
What will be scraped
Full Code
If you don't need explanation, have a look at full code example in the online IDE.
import re, json, time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from parsel import Selector
def scroll_page(url):
service = Service(ChromeDriverManager().install())
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument('--lang=en')
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36")
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)
old_height = driver.execute_script("""
function getHeight() {
return document.querySelector('ytd-app').scrollHeight;
}
return getHeight();
""")
while True:
driver.execute_script("window.scrollTo(0, document.querySelector('ytd-app').scrollHeight)")
time.sleep(2)
new_height = driver.execute_script("""
function getHeight() {
return document.querySelector('ytd-app').scrollHeight;
}
return getHeight();
""")
if new_height == old_height:
break
old_height = new_height
selector = Selector(driver.page_source)
driver.quit()
return selector
def scrape_all_data(selector):
youtube_video_page = []
all_script_tags = selector.css('script').getall()
title = selector.css(".title .ytd-video-primary-info-renderer::text").get()
# https://regex101.com/r/gHeLwZ/1
views = int(re.search(r"(.*)\s", selector.css(".view-count::text").get()).group().replace(",", ""))
# https://regex101.com/r/9OGwJp/1
likes = int(re.search(r"(.*)\s", selector.css("#top-level-buttons-computed > ytd-toggle-button-renderer:first-child #text::attr(aria-label)").get()).group().replace(",", ""))
date = selector.css("#info-strings yt-formatted-string::text").get()
duration = selector.css(".ytp-time-duration::text").get()
# https://regex101.com/r/0JNma3/1
keywords = "".join(re.findall(r'"keywords":\[(.*)\],"channelId":".*"', str(all_script_tags))).replace('\"', '').split(",")
# https://regex101.com/r/9VhH1s/1
thumbnail = re.findall(r'\[{"url":"(\S+)","width":\d*,"height":\d*},', str(all_script_tags))[0].split('",')[0]
channel = {
# https://regex101.com/r/xFUzq5/1
"id": "".join(re.findall(r'"channelId":"(.*)","isOwnerViewing"', str(all_script_tags))),
"name": selector.css("#channel-name a::text").get(),
"link": f'https://www.youtube.com{selector.css("#channel-name a::attr(href)").get()}',
"subscribers": selector.css("#owner-sub-count::text").get(),
"thumbnail": selector.css("#img::attr(src)").get(),
}
description = selector.css(".ytd-expandable-video-description-body-renderer span:nth-child(1)::text").get()
hash_tags = [
{
"name": hash_tag.css("::text").get(),
"link": f'https://www.youtube.com{hash_tag.css("::attr(href)").get()}'
}
for hash_tag in selector.css(".ytd-expandable-video-description-body-renderer a")
]
# https://regex101.com/r/onRk9j/1
category = "".join(re.findall(r'"category":"(.*)","publishDate"', str(all_script_tags)))
comments_amount = int(selector.css("#count .count-text span:nth-child(1)::text").get().replace(",", ""))
comments = []
for comment in selector.css("#contents > ytd-comment-thread-renderer"):
comments.append({
"author": comment.css("#author-text span::text").get().strip(),
"link": f'https://www.youtube.com{comment.css("#author-text::attr(href)").get()}',
"date": comment.css(".published-time-text a::text").get(),
"likes": comment.css("#vote-count-middle::text").get().strip(),
"comment": comment.css("#content-text::text").get(),
"avatar": comment.css("#author-thumbnail #img::attr(src)").get(),
})
suggested_videos = []
for video in selector.css("ytd-compact-video-renderer"):
suggested_videos.append({
"title": video.css("#video-title::text").get().strip(),
"link": f'https://www.youtube.com{video.css("#thumbnail::attr(href)").get()}',
"channel_name": video.css("#channel-name #text::text").get(),
"date": video.css("#metadata-line span:nth-child(2)::text").get(),
"views": video.css("#metadata-line span:nth-child(1)::text").get(),
"duration": video.css("#overlays #text::text").get().strip(),
"thumbnail": video.css("#thumbnail img::attr(src)").get(),
})
youtube_video_page.append({
"title": title,
"views": views,
"likes": likes,
"date": date,
"duration": duration,
"channel": channel,
"keywords": keywords,
"thumbnail": thumbnail,
"description": description,
"hash_tags": hash_tags,
"category": category,
"suggested_videos": suggested_videos,
"comments_amount": comments_amount,
"comments": comments,
})
print(json.dumps(youtube_video_page, indent=2, ensure_ascii=False))
def main():
url = "https://www.youtube.com/watch?v=fbh3OAw3VVQ"
result = scroll_page(url)
scrape_all_data(result)
if __name__ == "__main__":
main()
Preparation
Install libraries:
pip install parsel selenium webdriver webdriver_manager
Reduce the chance of being blocked
Make sure you're using request headers user-agent to act as a "real" user visit. Because default requests user-agent is python-requests and websites understand that it's most likely a script that sends a request. Check what's your user-agent.
There's a how to reduce the chance of being blocked while web scraping blog post that can get you familiar with basic and more advanced approaches.
Code Explanation
Import libraries:
import re, json, time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from parsel import Selector
| Library | Purpose |
|---|---|
re |
to extract parts of the data via regular expression. |
json |
to convert extracted data to a JSON object. |
time |
to work with time in Python. |
webdriver |
to drive a browser natively, as a user would, either locally or on a remote machine using the Selenium server. |
Service |
to manage the starting and stopping of the ChromeDriver. |
Selector |
XML/HTML parser that have full XPath and CSS selectors support. |
Top-level code environment
This code uses the generally accepted rule of using the __name__ == "__main__" construct:
def main():
url = "https://www.youtube.com/watch?v=fbh3OAw3VVQ"
result = scroll_page(url)
scrape_all_data(result)
if __name__ == "__main__":
main()
This check will only be performed if the user has run this file. If the user imports this file into another, then the check will not work.
You can watch the video Python Tutorial: if name == 'main' for more details.
Scroll page
The function takes a YouTube video page URL and returns a full HTML structure.
First, let's understand how YouTube works. YouTube is a dynamic site. The YouTube video page stores a lot of the data you saw in the what will be scraped section. Data such as comments and suggested videos does not load immediately. If the user needs more data, they will simply scroll the page and YouTube will download a small package of data. Accordingly, to get all the data, you need to scroll to the end of the page.
In this case, selenium library is used, which allows you to simulate user actions in the browser. For selenium to work, you need to use ChromeDriver, which can be downloaded manually or using code. In our case, the second method is used. To control the start and stop of ChromeDriver, you need to use Service which will install browser binaries under the hood:
service = Service(ChromeDriverManager().install())
You should also add options to work correctly:
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument('--lang=en')
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36")
| Chrome options | Explanation |
|---|---|
--headless |
to run Chrome in headless mode. |
--lang=en |
to set the browser language to English. |
user-agent |
to act as a "real" user request from the browser by passing it to request headers. Check what's your user-agent. |
Now we can start webdriver and pass the url to the get() method.
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)
The page scrolling algorithm looks like this:
- Find out the initial page height and write the result to the
old_heightvariable. - Scroll the page using the script and wait 2 seconds for the data to load.
- Find out the new page height and write the result to the
new_heightvariable. - If the variables
new_heightandold_heightare equal, then we complete the algorithm, otherwise we write the value of the variablenew_heightto the variableold_heightand return to step 2.
Getting the page height and scroll is done by pasting the JavaScript code into the execute_script() method.
old_height = driver.execute_script("""
function getHeight() {
return document.querySelector('ytd-app').scrollHeight;
}
return getHeight();
""")
while True:
driver.execute_script("window.scrollTo(0, document.querySelector('ytd-app').scrollHeight)")
time.sleep(2)
new_height = driver.execute_script("""
function getHeight() {
return document.querySelector('ytd-app').scrollHeight;
}
return getHeight();
""")
if new_height == old_height:
break
old_height = new_height
Let's use the Selector from Parsel library, in which we pass the html structure with all the data that was received after scrolling the page. This is necessary in order to successfully retrieve data in the next function. After all the operations done, stop the driver:
selector = Selector(driver.page_source)
# extracting code from HTML
driver.quit()
The function looks like this:
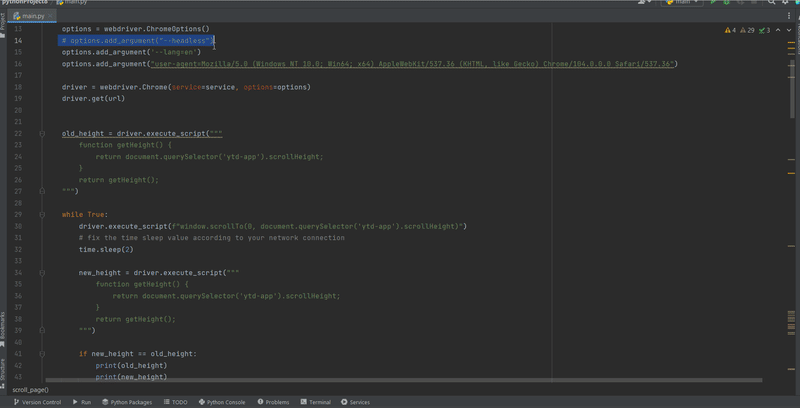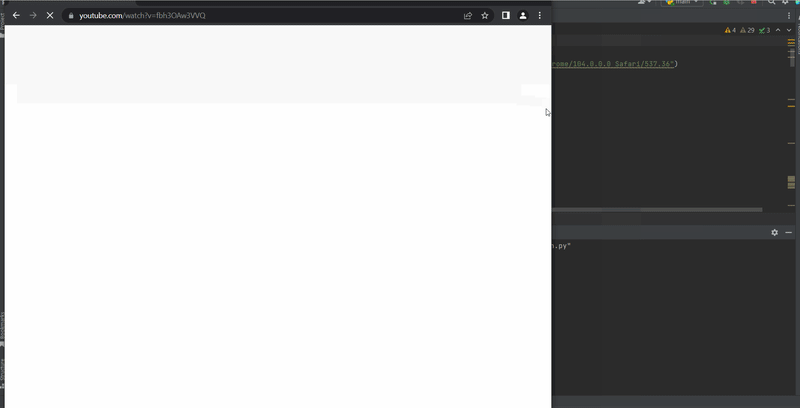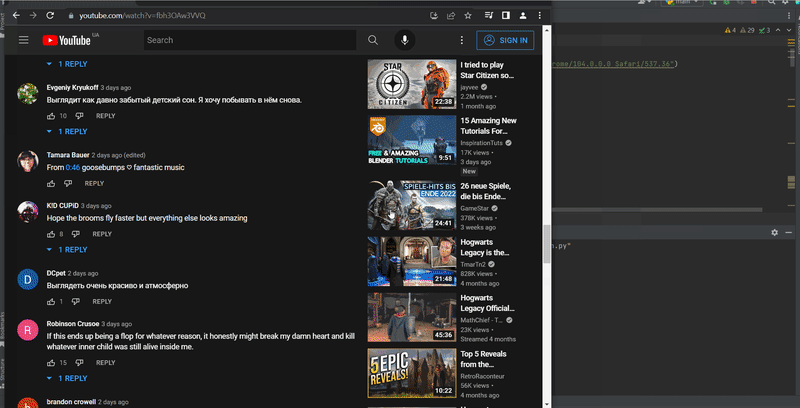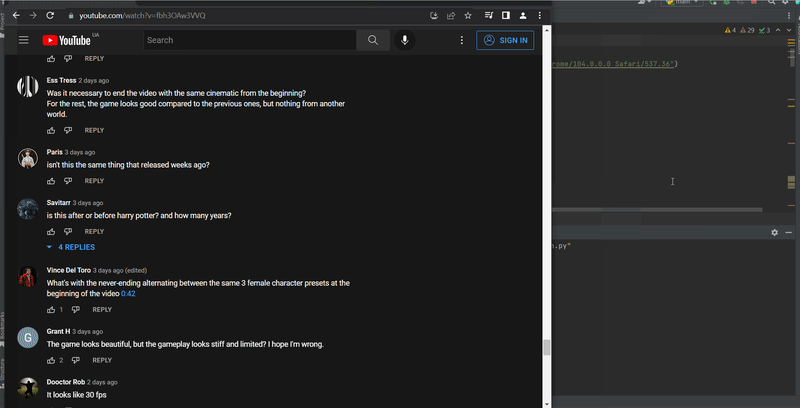
def scroll_page(url):
service = Service(ChromeDriverManager().install())
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument('--lang=en')
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36")
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)
old_height = driver.execute_script("""
function getHeight() {
return document.querySelector('ytd-app').scrollHeight;
}
return getHeight();
""")
while True:
driver.execute_script("window.scrollTo(0, document.querySelector('ytd-app').scrollHeight)")
time.sleep(2)
new_height = driver.execute_script("""
function getHeight() {
return document.querySelector('ytd-app').scrollHeight;
}
return getHeight();
""")
if new_height == old_height:
break
old_height = new_height
selector = Selector(driver.page_source)
driver.quit()
return selector
In the gif below, I demonstrate how this function works:
Scrape all data
This function takes a full HTML structure and prints all results in json format.
It should be noted that there is data that is not displayed on the YouTube video page. To extract them, you need to use regular expression and search for the <script> tags:
all_script_tags = selector.css('script').getall()
# https://regex101.com/r/0JNma3/1
keywords = "".join(re.findall(r'"keywords":\[(.*)\],"channelId":".*"', str(all_script_tags))).replace('\"', '').split(",")
# https://regex101.com/r/9VhH1s/1
thumbnail = re.findall(r'\[{"url":"(\S+)","width":\d*,"height":\d*},', str(all_script_tags))[0].split('",')[0]
channel = {
# https://regex101.com/r/xFUzq5/1
"id": "".join(re.findall(r'"channelId":"(.*)","isOwnerViewing"', str(all_script_tags))),
}
# https://regex101.com/r/onRk9j/1
category = "".join(re.findall(r'"category":"(.*)","publishDate"', str(all_script_tags)))
| Code | Explanation |
|---|---|
css() |
to access elements by the passed selector. |
getall() |
to actually extract text data from all matching objects. |
"".join() |
to concatenate a list into a string. |
replace() |
to replace all occurrences of the old substring with the new one without extra elements. |
split() |
to return a list of words in a string, separating the string with a delimiter string. |
findall() |
to find for a pattern in a string and return the list of all match objects. |
In this way, you can also extract visible data on the page. But the best way is to extract the data from the received HTML structure from the scroll_page function.
The complete function to scrape all data would look like this:
def scrape_all_data(selector):
youtube_video_page = []
all_script_tags = selector.css('script').getall()
title = selector.css(".title .ytd-video-primary-info-renderer::text").get()
# https://regex101.com/r/gHeLwZ/1
views = int(re.search(r"(.*)\s", selector.css(".view-count::text").get()).group().replace(",", ""))
# https://regex101.com/r/9OGwJp/1
likes = int(re.search(r"(.*)\s", selector.css("#top-level-buttons-computed > ytd-toggle-button-renderer:first-child #text::attr(aria-label)").get()).group().replace(",", ""))
date = selector.css("#info-strings yt-formatted-string::text").get()
duration = selector.css(".ytp-time-duration::text").get()
# https://regex101.com/r/0JNma3/1
keywords = "".join(re.findall(r'"keywords":\[(.*)\],"channelId":".*"', str(all_script_tags))).replace('\"', '').split(",")
# https://regex101.com/r/9VhH1s/1
thumbnail = re.findall(r'\[{"url":"(\S+)","width":\d*,"height":\d*},', str(all_script_tags))[0].split('",')[0]
channel = {
# https://regex101.com/r/xFUzq5/1
"id": "".join(re.findall(r'"channelId":"(.*)","isOwnerViewing"', str(all_script_tags))),
"name": selector.css("#channel-name a::text").get(),
"link": f'https://www.youtube.com{selector.css("#channel-name a::attr(href)").get()}',
"subscribers": selector.css("#owner-sub-count::text").get(),
"thumbnail": selector.css("#img::attr(src)").get(),
}
description = selector.css(".ytd-expandable-video-description-body-renderer span:nth-child(1)::text").get()
hashtags = [
{
"name": hash_tag.css("::text").get(),
"link": f'https://www.youtube.com{hash_tag.css("::attr(href)").get()}'
}
for hash_tag in selector.css(".ytd-expandable-video-description-body-renderer a")
if hash_tag.css("::text").get()[0] == '#'
]
# https://regex101.com/r/onRk9j/1
category = "".join(re.findall(r'"category":"(.*)","publishDate"', str(all_script_tags)))
comments_amount = int(selector.css("#count .count-text span:nth-child(1)::text").get().replace(",", ""))
comments = []
for comment in selector.css("#contents > ytd-comment-thread-renderer"):
comments.append({
"author": comment.css("#author-text span::text").get().strip(),
"link": f'https://www.youtube.com{comment.css("#author-text::attr(href)").get()}',
"date": comment.css(".published-time-text a::text").get(),
"likes": comment.css("#vote-count-middle::text").get().strip(),
"comment": comment.css("#content-text::text").get(),
"avatar": comment.css("#author-thumbnail #img::attr(src)").get(),
})
suggested_videos = []
for video in selector.css("ytd-compact-video-renderer"):
suggested_videos.append({
"title": video.css("#video-title::text").get().strip(),
"link": f'https://www.youtube.com{video.css("#thumbnail::attr(href)").get()}',
"channel_name": video.css("#channel-name #text::text").get(),
"date": video.css("#metadata-line span:nth-child(2)::text").get(),
"views": video.css("#metadata-line span:nth-child(1)::text").get(),
"duration": video.css("#overlays #text::text").get().strip(),
"thumbnail": video.css("#thumbnail img::attr(src)").get(),
})
youtube_video_page.append({
"title": title,
"views": views,
"likes": likes,
"date": date,
"duration": duration,
"channel": channel,
"keywords": keywords,
"thumbnail": thumbnail,
"description": description,
"hashtags": hashtags,
"category": category,
"suggested_videos": suggested_videos,
"comments_amount": comments_amount,
"comments": comments,
})
print(json.dumps(youtube_video_page, indent=2, ensure_ascii=False))
| Code | Explanation |
|---|---|
youtube_video_page |
a temporary list where extracted data will be appended at the end of the function. |
css() |
to access elements by the passed selector. |
::text or ::attr(<attribute>) |
to extract textual or attribute data from the node. |
get() |
to actually extract the textual data. |
search() |
to search for a pattern in a string and return the corresponding match object. |
group() |
to extract the found element from the match object. |
youtube_video_page.append({}) |
to append extracted data to a list as a dictionary. |
strip() |
to return a copy of the string with the leading and trailing characters removed. |
Output
[
{
"title": "Hogwarts Legacy 8 Minutes Exclusive Gameplay (Unreal Engine 4K 60FPS HDR)",
"views": 215244,
"likes": 2632,
"date": "Aug 5, 2022",
"duration": "8:20",
"channel": {
"id": "UCAvRtPIFFbnfLHswfRS6zhQ",
"name": "GameV",
"link": "https://www.youtube.com/c/GameV",
"subscribers": "55.5K subscribers",
"thumbnail": "https://yt3.ggpht.com/ytc/AMLnZu-8W0taSvZWdVQXoqge6XSLmhk39jns9e7S-zjLQA=s48-c-k-c0x00ffffff-no-rj"
},
"keywords": [
"hogwarts legacy",
"hogwarts legacy gameplay",
"hogwarts legacy gameplay trailer",
... other keywords
],
"thumbnail": "https://i.ytimg.com/vi/fbh3OAw3VVQ/hqdefault.jpg?sqp=-oaymwEbCKgBEF5IVfKriqkDDggBFQAAiEIYAXABwAEG\\\\u0026rs=AOn4CLCucgyCMVC9CvMdz2vULM4FQZI3GQ",
"description": "Hogwarts Legacy 8 Minutes Exclusive Gameplay (Unreal Engine 4K 60FPS HDR)\n\nHogwarts Legacy is an upcoming action role-playing video game developed by Avalanche Software and published by Warner Bros. Interactive Entertainment under its Portkey Games label, using Unreal Engine. It is set in the Wizarding World universe, based on the Harry Potter novel and film series and Fantastic Beasts. The game is set to be released in late 2022 for Microsoft Windows, Nintendo Switch, PlayStation 4, PlayStation 5, Xbox One, and Xbox Series X/S\n\n",
"hashtags": [
{
"name": "#hogwartslegacy",
"link": "https://www.youtube.com/hashtag/hogwartslegacy"
},
... other hashtags
],
"category": "Gaming",
"suggested_videos": [
{
"title": "The Story of Hogwarts Legacy Is Crazy..",
"link": "https://www.youtube.com/watch?v=_WW2VauR968",
"channel_name": "WolfheartFPS",
"date": "2 days ago",
"views": "6K views",
"duration": "16:44",
"thumbnail": "https://i.ytimg.com/vi/_WW2VauR968/hqdefault.jpg?sqp=-oaymwEbCKgBEF5IVfKriqkDDggBFQAAiEIYAXABwAEG&rs=AOn4CLDTi3OShNy4DTW21bC6IQfAPc-DCw"
},
... other videos
],
"comments_amount": 359,
"comments": [
{
"author": "Aaron",
"link": "https://www.youtube.com/channel/UCCsQ_qXy5oM0pbGI1Az0aGA",
"date": "1 day ago (edited)",
"likes": "101",
"comment": "Particle effects on contact look crazy. There's clearly a lot of detail in this game. I just hope the gameplay isn't stale. One thing I noticed is the enemies seem kind of dumb just standing around during combat. Maybe there is a difficulty setting that will change that.",
"avatar": "https://yt3.ggpht.com/ytc/AMLnZu8phDhzI_6ncZ7bh7sWBcti3np2xgdrTSNqqoBw_w=s48-c-k-c0x00ffffff-no-rj"
},
... other comments
]
}
]
Add a Feature Request💫 or a Bug🐞

Top comments (0)