
Intro
This Python demo project is a practical showcase of using SerpApi's Walmart Search Engine Results API plus how extracted data could be used in exploratory data analysis.
SerpApi is an API that let's you receive structured JSON data from 26 search engines in 10 programming languages.
You can explore this project on your own that is available on GitHub: dimitryzub/walmart-stores-coffee-analysis
We'll cover:
- Extracting data from Walmart Organic results.
- Extracting data from all store pages using SerpApi pagination.
- Extracting data from 500 Walmart stores. SerpApi provides JSON Walmart Stores Locations with 4.460 stores in total.
- My full process of exploratory data analysis.
📌Note: the following script extracts data in a sync fashion, which is slower.
SerpApi provides async parameter that allows processing a lot more results without waiting for SerpApi response. Those results will be processed at the SerpApi backend and can be retrieved in up to 31 days.
If you're interested in extracting decent amounts of data (10.000+ requests) that take less than 5 hours, sign up for our blog so you don't miss it.
Extracting Walmart Data
Explanation
First, we need to install libraries:
$ pip install pandas matplotlib seaborn jinja2 google-search-results
| Library | Purpose |
|---|---|
pandas |
Powerful data analysis manipulation tool. |
matplotlib |
Matplotlib is a comprehensive Python library for visualizing data. |
seaborn |
A high-level interface that built on top of matplotlib for drawing attractive and informative statistical graphics. |
jinja2 |
Python template engine. Used for pandas table viz. |
google-search-results |
SerpApi Python API wrapper. |
Secondly, we need to import libraries
from serpapi import WalmartSearch
from urllib.parse import (parse_qsl, urlsplit)
import pandas as pd
import os, re, json
| Library | Purpose |
|---|---|
urllib.parse |
For SerpApi pagination purposes. |
os |
To read secret API key. Don't show your API key publicly. |
re |
To extract parts of the data from a string. |
json |
For the most part for pretty-printing. |
Next, we read Walmart Stores JSON file:
# to get store ID
store_ids = pd.read_json('<path_to>/walmart-stores.json')
Next, we create a constant variable of coffee types. This will be used to check the coffee type later from the listing's title:
COFFEE_TYPES = [
'Espresso',
'...',
'Black Ivory Coffee'
]
After that, we're iterating over store_ids and passing store id to store_id SerpApi query paramater:
for store_id in store_ids['store_id']:
params = {
'api_key': os.getenv('API_KEY'), # serpapi api key
'engine': 'walmart', # search engine
'device': 'desktop', # device type
'query': 'coffee', # search query
'store_id': store_id
}
search = WalmartSearch(params) # where data extraction happens
In the next step, we need to create a list where extracted data will be temporarily stored, and create a page number counter for demonstration purposes only:
data = []
page_num = 0
Next step would be to create a while loop which will iterate over all store pages:
while True:
results = search.get_json() # JSON -> Python dict
After that, we need to check if there're any errors returned from SerpApi, and break if any:
if results['search_information']['organic_results_state'] == 'Fully empty':
print(results['error'])
break
Increment a page counter and print it:
page_num += 1
print(f'Current page: {page_num}')
After that, we need to extract data and standardize it as much as possible:
for result in results.get('organic_results', []):
title = result.get('title').lower()
# https://regex101.com/r/h0jTPG/1
try:
weight = re.search(r'(\d+-[Ounce|ounce]+|\d{1,3}\.?\d{1,2}[\s|-]?[ounce|oz]+)', title).group(1)
except: weight = 'not mentioned'
# ounce -> grams
# formula: https://www.omnicalculator.com/conversion/g-to-oz#how-to-convert-grams-to-ounces
# https://regex101.com/r/wWMUQd/1
if weight != 'not mentioned':
weight_formatted_to_gramms = round(float(re.sub(r'[^\d.]+', '', weight)) * 28.34952/1, 1)
# loop through COFFEE_TYPES and checks if result.title has coffee type
# found match or matches will be stored as a list with ',' separator
coffee_type = ','.join([i for i in COFFEE_TYPES if i.lower() in title])
After that, we need to append the data to temporary list:
data.append({
'title': title,
'coffee_type': coffee_type.lower(),
'rating': result.get('rating'),
'reviews': result.get('reviews'),
'seller_name': result.get('seller_name').lower() if result.get('seller_name') else result.get('seller_name'),
'thumbnail': result.get('thumbnail'),
'price': result.get('primary_offer').get('offer_price'),
'weight': weight,
'weight_formatted_to_gramms': weight_formatted_to_gramms
})
And then check if there's next page in serpapi_pagination hash key and paginate, otherwise break the while loop:
# check if the next page key is present in the JSON
# if present -> split URL in parts and update to the next page
if 'next' in results.get('serpapi_pagination', {}):
search.params_dict.update(dict(parse_qsl(urlsplit(results.get('serpapi_pagination', {}).get('next')).query)))
else:
break
And finally, after all looping done, we need to save data. I choose JSON and CSV with pandas to_csv and to_json methods:
pd.DataFrame(data=data).to_json('coffee-listings-from-all-walmart-stores.json', orient='records')
pd.DataFrame(data=data).to_csv('coffee-listings-from-all-walmart-stores.csv', index=False)
Full code
There's also a code example in the online IDE (Replit) so you can play around:
from serpapi import WalmartSearch
from urllib.parse import (parse_qsl, urlsplit)
import pandas as pd
import os, re, json
store_ids = pd.read_json('<path_to>/walmart-stores.json')
COFFEE_TYPES = [
'Espresso',
'Double Espresso',
'Red Eye',
'caramel flavored',
'caramel',
'colombian',
'french',
'italian',
'Black Eye',
'Americano',
'Long Black',
'Macchiato',
'Long Macchiato',
'Cortado',
'Breve',
'Cappuccino',
'Flat White',
'Cafe Latte',
'Mocha',
'Vienna',
'Affogato',
'gourmet coffee',
'Cafe au Lait',
'Iced Coffee',
'Drip Coffee',
'French Press',
'Cold Brew Coffee',
'Pour Over Coffee',
'Cowboy Coffee',
'Turkish Coffee',
'Percolated Coffee',
'Infused Coffee',
'Vacuum Coffee',
'Moka Pot Coffee',
'Espresso Coffee',
'Antoccino',
'Cafe Bombon',
'Latte',
'City roast',
'American roast',
'Half City roast',
'New England roast',
'Light City roast',
'Blonde roast',
'Cinnamon roast',
'Breakfast roast',
'Full City roast',
'Continental roast',
'High roast',
'New Orleans roast',
'Espresso roast',
'Viennese roast',
'European roast',
'French roast',
'Italian roast',
'Galao',
'Caffe Americano',
'Cafe Cubano',
'Cafe Zorro',
'Doppio',
'Espresso Romano',
'Guillermo',
'Ristretto',
'Cafe au lait ',
'Coffee with Espresso',
'Dead eye',
'Botz',
'Nitro Coffee',
'Bulletproof Coffee',
'Black tie',
'Red tie',
'Dirty chai latte',
'Yuenyeung',
"Bailey's Irish Cream and Coffee",
'Caffè Corretto',
'Rüdesheimer Kaffee',
'Pharisee',
'Barraquito',
'Carajillo',
'Irish coffee',
'Melya',
'Espressino',
'Caffè Marocchino',
'Café miel',
'Cafe Borgia',
'Café de olla',
'Café Rápido y Sucio',
'Coffee with a flavor shot',
'Caffè Medici',
'Egg coffee',
'Kopi susu',
'Vienna Coffee',
'Iced lattes',
'Iced mochas',
'Ca phe sua da',
'Eiskaffee',
'Frappé',
'Freddo Espresso',
'Freddo Cappuccino',
'Mazagran',
'Palazzo',
'Ice Shot',
'Shakerato',
'Instant Coffee',
'Canned Coffee',
'Coffee Milk',
'South Indian Coffee',
'Pocillo',
'Arabica',
'Robusta Beans',
'Liberica Beans',
'Excelsa Beans',
'White Roast Coffee',
'Light Roast',
'Medium Roast',
'Medium-Dark Roast',
'medium dark',
'medium dark roast',
'Classic Roast',
'black silk ground coffee',
'black rifle coffee',
'Dark Roast',
'Kopi Luwak Coffee',
'Jacu Bird Coffee',
'Black Ivory Coffee'
]
for store_id in store_ids['store_id']:
params = {
'api_key': os.getenv('API_KEY'), # serpapi api key
'engine': 'walmart', # search engine
'device': 'desktop', # device type
'query': 'coffee', # search query
'store_id': store_id
}
search = WalmartSearch(params) # where data extraction happens
print(params) # just to show the progress
data = []
page_num = 0
while True:
results = search.get_json() # JSON -> Python dict
if results['search_information']['organic_results_state'] == 'Fully empty':
print(results['error'])
break
page_num += 1
print(f'Current page: {page_num}')
for result in results.get('organic_results', []):
title = result.get('title').lower() if result.get('title') else result.get('title')
# https://regex101.com/r/h0jTPG/1
try:
weight = re.search(r'(\d+-[Ounce|ounce]+|\d{1,3}\.?\d{1,2}[\s|-]?[ounce|oz]+)', title).group(1)
except: weight = 'not mentioned'
# ounce -> grams
# formula: https://www.omnicalculator.com/conversion/g-to-oz#how-to-convert-grams-to-ounces
# https://regex101.com/r/wWMUQd/1
if weight != 'not mentioned':
weight_formatted_to_gramms = round(float(re.sub(r'[^\d.]+', "", weight)) * 28.34952/1, 1)
coffee_type = ",".join([i for i in COFFEE_TYPES if i.lower() in title])
data.append({
'title': title,
'coffee_type': coffee_type.lower(),
'rating': result.get('rating'),
'reviews': result.get('reviews'),
'seller_name': result.get('seller_name').lower() if result.get('seller_name') else result.get('seller_name'),
'thumbnail': result.get('thumbnail'),
'price': result.get('primary_offer').get('offer_price'),
'weight': weight,
'weight_formatted_to_gramms': weight_formatted_to_gramms
})
# check if the next page key is present in the JSON
# if present -> split URL in parts and update to the next page
if 'next' in results.get('serpapi_pagination', {}):
search.params_dict.update(dict(parse_qsl(urlsplit(results.get('serpapi_pagination', {}).get('next')).query)))
else:
break
pd.DataFrame(data=data).to_json('coffee-listings-from-all-walmart-stores.json', orient='records')
pd.DataFrame(data=data).to_csv('coffee-listings-from-all-walmart-stores.csv', index=False)
Exploratory Analysis
Key Takeaways
- The Most popular coffee seller is Walmart.
- The Most popular coffee type is medium roast.
- More weight (grams) doesn't equal higher price.
- A lower gram coffee may cost more than a higher gram coffee.
- The Highest coffee weight is 2835 grams (2.8 kg).
- "Folgers classic roast ground coffee" has 15k+ reviews which is the maximum value from data set.
- ~300-500 grams is the most frequent weight.
- The Highest coffee price is $77 (Lavazza perfetto single-serve k-cup)
Questions to Answer
I wrote those questions at the beginning of the exploration to track their progress. Keep in mind that those questions only reflect my personal interest.
- What coffee title has the most reviews?
- What coffee title has the most rating?
- What is the most popular seller?
- What coffee title has the highest/lowest price?
- What is the sum weight in grams?
- What coffee title has the highest/lowest weight (grams)?
- What is the most popular coffee type?
- Most frequent coffee grams?
- What is the sum weight in grams?
- Higher weight (grams) = bigger price?
- Lower weight (grams) = lower price?
Process
Install libraries and tell matplotlib to plot inline (inside notebook) with the help of % magic functions which sets the backend of matplotlib to the inline backend:
%pip install pandas matplotlib seaborn jinja2 # install libraries
%matplotlib inline
Next, we import pandas and read_csv() that was earlier extracted using Walmart Search Engine Results API from SerpApi:
import pandas as pd
coffee_df = pd.read_csv('/workspace/serpapi-demo-projects/walmart-coffee-analysis/data/coffee-listings-from-all-walmart-stores.csv')
coffee_df.head()

Now I wanted to check the overall info about the DataFrame. Here I was looking at Dtype of each column and if it's correct:
coffee_df.info()
Outputs:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1400 entries, 0 to 1399
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 1400 non-null object
1 coffee_type 1121 non-null object
2 rating 1400 non-null float64
3 reviews 1400 non-null int64
4 seller_name 1400 non-null object
5 thumbnail 1400 non-null object
6 price 1400 non-null float64
7 weight 1400 non-null object
8 weight_formatted_to_gramms 1400 non-null float64
dtypes: float64(3), int64(1), object(5)
memory usage: 98.6+ KB
Next I want to see the overall numeric info, such as mean, min, max values and if they make sense:
coffee_df.describe()

coffee_df.shape
# (1400, 9)
Here I wanted to take a quick glance at correlation between numeric columns using DataFrame.corr():
import seaborn as sns
import matplotlib as plt
ax = sns.heatmap(coffee_df.corr(numeric_only=True), annot=True, cmap='Blues')
ax.set_title('Correlation between variables')
Here we can see a very slight correlation between weight of the coffee and its price which pretty logical:

What coffee title has the most reviews?
Answer: folgers classic roast ground coffee, medium ro... / 15148 reviews
What coffee title has the most rating?
Answer: community coffee caf special decaf medium-dark roast coffee single-serve cups 36 ct box compatible with keurig 2.0 k-cup brewers / rating of 5 and 108 reviews
coffee_df.query('reviews == reviews.max()')[['title', 'reviews']]

coffee_df.query('rating == rating.max()')[['title', 'rating', 'reviews']].sort_values(
by='reviews', ascending=False
).style.hide(axis='index').background_gradient(cmap='Blues')
What is the most popular seller?
Answer: Walmart
plt.title('Most Popular Coffee Seller on Walmart')
# value_counts() to count how many times each seller is repeated
# head() display only top 10
# sort_values() to sort from highest to lowest
# and plot the data
ax = coffee_df['seller_name'].value_counts().head(10).sort_values().plot(kind='barh', figsize=(13,5))
ax.bar_label(ax.containers[0])
plt.xlabel('Number of listings')
plt.show()

What is the sum weight in grams?
Answer: 869948.5 grams which is 870 kilograms 🤓
# sum of the all grams
grams = coffee_df['weight_formatted_to_gramms'].sum()
kilorgrams = round(coffee_df['weight_formatted_to_gramms'].sum() / 1000)
print(f'Grams: {grams}\nKilograms: {kilorgrams}')
Grams: 869948.5
Kilograms: 870
What coffee title has the highest/lowest price?
Answer highest: lavazza perfetto single-serve k-cup® pods for keurig brewer, dark roast, 10-ct boxes (pack of 6) / price $77.09
Answer lowest:
- folgers classic roast instant coffee, single serve packets / price $1
- classic decaf instant coffee crystals packets, 6 count / price $1
Highest price
# https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.query.html
coffee_df.query('price == price.max()')[['title', 'price']]
| title | price | |
|---|---|---|
| 1275 | lavazza perfetto single-serve k-cup® pods for ... | 77.09 |
Lowest price
- folgers classic roast instant coffee, single serve packets / price $1
- folgers classic decaf instant coffee crystals packets, 6 count / price $1
# condition with .min() won't work: coffee_df.loc[(coffee_df['price'] != 0) & (coffee_df['price'].min()), ['price']]
# != 0 to exclude 0 values
coffee_df.loc[(coffee_df['price'] != 0) & (coffee_df['price'] < 1.1), ['title', 'price']]
| title | price | |
|---|---|---|
| 1109 | folgers classic roast instant coffee, single s... | 1.0 |
| 1304 | folgers classic decaf instant coffee crystals ... | 1.0 |
What coffee title has the highest/lowest weight (grams)?
Answer highest:
| Title | Answer |
|---|---|
| victor allen's coffee variety pack, 100 count, single serve coffee pods for keurig k-cup brewers | 2835.0 grams |
| eight o'clock the original medium roast k-cup coffee pods, 100 ct | 2835.0 grams |
| royal kona coffee for royalty chocolate macadamia nut, 10% kona coffee blend, all purpose grind | 2835.0 grams |
Answer lowest:
| Title | Answer |
|---|---|
| great value classic roast ground coffee pods, 0.31 oz, 48 count | 8.8 gram |
| great value classic roast ground coffee pods, 0.31 oz, 12 count | 8.8 gram |
| great value classic roast ground coffee pods, 0.31 oz, 96 count | 8.8 gram |
Highest Weight
coffee_df.query('weight_formatted_to_gramms == weight_formatted_to_gramms.max()')[
['title', 'weight_formatted_to_gramms']
]
| title | weight_formatted_to_gramms | |
|---|---|---|
| 334 | victor allen's coffee variety pack, 100 count,... | 2835.0 |
| 986 | eight o'clock the original medium roast k-cup ... | 2835.0 |
| 987 | royal kona coffee for royalty chocolate macada... | 2835.0 |
Lowest Weight
There are 7 indexes with 0.0 values due to not correctly extracted data.
coffee_df.query('weight_formatted_to_gramms == weight_formatted_to_gramms.min()')[
'weight_formatted_to_gramms'
]
Outputs:
305 0.0
425 0.0
703 0.0
890 0.0
957 0.0
991 0.0
1188 0.0
Name: weight_formatted_to_gramms, dtype: float64
I've decided to check weight that doesn't equal 0 and weight doesn't higher than 10 grams:
coffee_df.loc[
(coffee_df['weight_formatted_to_gramms'] != 0.0)
& (coffee_df['weight_formatted_to_gramms'] < 10),
['title', 'weight_formatted_to_gramms'],
]
| title | weight_formatted_to_gramms | |
|---|---|---|
| 227 | great value classic roast ground coffee pods, ... | 8.8 |
| 289 | great value classic roast ground coffee pods, ... | 8.8 |
| 1317 | great value classic roast ground coffee pods, ... | 8.8 |
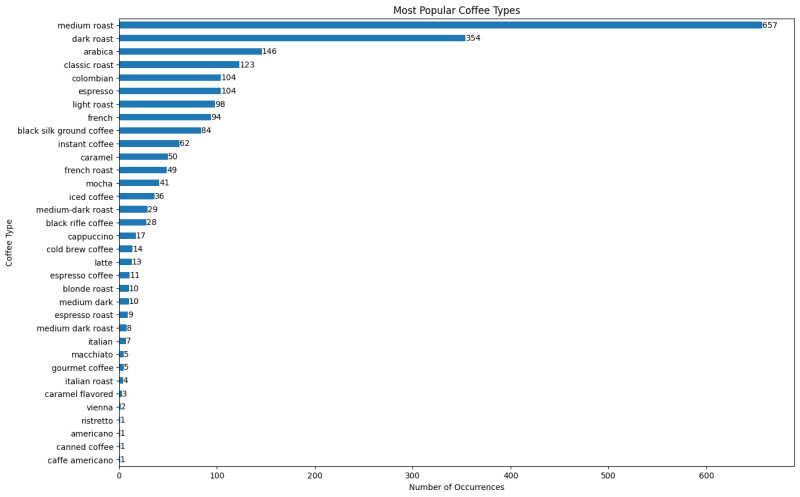
What is the most popular coffee type?
Answer (Top 3):
- Medium Roast
- Dark Roast
- Arabica
📌Note: There're 125 different types of coffee and some of them could be missing.
Take a look at COFFEE_TYPES list under extraction.py
Split coffee types and extend them to a new list
# https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.fillna.html
coffee_types = coffee_df['coffee_type'].fillna(method='ffill') # fill with None
coffee_types_new = []
# split by comma and extend the new list with split values
# https://stackoverflow.com/a/27886807/15164646
for coffee_type in coffee_types:
coffee_types_new.extend(coffee_type.split(','))
Get the most frequent coffee type
coffee_types_new_series = pd.Series(coffee_types_new).dropna()
plt.title('Most Popular Coffee Types')
ax = coffee_types_new_series.value_counts().sort_values(ascending=True).plot(kind='barh', figsize=(15,10))
ax.bar_label(ax.containers[0]) # bar annotation
plt.ylabel('Coffee Type')
plt.xlabel('Number of Occurrences')
plt.show()
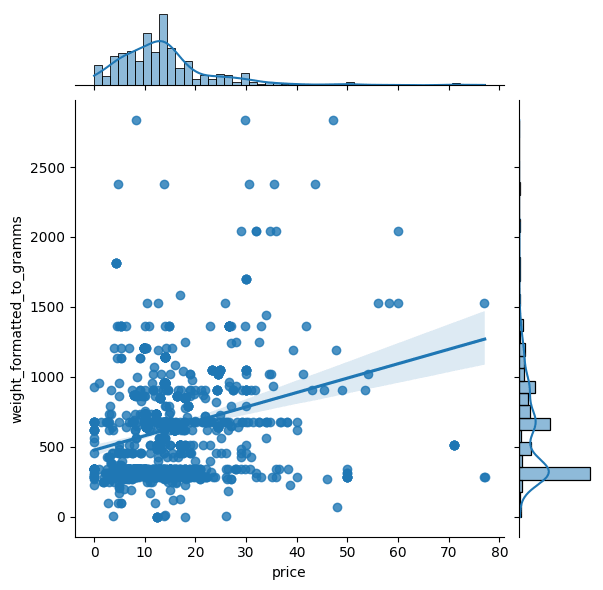
Most frequent coffee weight?
Answer: ~300-500 grams
sns.jointplot(data=coffee_df, x='price', y='weight_formatted_to_gramms', kind='hex')

Additional Plots
g = sns.PairGrid(coffee_df[['price', 'weight_formatted_to_gramms']], height=4)
g.map_upper(sns.histplot)
g.map_lower(sns.kdeplot, fill=True)
g.map_diag(sns.histplot, kde=True)

sns.displot(
coffee_df,
x='price',
y='weight_formatted_to_gramms',
kind='kde',
fill=True,
thresh=0,
levels=100,
cmap='mako',
)

Higher weight (grams) = bigger price?
Answer: with this dataset it depends.
Lower weight (grams) = lower price?
Answer: with this dataset it depends.
sns.jointplot(data=coffee_df, x='price', y='weight_formatted_to_gramms', kind='reg')
ax = sns.scatterplot(
data=coffee_df,
x='price',
y='weight_formatted_to_gramms',
hue='price',
size='price',
sizes=(40, 300),
)
# https://stackoverflow.com/a/34579525/15164646
sns.move_legend(ax, 'upper left', bbox_to_anchor=(1, 1.02)) # 1 = X axis, 1.02 = Y axis of the legend.

Conclusion
In this blog post we've covered:
- Walmart Engine Results API.
- JSON of Walmart Store Locations.
- SerpApi Pagination.
- Exploratory data analysis with
pandas,matplotlibandseaborn.- Grouping
- Sorting
- Plotting
Add a Feature Request💫 or a Bug🐞





Top comments (0)