aNlT3HlNUHBRcj5nQ9R4TiU4cHpSn7BY/rs:fit:32:32:1/g:ce/aHR0cDovL2Zhdmlj/b25zLnNlYXJjaC5i/cmF2ZS5jb20vaWNv/bnMvZmU3MjU1MmUz/MDhkYjY0OGFlYzY3/ZDVlMmQ4NWZjZDhh/NzZhOGZlZjNjNGE5/M2M0OWI1Y2M2ZjQy/MWE5ZDc3OC93d3cu/aW1kYi5jb20v",
"link": "https://www.imdb.com/title/tt1160419/",
"displayed_link": "imdb.com› title › tt1160419",
"snippet": "Denis Villeneuve confirmed in a Vanity Fair article that his adaptation of Dune will be split into two films in order to ensure that the original story would be \"preserved and not cut into a million pieces.\" However, contrary to the common practice of filming several installments back to back, ...",
"snippet_image": "https://imgs.search.brave.com/9pvlhzTXlafp6SkS2w9snU1BNKpci31oktK0Xte0bEI/rs:fit:200:200:1/g:ce/aHR0cHM6Ly9tLm1l/ZGlhLWFtYXpvbi5j/b20vaW1hZ2VzL00v/TVY1Qk4yRmpObUV5/TldNdFl6TTBaUzAw/TmpJeUxUZzVZell0/WVRobE1HVmpOekUx/T0dWaVhrRXlYa0Zx/Y0dkZVFYVnlNVGt4/TmpVeU5RQEAuX1Yx/Xy5qcGc",
"rating": "Rating: 8.0/10",
"votes": "616.99K votes",
"sitelinks": null
},
... other items
]
},
... other pages
{
"page": 8,
"items": [
{
"title": "Dune Part Two Release Date Pushed Forward",
"favicon": "https://imgs.search.brave.com/Ddu9qD09c99ZSYmxeBcfLo9o6889REBCPiMWloiOa7E/rs:fit:32:32:1/g:ce/aHR0cDovL2Zhdmlj/b25zLnNlYXJjaC5i/cmF2ZS5jb20vaWNv/bnMvOWY2NzdhYmY1/ZmJiOTUwYmNkNjIy/MzVkNDNhZjdmNzhm/NjQxMjExMGFhMmZl/NzgwNGQ4YzM1OGFk/OGE3YTY4My96YS5p/Z24uY29tLw",
"link": "https://za.ign.com/dune-part-two/169873/news/dune-part-two-release-date-pushed-forward",
"displayed_link": "za.ign.com › news › dune, part two",
"snippet": "Dune Part Two has already begun filming and will include new cast members like Austin Butler, Florence Pugh, and Christopher Walken. The sequel will premiere exclusively in theaters, and will not be released simultaneously on HBO Max like Dune Part One.",
"snippet_image": "https://imgs.search.brave.com/79my-ehVcHZicLodrNy6t97NONSA-T11WKG-Bh8h3Oo/rs:fit:200:200:1/g:ce/aHR0cHM6Ly9zbS5p/Z24uY29tL2lnbl96/YS9uZXdzL2QvZHVu/ZS1wYXJ0LS9kdW5l/LXBhcnQtdHdvLXJl/bGVhc2UtZGF0ZS1w/dXNoZWQtZm9yd2Fy/ZF91anozLmpwZw",
"rating": null,
"votes": null,
"sitelinks": null
},
{
"title": "Watch Dune | Prime Video",
"favicon": "https://imgs.search.brave.com/FCUnESg6bR8ppf8M-Sfl_r-lrnXkf-3FBfrX0rcFabc/rs:fit:32:32:1/g:ce/aHR0cDovL2Zhdmlj/b25zLnNlYXJjaC5i/cmF2ZS5jb20vaWNv/bnMvODYwYzA4NzE1/OTE2NzM1YTQ1OWNj/Zjg0MmI0Y2U2YzI2/ODE5NmZhNGZjODA4/N2Y0NmI1ZmU4ZWQy/ZmM2MjdmMS93d3cu/YW1hem9uLmNvbS8",
"link": "https://www.amazon.com/Dune-Timoth%C3%A9e-Chalamet/dp/B09LJT56S2",
"displayed_link": "amazon.com› Dune-Timothée-Chalamet › dp › B09LJT56S2",
"snippet": "There are three versions now of Dune, plus a \"Children of Dune\" film of one of the sequel novels. This one is by far the most faithful to the book and it's one of two so the film ends where Jessica and her son Paul Atreides are taken in by the Fremen community to begin their life as renegades ...",
"snippet_image": null,
"rating": null,
"votes": null,
"sitelinks": null
},
... other items
]
}
]
Links
Add a Feature Request💫 or a Bug🐞

Top comments (0)